Inspiration
ParallaxVision was inspired by a simple but urgent problem: in emergencies, first responders are often forced to make life-or-death decisions with incomplete information. Firefighters may enter smoke-filled buildings without knowing the interior layout, hazard locations, or the fastest evacuation routes. Law enforcement officers may need to move through unfamiliar spaces while minimizing exposure and protecting civilians. In both cases, uncertainty costs time and increases risk.
We wanted to explore whether artificial intelligence and computer vision could reduce that uncertainty. Our goal was to design a system that could reconstruct and interpret buildings from available imagery, then generate tactical navigation support for emergency response. At its core, ParallaxVision is motivated by the belief that technology should not only be impressive, but also meaningful. We wanted to create something that could help protect the people who protect everyone else.
What it does
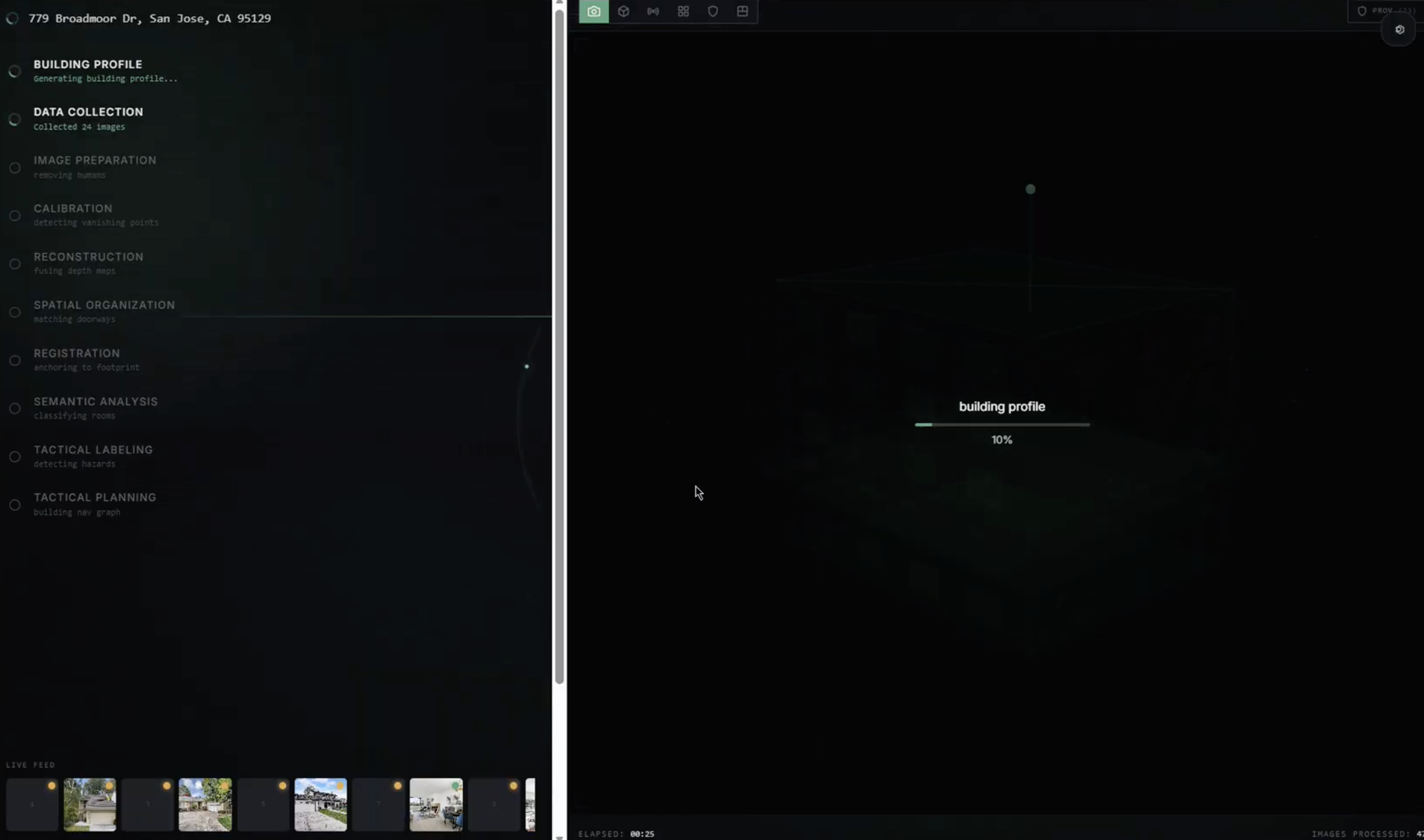
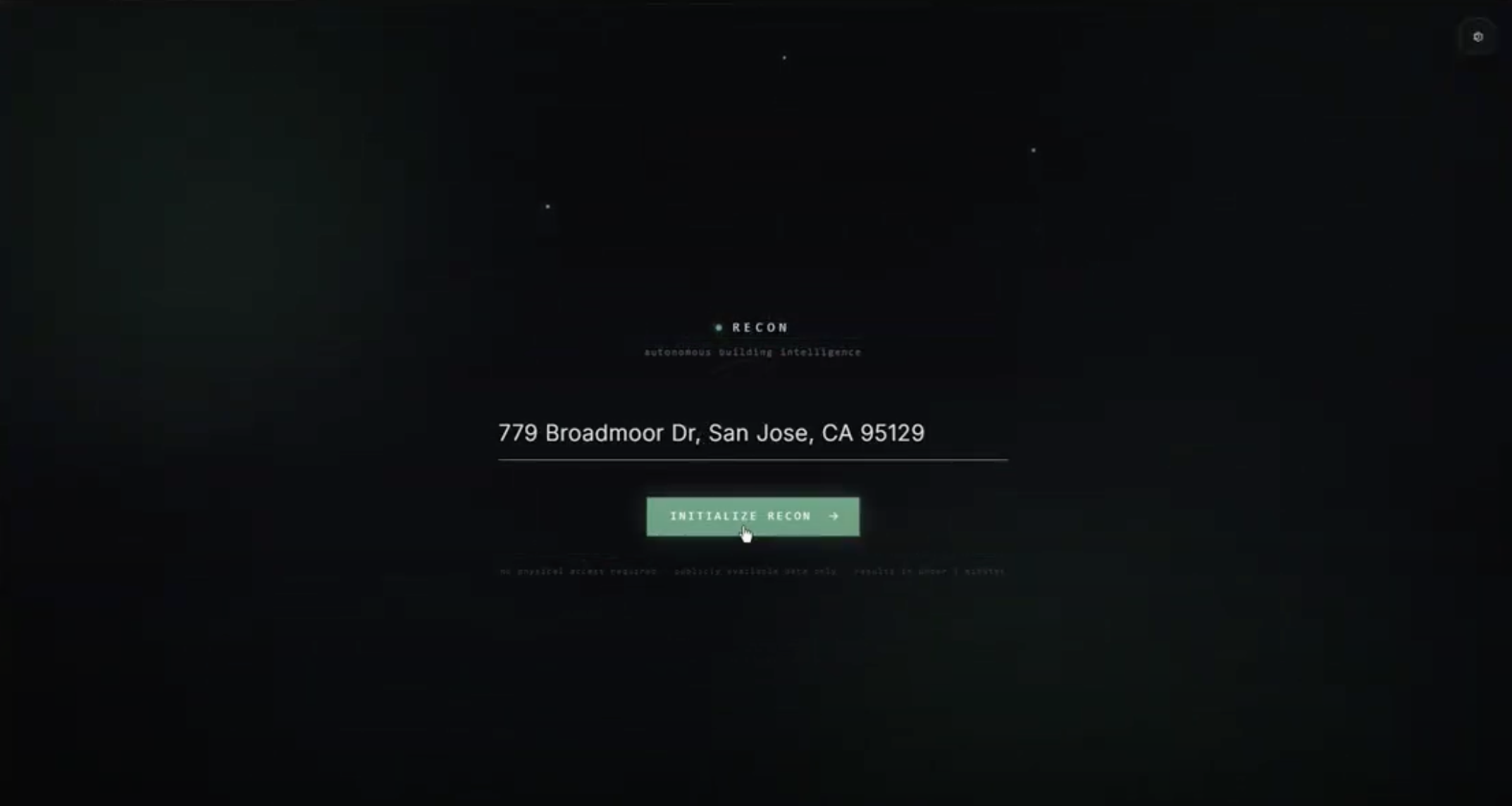
ParallaxVision is an AI-assisted building intelligence and navigation system for emergency response. It combines computer vision, 3D reconstruction concepts, and tactical path planning to transform available visual data into a more useful spatial model of a building.
The system is designed to:
- Analyze building imagery from multiple perspectives
- Reconstruct an approximate 3D understanding of interior and exterior spaces
- Identify meaningful objects and structural elements such as doors, windows, corridors, hazards, and exits
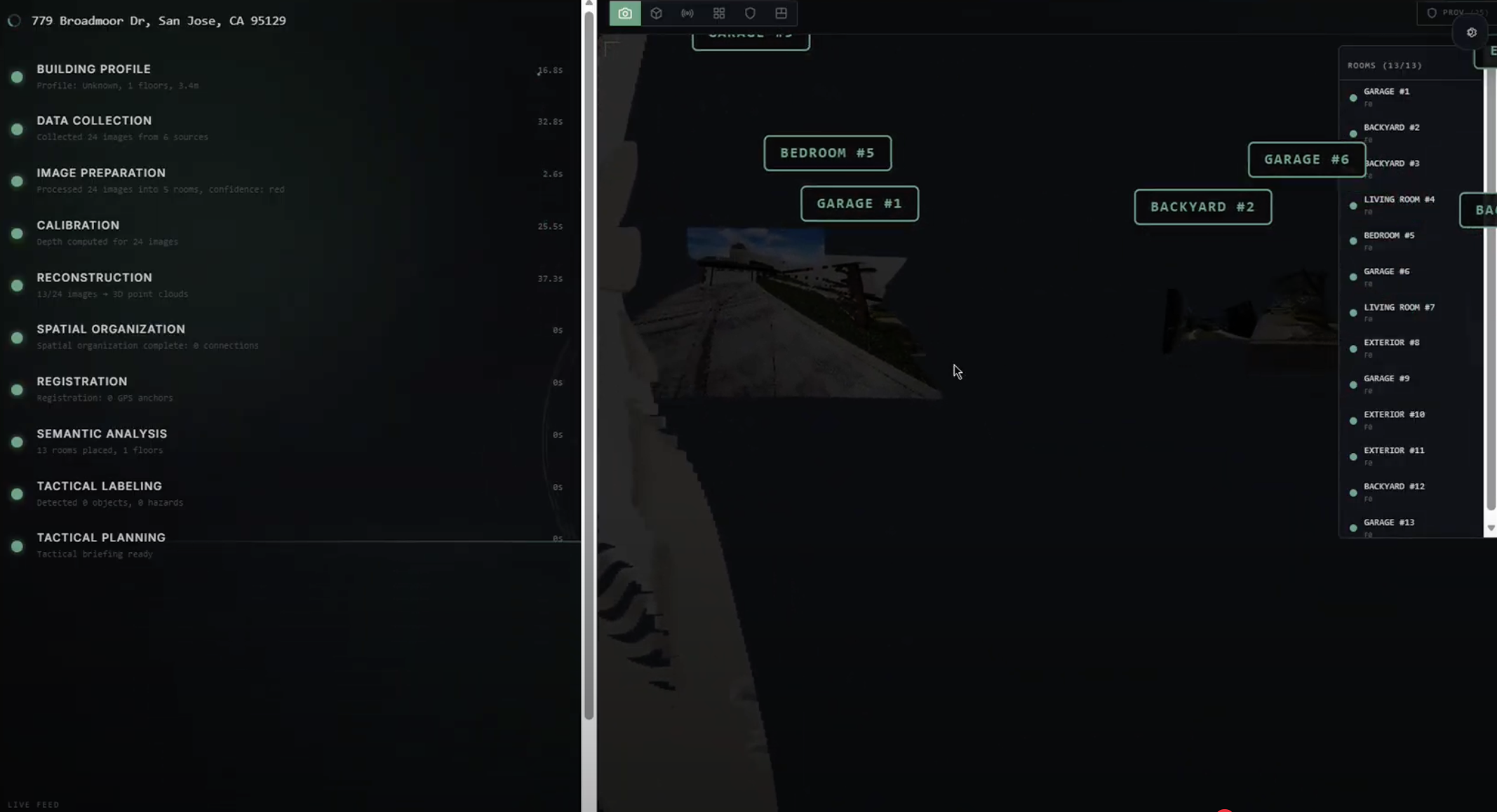
- Classify areas by confidence depending on how strongly they are supported by visual evidence
- Generate role-specific tactical routes for different responder needs
We developed the concept around two operational modes. In Firefighter Mode, the system prioritizes wider corridors, likely hazard zones, evacuation paths, and fast access to critical locations. In Law Enforcement Mode, it prioritizes reduced exposure, safer approach routes, sightline awareness, and cover positions. The result is a system that aims to turn scattered visual information into structured situational awareness.
How we built it
We built ParallaxVision as a layered system that combines several major technical ideas into one architecture.
Image acquisition pipeline. We built automated collectors that pull building imagery from multiple public sources in parallel — Google Street View for exterior coverage, real estate listing sites (Redfin, Zillow) for systematic interior photography, Google Places for visitor-contributed photos, YouTube for walkthrough video frames, and oblique aerial imagery for sides that Street View cannot reach. A classification module (detect_residential.py) determines whether an address is residential or commercial, since different building types require different data sources and reconstruction strategies.
Image preparation pipeline. Images are filtered for quality using Laplacian variance blur detection. Near-duplicates from multiple sources are consolidated using perceptual hashing. Human figures are detected with object detection, their pixel heights recorded for metric scale reference, and then removed via inpainting so they don't appear as permanent obstacles in the reconstruction.
Reconstruction pipeline. We estimate camera viewpoints using feature matching and structure-from-motion principles (COLMAP), then use dense reconstruction methods to recover building geometry. For areas with stronger image coverage, we explored high-quality rendering approaches such as Gaussian Splatting and Neural Radiance Fields. For sparse regions, we rely on monocular depth estimation (Metric3D v2, Depth Anything V2), single-image room layout prediction (HorizonNet), and building-type-based estimation. Metric scale is established independently for each image using detected reference objects of known size — standard doors ($2.1 \text{m} \times 0.9 \text{m}$), stair risers ($0.18 \text{m}$), ceiling heights, and counter heights.
Semantic understanding. We combine detection, segmentation, and classification to interpret what the geometry actually represents — doors, windows, stairs, hazards, room types, and key tactical features. Each detected element is projected into 3D space by casting rays from the estimated camera position through the object's pixel coordinates to the reconstructed mesh. Confidence scoring classifies every surface as:
$$\text{confidence} = \begin{cases} \color{green}{\text{GREEN}} & \text{verified from source imagery} \ \color{goldenrod}{\text{YELLOW}} & \text{interpolated or style-matched} \ \color{red}{\text{RED}} & \text{AI-estimated, no direct evidence} \end{cases}$$
Navigation and tactical planning. Rooms and corridors become nodes in a navigation graph, connected by edges through doorways and openings. Each edge receives a risk weight based on exposure (fatal funnel analysis), hazard proximity, and reconstruction confidence. $A^*$ pathfinding computes optimal routes for each responder role, with different cost functions for firefighter versus law enforcement priorities.
Frontend. The web interface is built with Next.js 14, TypeScript, TailwindCSS, and React Three Fiber for 3D rendering. Results stream progressively via WebSocket — the model visibly assembles itself as each reconstruction stage completes. The interface includes an animated intro sequence, a scanning overlay during reconstruction, and a 3D viewport ready to receive GLTF models from the backend pipeline.
Backend. FastAPI serves the WebSocket event stream and REST endpoints for OSM footprint lookup and Google Street View integration. The photo acquisition pipeline runs as standalone Python scripts that emit standardized provenance.json bundles tracking the source, confidence, and metadata of every image used in reconstruction.
Challenges we ran into
The gap between ideal and real-world data. High-quality 3D reconstruction methods require many overlapping images from multiple angles, but real buildings often have sparse interior imagery, inconsistent lighting, occlusions, or limited viewpoints. A well-photographed shopping mall might yield hundreds of usable frames; a private warehouse might yield zero interior images. We learned to design for this variance rather than assuming ideal coverage.
Residential versus commercial coverage. Our initial pipeline was built around Redfin listing photos, which only cover residential properties. Commercial buildings — malls, offices, schools, hotels — require entirely different data sources (Google Places visitor photos, YouTube walkthroughs, architect portfolios). We built a classification cascade to detect building type before choosing the right collection strategy, but the coverage gap for commercial interiors remains a significant challenge.
Interior-exterior registration. Connecting the inside of a building to the outside in one coherent model requires matching windows, doors, floor levels, and entry points across completely different image sources. In theory this is straightforward; in practice it is a difficult spatial reasoning problem with many ambiguities. We rely on window view matching, main entrance alignment, and constraining all interior geometry to fit within the verified exterior footprint.
Scope management. Once we began combining reconstruction, semantic labeling, confidence mapping, and tactical route planning, the project grew far beyond a typical single-feature application. Balancing ambition with what we could actually build and demonstrate in a hackathon timeframe was one of the hardest design challenges we faced.
Performance versus visual richness. The frontend interface went through multiple iterations of adding atmospheric effects (ambient particles, animated gradients, SVG animations) and then stripping them back when they caused lag. Finding the balance between a visually impressive demo and smooth performance on standard hardware required multiple profiling and optimization passes.
Accomplishments that we're proud of
End-to-end system design. ParallaxVision is not a single model or a single feature — it is a complete pipeline from address input to tactical output. We connected image acquisition, quality filtering, 3D reconstruction, semantic labeling, confidence scoring, navigation graph construction, and role-specific route planning into one coherent architecture.
Working data pipeline. The Redfin photo scraper (download_photos.py) actually works — it finds listing URLs from an address, extracts the MLS ID from the page HTML, bypasses CDN restrictions using curl with browser headers, downloads all available photos, and emits structured provenance bundles. The building type classifier (detect_residential.py) correctly distinguishes residential from commercial addresses using a cascade of Redfin, Zillow, web search, and Google Places checks.
Human-centered purpose. The concept is built around safety and preparedness, not convenience or entertainment. That mission gave the project both technical depth and real-world meaning. Every design decision — from confidence color coding to the choice of cost functions in pathfinding — was made with emergency responders as the end user.
Honest uncertainty communication. Rather than hiding gaps with fake geometry, the system is designed to be transparent about what it knows and what it's guessing. The confidence tier system (green/yellow/red) ensures that responders can distinguish verified intelligence from AI estimates at a glance.
What we learned
We learned that building intelligence is not just about reconstruction accuracy — it is fundamentally about communicating uncertainty. In real-world environments, missing data is unavoidable, so an intelligent system must express confidence levels rather than pretending every output is equally reliable. Mathematically, every measurement in the system carries an uncertainty estimate:
$$\sigma_{\text{room}} = f(\sigma_{\text{depth}}, \sigma_{\text{detection}}, \sigma_{\text{perspective}})$$
This changed how we think about AI systems: transparency is just as important as capability.
We also learned how many disciplines intersect in one ambitious project. Computer vision, geometric reasoning, AI inference, navigation algorithms, web scraping, interface design, sound design, and public safety constraints all influence one another. No single model or technique carries the project — value comes from how the pieces integrate.
We learned that real-world data sources are messy and adversarial. CDNs block automated downloads. Listing sites change their markup. Commercial buildings have fundamentally different data availability than residential ones. Building a robust pipeline means building for failure at every step and having fallbacks ready.
Most importantly, we learned that meaningful innovation requires tradeoffs. A technically impressive design is not enough by itself — it also has to be explainable, feasible, and grounded in a real user need.
What's next for ParallaxVision
The next step is to move from system concept toward a focused, demonstrable prototype. Our immediate goals:
- Complete the 3D reconstruction loop — connect the photo acquisition pipeline to COLMAP and produce real exterior meshes from Street View imagery
- Expand commercial building support — integrate YouTube walkthrough frame extraction and Google Places photo collection for malls, schools, and offices
- Build the tactical overlay — implement the navigation graph and $A^*$ pathfinding with role-specific cost functions on real reconstructed geometry
- Improve confidence scoring — develop quantitative metrics for reconstruction quality per-surface rather than per-image
- Field testing — partner with a fire department to evaluate whether the system's spatial intelligence actually improves pre-entry situational awareness in training scenarios
In the long term, we want ParallaxVision to become a tool that emergency teams reach for as naturally as they reach for a radio. Our vision is not to replace human judgment, but to augment it with better information. If technology can reduce uncertainty even slightly in high-risk situations, it has the potential to save lives.
Built With
- browseruse
- chatgpt
- claude
- fastapi
- gemini
- nextjs
- openrouter
- python
- typescript
- yolov11

Log in or sign up for Devpost to join the conversation.