-
-
Papers With Sentiment
Inspiration
I wanted to make a tool to understand emotional sentiment and bias in scientific papers.
What it does
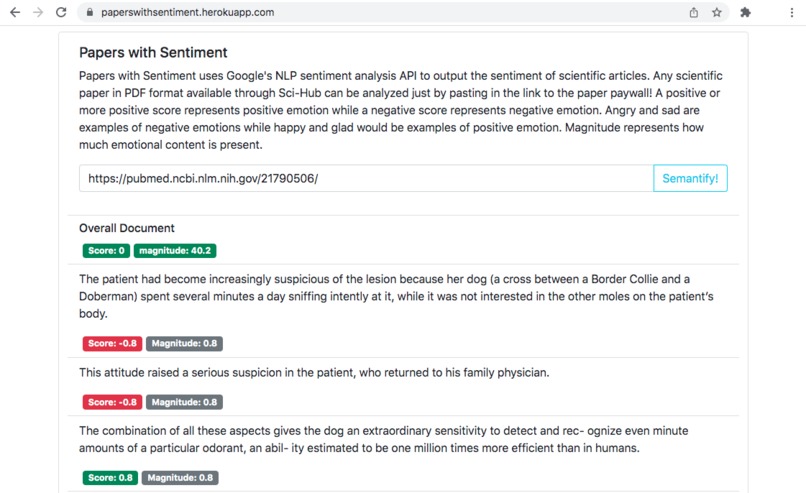
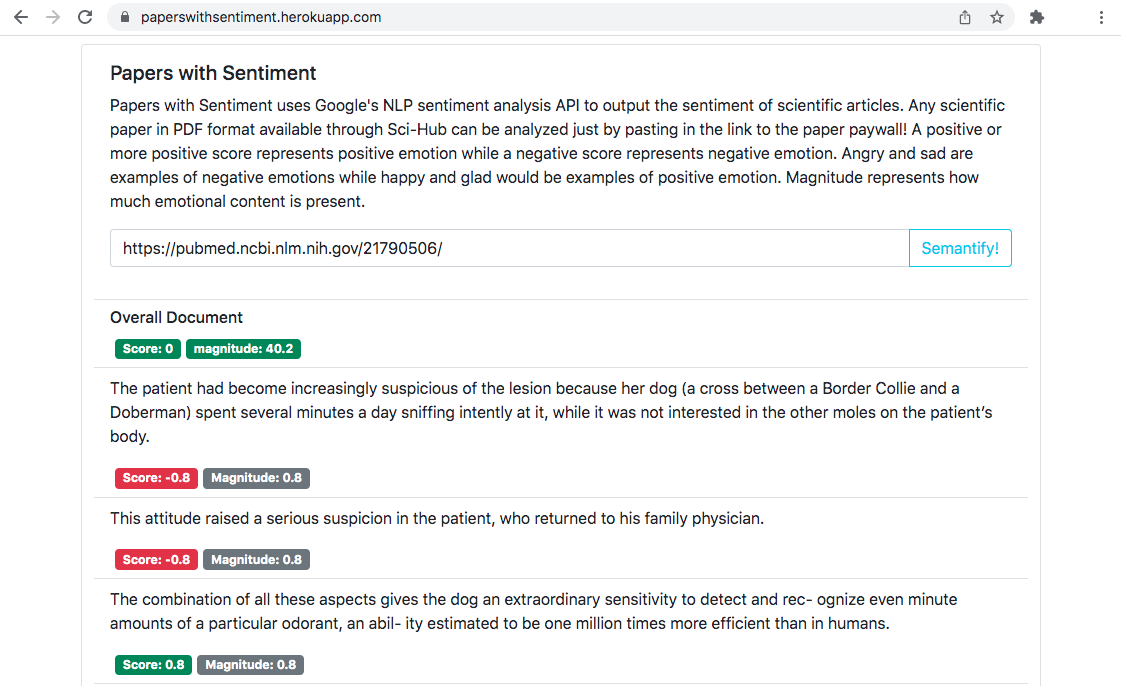
Papers With Sentiment outputs sentiment analysis on sentences from and entire scientific papers.
How I built it
Papers With Sentiment uses a flask backend written in Python. The flask backend uses the scihub.py api to search for pdf's available on Sci-Hub, then feeds the given pdf into Google Cloud's OCR API to extract structured and correctly ordered text, text is then pushed to Google Cloud's NLP Sentiment analysis API where flask then parses and returns the results. A React front end serves the results and manages queries to the flask backend!
Challenges I ran into
Biggest challenge was structuring text from PDFs surprisingly. There seems to be a serious lack of simple and local python libraries for effectively structuring texts in a non scrambled way from PDF. Pivoting to Google Cloud OCR was effective.
Accomplishments that I'm proud of
Papers With Sentiment uses the awesome platform that is Sci-Hub somewhat seamlessly. Sci-Hub is a great platform for promoting scientific study and learning, and a huge disruption to publishers, win win. The sentiment analysis seems to work well for highlighting emotional sentences in papers as well. And Google OCR worked very well for structuring PDF text.
What I learned
Cloud with integrated ML infrastructure can be useful for quick project that fit well into the providers scheme. But handmade and trained models will always outperform cloud ML models.
What's next for PapersWithSentiment
Likely not much. But if I find time I'd train a custom model for sentiment analysis more in the context of findings rather than emotion. From the papers I've run so far PapersWithSentiment has shown that overall these scientific papers are pretty unemotional. Who would have thought. A findings sentiment model would be more helpful for identifying key findings in papers and if they had a positive or negative relation to some hypothesis. This would require expensive labeling however ie. domain experts labeling papers based on findings, maybe a dataset for this exists? Who knows. If so something like a VAE autoencoder LSTM or even the GPT-3 model might be effective.
Some example url inputs
https://pubmed.ncbi.nlm.nih.gov/30251104/ https://pubmed.ncbi.nlm.nih.gov/31236716/

Log in or sign up for Devpost to join the conversation.