-
-

Me @ Linux Foundation Open Platform for Enterprise AI May 2024 @ Intel in Oregon
-
my openvino worker
-
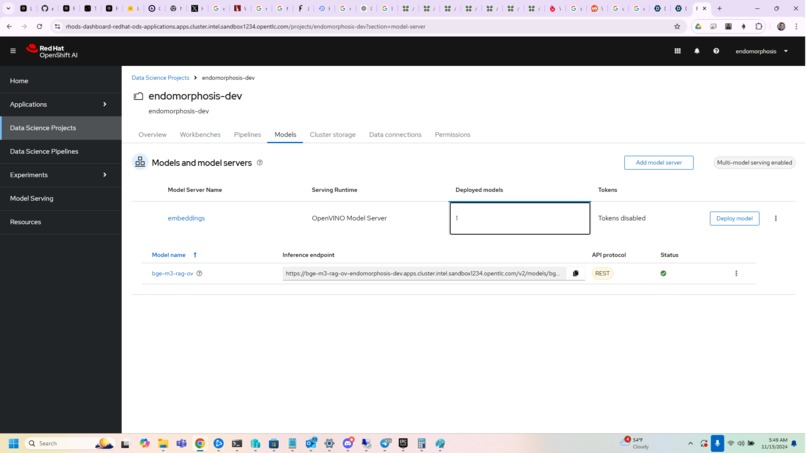
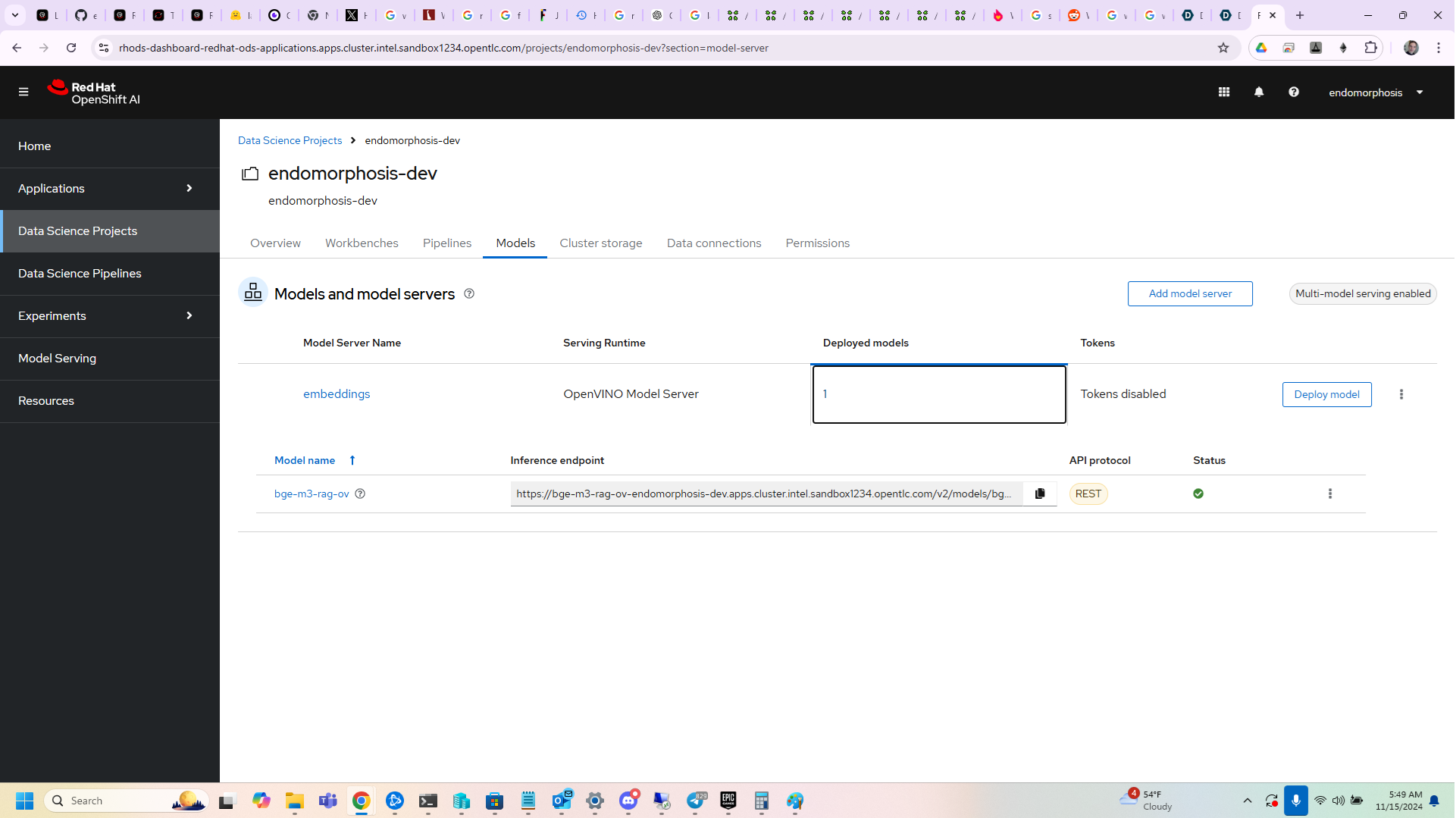
openvino model server

Inspiration
I have been working on an end to end mlops framework for 8 months, and I had some discussion with the OPEA linux foundation group and emails with Brian Behlendorf about an edge focused mlops architecture, which is based on extending the features of the huggingface libraries, to include ipfs (interplanetary file system) and libp2p as the networking layer and webnn (web neural network) so that it optimizes network latency and allows for multi-agent swarm processing. The plan is to start with python libraries and eventually translate that into nodejs, and will eventually migrate the nodejs to clientside javascript and web neural networks
For this part of the project, I've been building a "model manager" and "huggingface scraper" that contains the file hashes on the ipfs network that hold the files from the git repository, information from config.json and some hardware profiling data, but I realized that I needed to have a way for the huggingface agent library to decide what models it make calls to, by creating a graphrag system to decide to retrieve the metadata for repositories, and put them into the LLMs "toolbox", then develop a reward model that jointly trains the embedding model and the LM to properly route to the right repository to use as a tool.
What it does
I ran as a demo the 6 million rows from the Caselaw Access Project, and decided that I wanted to use 3 different embedding models, to collect embeddings in parallel from multiple endpoints.
Using the process a row, i take the entire row and hash it with the "multiformats" ipfs hashing library to get the "content id", and send it to the endpoint manager which puts it into a "model queue", then items are pulled out of the model queue and put into an endpoint queue, and then after inference is done the results are put in a cache, and the results from the cache are returned to the embedding library, which then is saved to disk once an hour. The embedding module also splits documents into chunks using both sliding window and semantic splitting, and creates embeddings and ipfs content id's for the document chunks, in addition to being able to embed documents with up to 32k tokens context length.
The endpoints are either added at initialization or during runtime using the Fastapi, and the supported endpoint types are the openvino model server, the huggingface TEI / TGI server, vLLM, ollama, and local endpoints that will be instantiated after a hardware test, that include openvino, cuda, and IPEX llm compatibility. The local endpoints support batched inference (upto the memory limit or 4096 items per batch), which is something that the openvino model server does not support. The other advantage is that using s3 buckets and doing model conversion is not necessary, the user provides the huggingface repository ID, and the package loads it into huggingface transformers, and converts it to openvino automatically for the user.
Once all of the embeddings have been processed, the embedding library collects them all, and then does a K means clustering using FAISS for 100 iterations on the embeddings done with the model with the highest dimensions, and assigns clusters to the content IDs. The number of clusters is determined by powers of 64, as long as no cluster has more than 4096 members and no larger than 50MB, Then I parse through the entire embeddings checkpoints to assign each of the embeddings into a cluster.
The embedding library will ingest those into Qdrant, and accept queries made from Qdrant on the server side, but part of the reason for K means clustering the embeddings, is so that the client can search over the data by first doing K nearest neighbors search of the query vector to the cluster centroids it has downloaded, then downloading the single cluster and doing a k nearest neighbors search of the retrieved cluster, and from that cluster refining those 4096 examples to get candidate documents, and then retrieving all of the chunks from those documents and doing a vector search of those chunks.
KNN search endpoint
curl 37.27.128.150:9999/search -X POST -d '{"text":"orange juice", "collection": "English-ConcatX-Abstract", "n":10}' -H 'Content-Type: application/json'
What's next for parallel synthetic data generator and endpoint demultiplexer
I have not yet finished the FAISS vector quantization, as I decided to make a model server in addition, due to the numerous help requests by fellow participants, and identifying that as a developer pain point that needed remedying. I still need to scrape all of the readme.md, config.json, and github metadata from huggingface, but i will process embeddings for that, so that I can use huggingface agents to retrieve items for its "toolbox", and add some code to make a graphrag database of the contents of the ipfs cluster. I am also waiting for the AMX branch of FAISS to finish the continuous integration tests, because there is a 1-4x speed up using that.
By the end of the year I would like to have the all of the ipfs huggingface bridge modules integrated into an electron app, and 50% of the nodejs modules translated from python libraries (I am at 25% right now), and a basic browser js client that calls the electron app. By the first quarter of 2024 I would like to have all of the modules translated to browser client js including transformers.js and web neural networks. Hopefully my partner will be done porting the code of our 3d avatar from babylonjs to threejs, and i can facebook releases an audio to audio language model, for our 3d avatar to run completely in the browser.
links description
1) the license for the openshift version of the model server / endpoint demultiplexer
2) the state of the embedding library and in a working state before I decided to refactor everything
3) the project tracking for my "ipfs huggingface bridge"
4) the 3d Avatar that we're working on polishing
5) a picture of me (the far right) at the very first linux foundation OPEA (open platform for enterprise AI) meeting
6) the Caselaw Access Project embeddings generated by the embeddings library.
quantitative pricing analysis
with alibaba-nlp/gte-small model:
Openshift Large instance (sapphire rapids?) $23.6 per 1 million embeddings (10 samples /s) ( assuming 16 core sapphire rapids on google cloud compute is comparable to the 14 core large instance)($0.85/hr)
Xeon E5-2690v4 dual socket (28 core) (4 samples /s) $56.80 per 1 million embeddings ($0.50 /hr on coreweave) (my home server)
Nvidia A5000 (64 samples /s) $3.73 per 1 million embeddings ($0.86/hr on corewave)

Log in or sign up for Devpost to join the conversation.