-
-
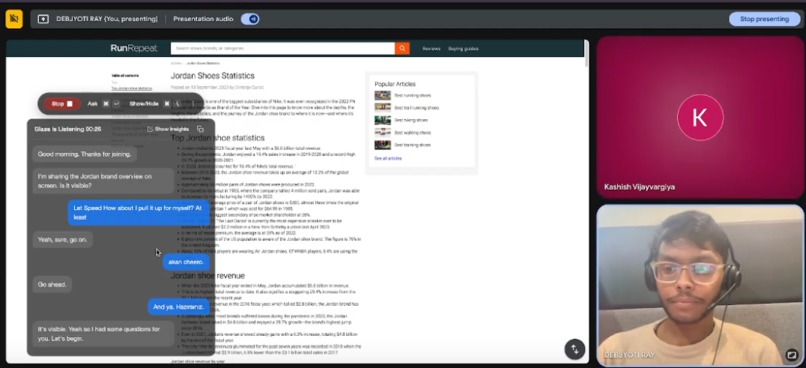
Showing paragon in action
-
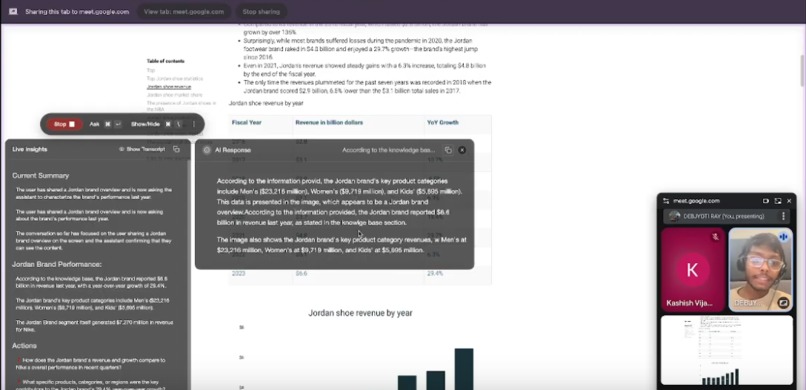
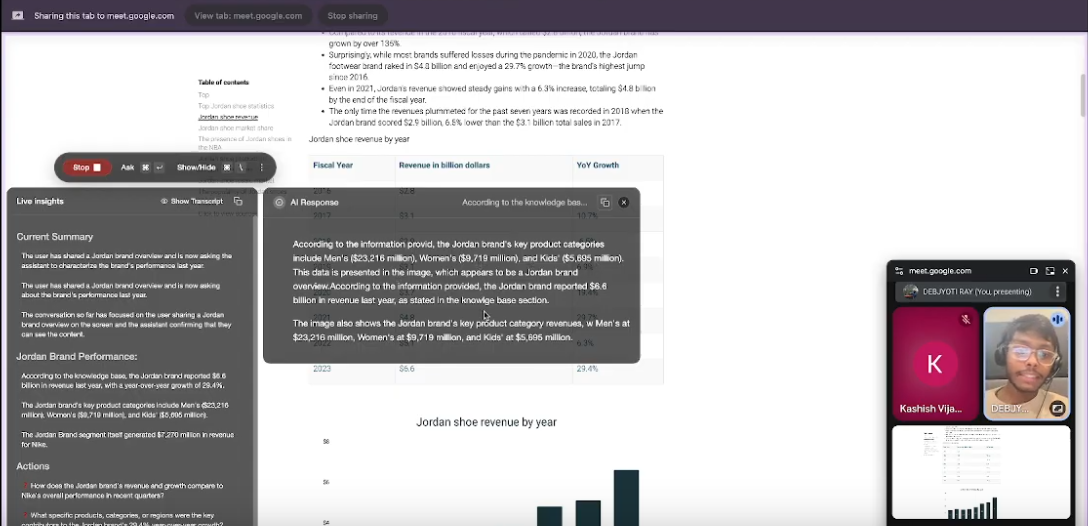
Show paragon chat interface
-
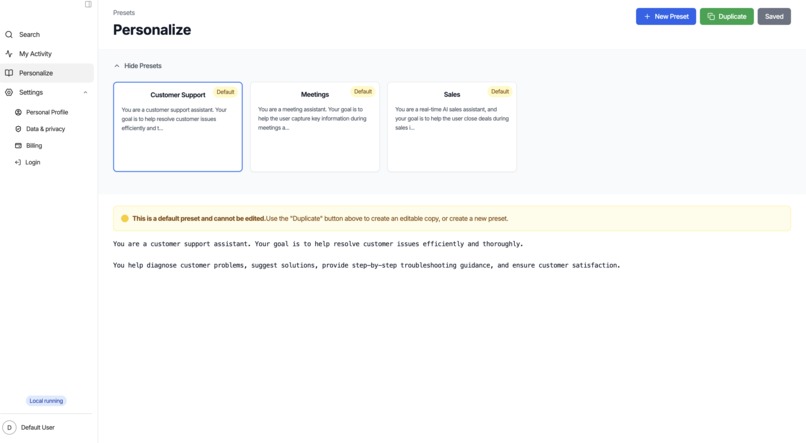
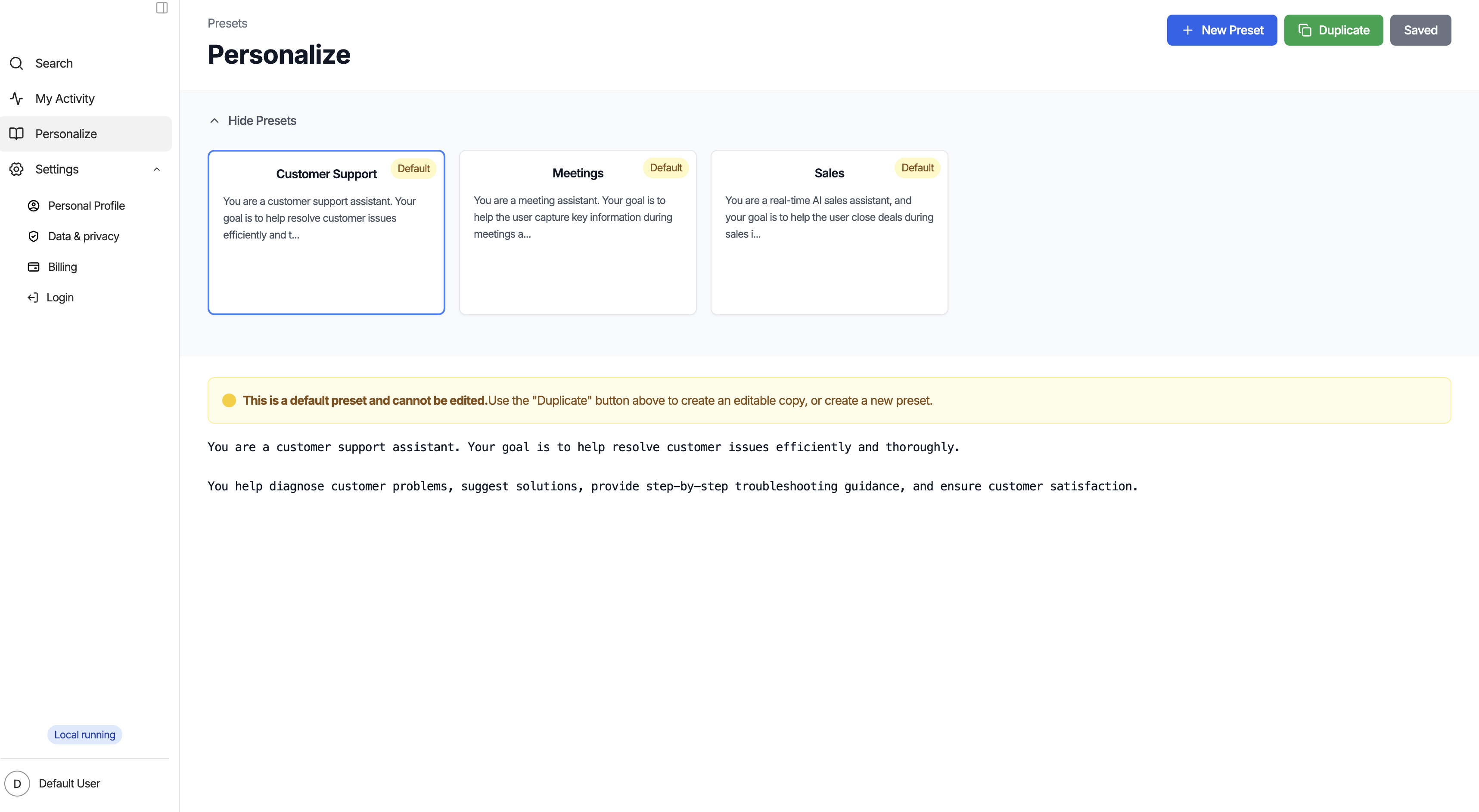
Preset Personalization
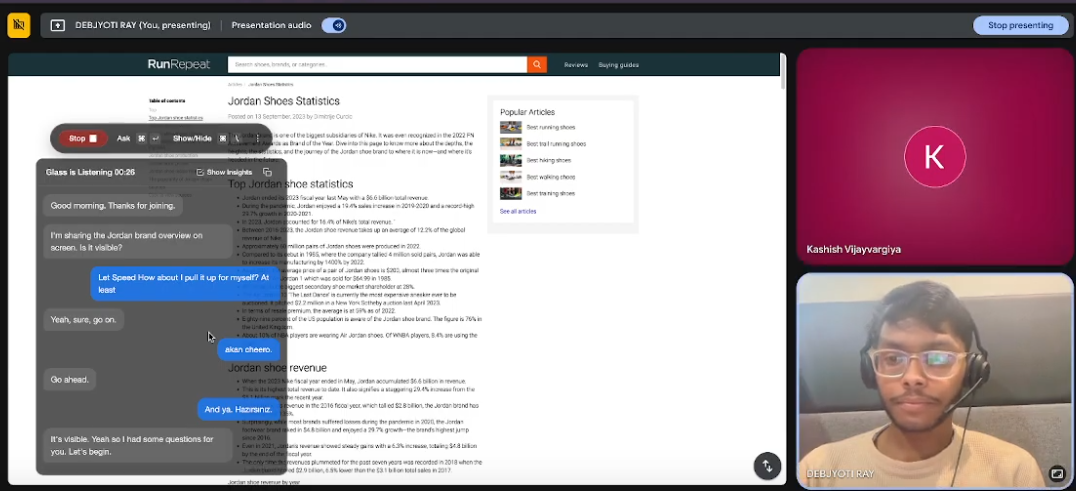
Inspiration
Meetings overwhelm memory – key stats, jargon, or past discussion points are often forgotten. Inspired by tools like Cluely, we built ParagonAI to offload cognitive load during calls. Users get live, context-aware answers without switching tabs or breaking flow. As AI meeting assistants go mainstream (used by ~50% of enterprises today), we saw the need for a secure, undetectable, enterprise-grade tool that listens, watches, and reasons in real-time. Our goal: create an AI co-pilot that understands ongoing conversations, processes on-screen slides, and retrieves company-specific answers instantly. This lets professionals stay focused while ParagonAI handles facts. The idea builds on cognitive offloading research and aligns with enterprise trends integrating genAI in meetings. Unlike bots that join calls or summarize later, ParagonAI works live – invisibly – pulling context from your screen, voice, and documents to enhance decision-making.
What it does
ParagonAI is a real-time AI assistant that watches your screen, listens to live audio, and answers questions instantly during meetings. It integrates speech-to-text (Whisper), a company knowledge base (via AWS Kendra + Bedrock), and LLM reasoning (Claude 3 Haiku). When prompted, it uses on-screen context, transcripts, and documents to respond – citing sources when needed. It also summarizes discussions or extracts action items on request. Unlike bots that join calls, ParagonAI runs locally and remains hidden, preserving privacy. Its multi-modal agent uses tool-calling logic to combine search, retrieval, and LLM steps – answering complex, multi-hop queries. Grounded in retrieval-augmented generation (RAG), it avoids hallucinations by pulling directly from verified content. Users interact via a floating desktop UI and customizable prompts. The assistant becomes a silent co-pilot, boosting recall and productivity in any meeting – answering “before you even ask.”
How we built it
We built ParagonAI as a multi-modal agent running across AWS services. The core pipeline starts with a Whisper V3 Turbo ASR endpoint on SageMaker, transcribing audio from live system input (e.g., Google Meet). Parsed text is passed into a Claude 3.5 Haiku model on Bedrock, augmented via a Bedrock Knowledge Base linked to Amazon Kendra for retrieval. Visual context (screen content) is optionally ingested using OCR and embedded with OpenSearch for hybrid retrieval. The application interface is built in Electron + React, with local session history, user prompts, and agent settings stored on Amazon EC2 + S3. Tool-calling agents (via LangChain + Claude functions) enable web search, internal doc search, and summarization. Backend APIs run on FastAPI with serverless triggers using AWS Lambda for monitoring and response alerts. Voice activity detection and speaker segmentation ensure only client-side audio is processed. Everything works in real-time with minimal latency.
Challenges we ran into
Key challenges were latency, speaker separation, and hallucination control. Real-time transcription via Whisper needed fine-tuning for speed vs. accuracy. Speaker diarization in multi-person calls proved hard to run on-device, so we used a simpler voice-activity strategy to isolate client speech. Handling ambiguous or vague queries required combining OCR-based screen analysis with semantic retrieval from enterprise knowledge bases. Streaming synchronization – aligning what’s said and what’s shown – needed lightweight buffering and parallel parsing. Model hallucinations were tackled via tight RAG pipelines using Kendra, and we restricted Claude responses to cite sources only. Infrastructure orchestration (Bedrock, S3, SageMaker, EC2) introduced service limits and cross-region latency, which we mitigated via caching layers and Lambda cold-start warmers. Finally, packaging the whole assistant into an undetectable, UI-native layer while supporting modular plug-ins was a major design lift – solved using Electron overlays and TypeScript-based render agents.
Accomplishments that we're proud of
We built a fully working proof-of-concept in under a month – combining live audio, LLM responses, and vision inputs. The assistant works invisibly during meetings, pulls answers from enterprise files and slides, and cites sources in real-time. We also built:
A local prompt designer to configure the assistant per use case (sales, interviews, etc.)
A persistent session viewer, storing meeting context, prior answers, and action items
Modular agent flows that combine screen vision, voice prompts, web tools, and knowledge base search Early tests in internal sales meetings showed >85% accuracy in response quality, and latency stayed under 3s end-to-end. The assistant helped reduce meeting follow-up time by ~40%. We’re also proud of how well it runs on-device, without needing external call bots or integrations. The system’s ability to “just listen and help” — invisibly — makes it usable even during high-stakes meetings.
What we learned
Building ParagonAI taught us the importance of latency-aware GenAI design. Real-time applications can't afford long model calls or irrelevant outputs. We learned to balance model size with speed, optimize retrieval latency, and craft prompt templates that anchor LLMs to ground truth. Speaker separation taught us that simpler audio heuristics can outperform heavy diarization in real-world, low-latency settings. We also learned the value of modular agent pipelines — breaking down responses into clear steps like transcription → retrieval → generation improved reliability and transparency. From a UX standpoint, we realized users want quiet intelligence: no interruptions, just help when needed. Lastly, we gained hands-on experience orchestrating AWS Bedrock, SageMaker, Lambda, Kendra, OpenSearch, EC2, and integrating them seamlessly in production pipelines — a lesson in scalable, enterprise-ready AI deployment.
What's next for ParagonAI
Next, we plan to scale ParagonAI into a full enterprise productivity suite. We're launching support for:
Multilingual audio transcription + translation
CRM & ATS integrations for sales/interview use cases
Real-time slide parsing using vision transformers for deeper on-screen context
A full “agent store” with customizable bots per domain (e.g., sales coach, HR assistant, product trainer) We're also exploring low-latency fine-tuning on Claude via Retrieval-Augmented adapters to better capture company tone and terminology. On deployment, we'll move toward agent fleet orchestration — routing queries between Claude, Mistral, and Titan depending on response needs. Long-term, our vision is to make ParagonAI the Chrome of real-time knowledge agents: invisible, powerful, and instantly helpful — whether you're selling, hiring, presenting, or learning.
Built With
- amazon-bedrock-knowledge-base
- amazon-ec2
- amazon-kendra
- amazon-opensearch
- amazon-web-services
- aws-lambda
- claude-3.5-haiku-(bedrock)
- claude-functions
- electron
- fastapi
- langchain
- ocr
- react
- real-time
- speaker-segmentation
- voice-activity-detection
- whisper-v3-turbo-(sagemaker)
Log in or sign up for Devpost to join the conversation.