-
-
Test
🚀 My Hackathon Story – PaperPocket
🌱 Inspiration
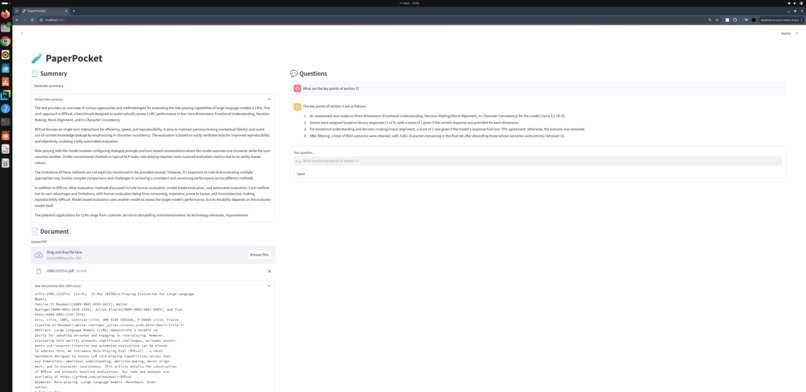
As a PhD student, I constantly face a flood of research papers. Reading and extracting insights is slow and exhausting, so I created PaperPocket: a lightweight assistant to summarize PDFs and answer questions grounded in context.
Bonus (LaTeX-ready): I often formalize ideas with math, e.g., a summary score ( S = \sum_{i=1}^{k} w_i \cdot r_i ) balancing relevance (r_i) and weights (w_i).
🛠️ How I Built It
- Extract text from PDFs → chunk into manageable, overlapping pieces.
- Build embeddings (
intfloat/multilingual-e5) for dense retrieval. - Summarize via a map–reduce strategy (≤10 concise bullets).
- RAG-based QA to keep answers faithful to source context.
- Streamlit interface for a simple UX.
I initially planned to use GPT-OSS-20B, but my machine couldn’t support it. I switched to Ollama, which worked reliably—even if responses were slower—and it let me validate the full pipeline end-to-end.
📚 Learnings & Challenges
- Integrating RAG with open-source LLMs and tuning chunking/embedding strategies.
- Trade-offs between speed, accuracy, and grounding.
- Backend adaptability (Ollama vs. GPT-OSS) and local deployment constraints.
🎓 Why It Matters
As a doctoral researcher, this tool directly supports my literature review workflow, freeing time for critical thinking, experiments, and advancing my research. It’s built for researchers like me—making reading smarter, not harder.
Built With
- gpt-oss-20b
- hugging-face-transformers
- intfloat/multilingual-e5
- ollama
- pypdf2
- python
- streamlit
- virtualenv

Log in or sign up for Devpost to join the conversation.