-
Landing Page
-
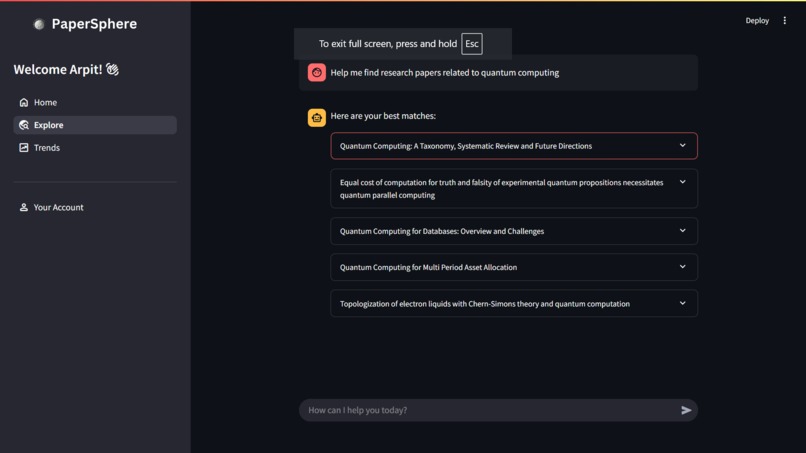
Explore Page
-
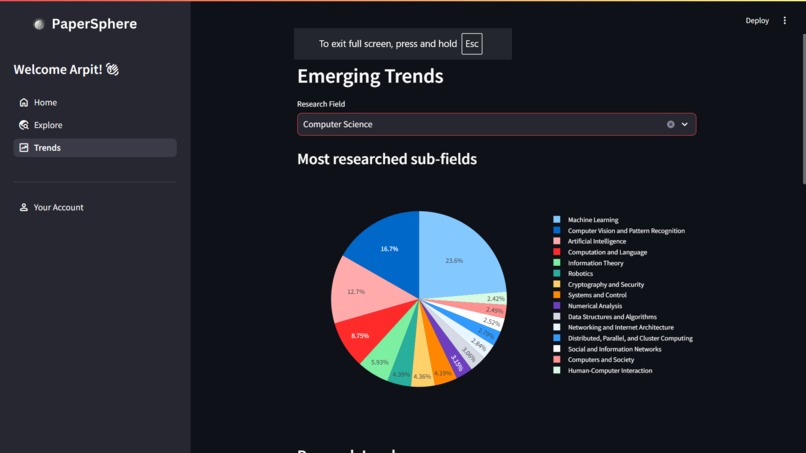
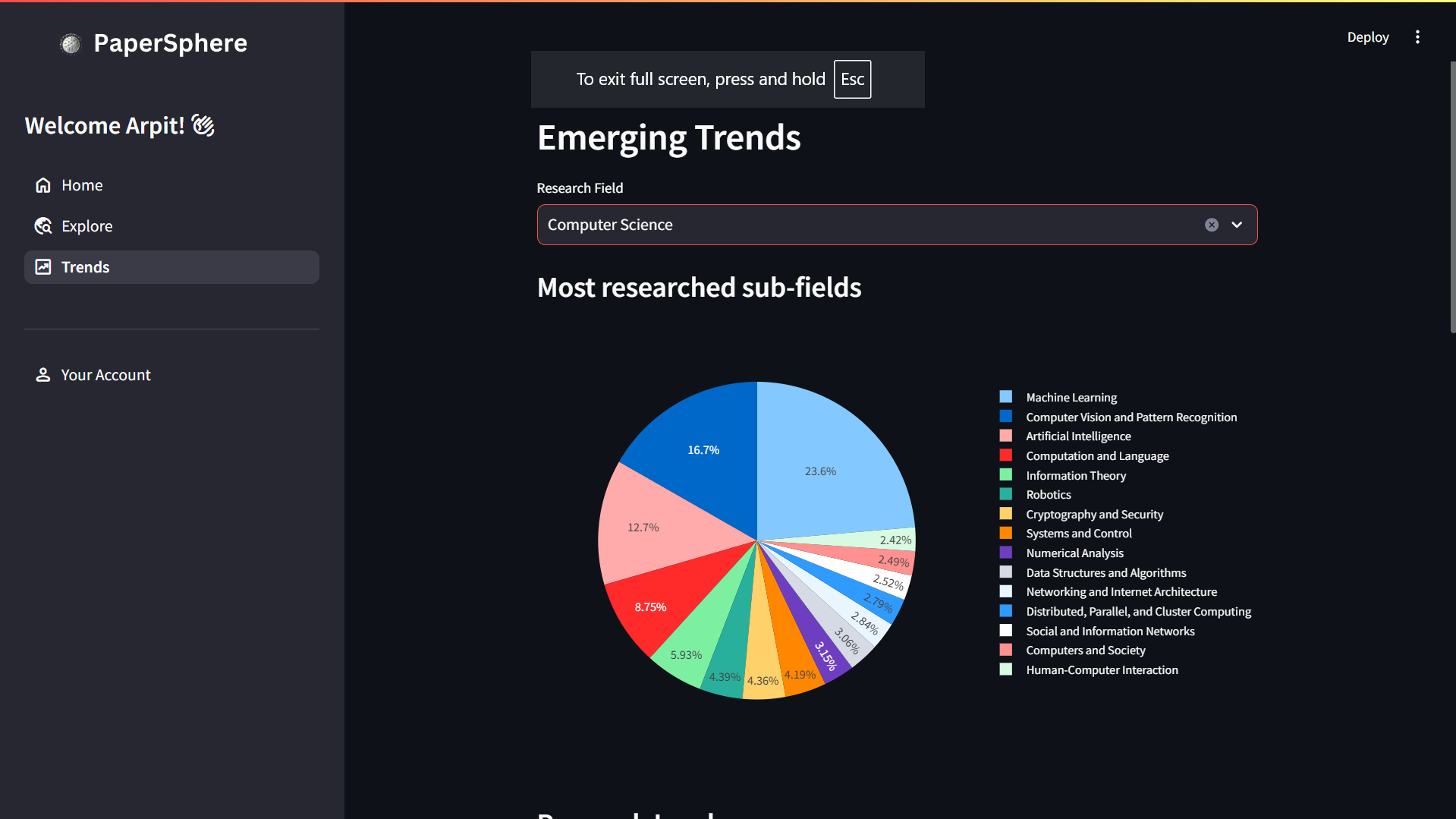
Trends Page
Inspiration
As young researchers ourselves, we found it tedious to sift through multiple resources like Google Scholar, ArXiV, and conference proceedings to discover recent advancements in our field of interest. Morevoer, finding a mentor or a collaborator to guide us on our research journey was even more challenging, having to manually comb through tons of university websites and Google Scholar pages to find the right set of people. This makes it harder for those without proper exposure or guidance to explore their research interests, and might deter them from seeking out new opportunities. To solve this, we developed PaperSphere.
What it does
PaperSphere is a platform that guides you on your research journey, matching you with the right resources that match your interests and connecting you with researchers working on cutting-edge solutions in your field. Moreover, PaperSphere gives you a birdseye view of what's happening in the research landscape, where it's currently at, and where it is headed. Whether you are a seasoned academician or a budding undergraduate, PaperSphere will help you discover the right resources.
How we built it
We developed PaperSphere as three powerful components that seamlessly cooperate with each other.
- Frontend - A Streamlit based frontend, providing a gateway to access PaperSphere's capabilites including an AI powered chatbot for resource discovery and a dashboard to analyze recent trends. This is PaperSphere's skeleton.
- PaperSphere Agent - A powerful AI agent developed using open source LLMs from Meta that understands your query and interacts with the engine accordingly. This is PaperSphere's brains.
- PaperSphere Engine - A robust recommendation engine developed using powerful NLP techniques and machine learning models that expertly matches you with the right resources along with expressive APIs to be used by our agent. This is PaperSphere's heart.
Challenges we ran into
The biggest challenge we faced was storing and managing such a large corpus of data (Almost 4GB!). The data was not clean to begin with, and getting it to a format that can be used by PaperSphere Agent was daunting. Another major hurdle we faced was having the three components interact seamlessly with each other by designing the interfaces and APIs to be used by all three.
Accomplishments that we're proud of
Solving the challenges itself was a huge accomplishment for us. We were able to develop an initial prototype that we are satisfied with and having the components talk to each other was a feat we never thought we would accomplish given the short time frame. However, we pulled through and were able to have it working.
What we learned
This hackathon was an exciting learning experience for us! We learned how AI can make our life easier with LLMs(Large Language models) and NLP(Natural Language Processing) to summarize and recommend related papers. Some of the key things we learned were:
- AI in Research- We saw how directly AI can help researchers save time by automatically finding relevant papers instead of doing manual for hours.
- With Actual Datasets- We realized from arxiv and other research inputs how crucial high-quality data was and how AI could segregate unnecessary information.
- Increasing Search and Suggestions - We found ways of rendering research papers recommendations helpful and usable.
- Collaborating and Troubleshooting - Having to develop research paper suggestion on time, we got better at collaboration, thinking collectively, and converting ideas into actions fast.
- Real World Impact - This project taught us AI research tools can actually help us assist students and researchers by streamlining the research process and making it smarter. Overall this was enlightening and enjoyable project.
What's next for PaperSphere
In its current state, PaperSphere reads data and LLM models stored locally, which increases both website load and user wait time. Here's what we plan to address in the later iterations:
- Optimize Performance: Use a vector database and API calls to reduce wait times and improve the user experience.
- Advanced Personalization: Enhance recommendation accuracy with deeper user personalization.
- Seamless Research Assistance: Implement a 'Talk to Document' feature for more efficient research interactions.
- Increase Inclusivity: Integrate voice interaction and accessibility support to make the platform more inclusive.
- Social Features: Enable users to connect with peers, share recommended papers, and engage through paper commenting and rating features.
- User Feedback Loop: Collect user feedback to drive iterative improvements and run A/B tests to refine recommendation accuracy and user experience.
Built With
- huggingface
- llms
- natural-language-processing
- nltk
- python
- recommendation-systems
- scikit-learn
- streamlit

Log in or sign up for Devpost to join the conversation.