-
-
Home Page -> Attach Research Paper
-
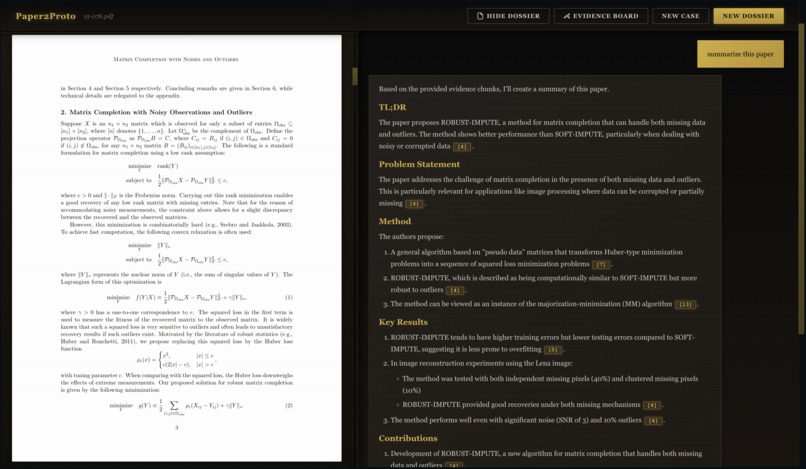
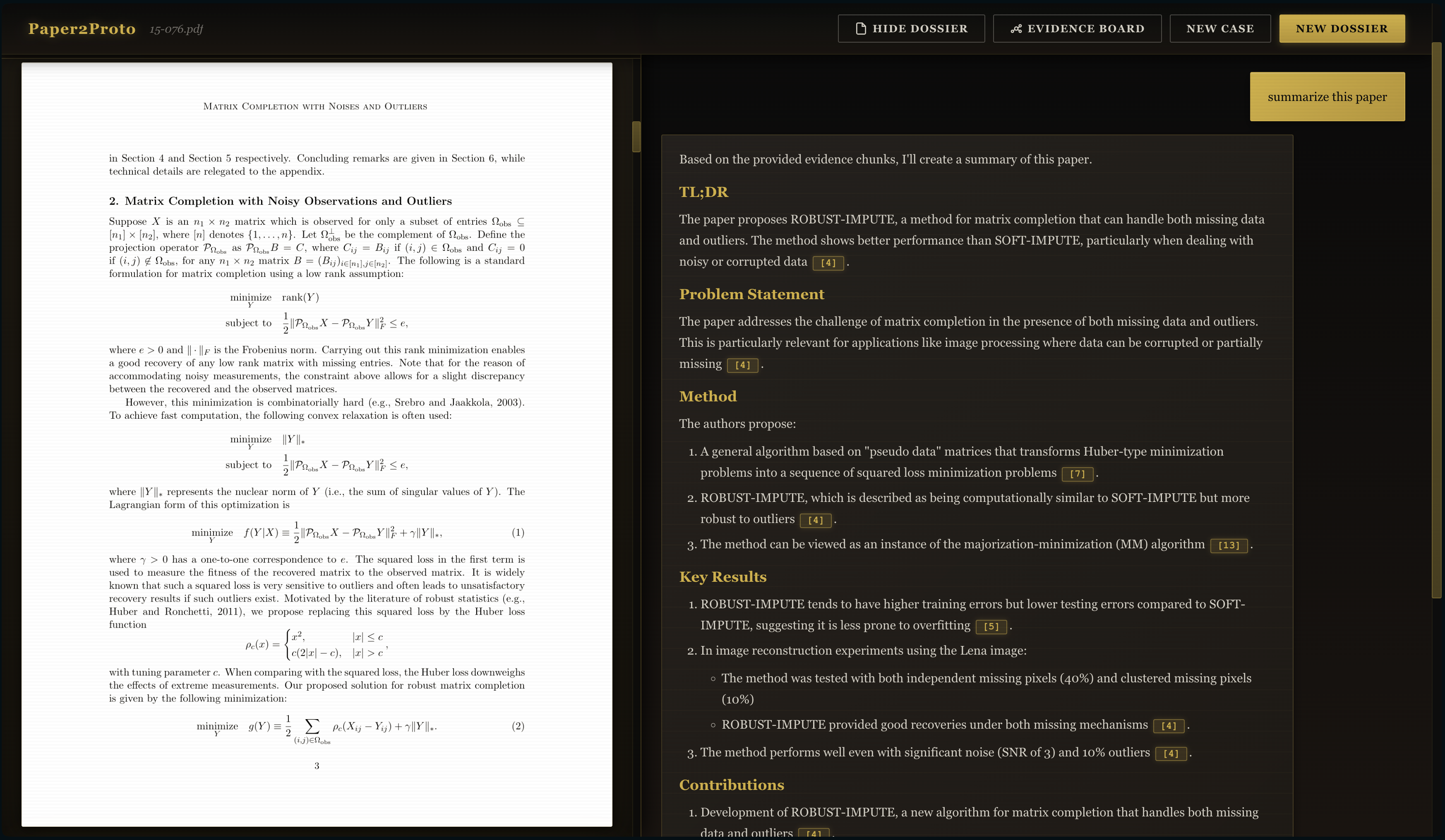
Paper Summarization -> Summarize AI Agent
-
-
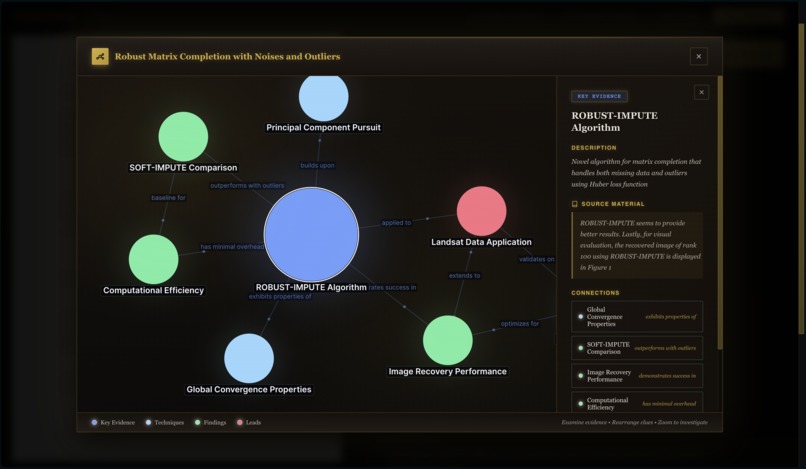
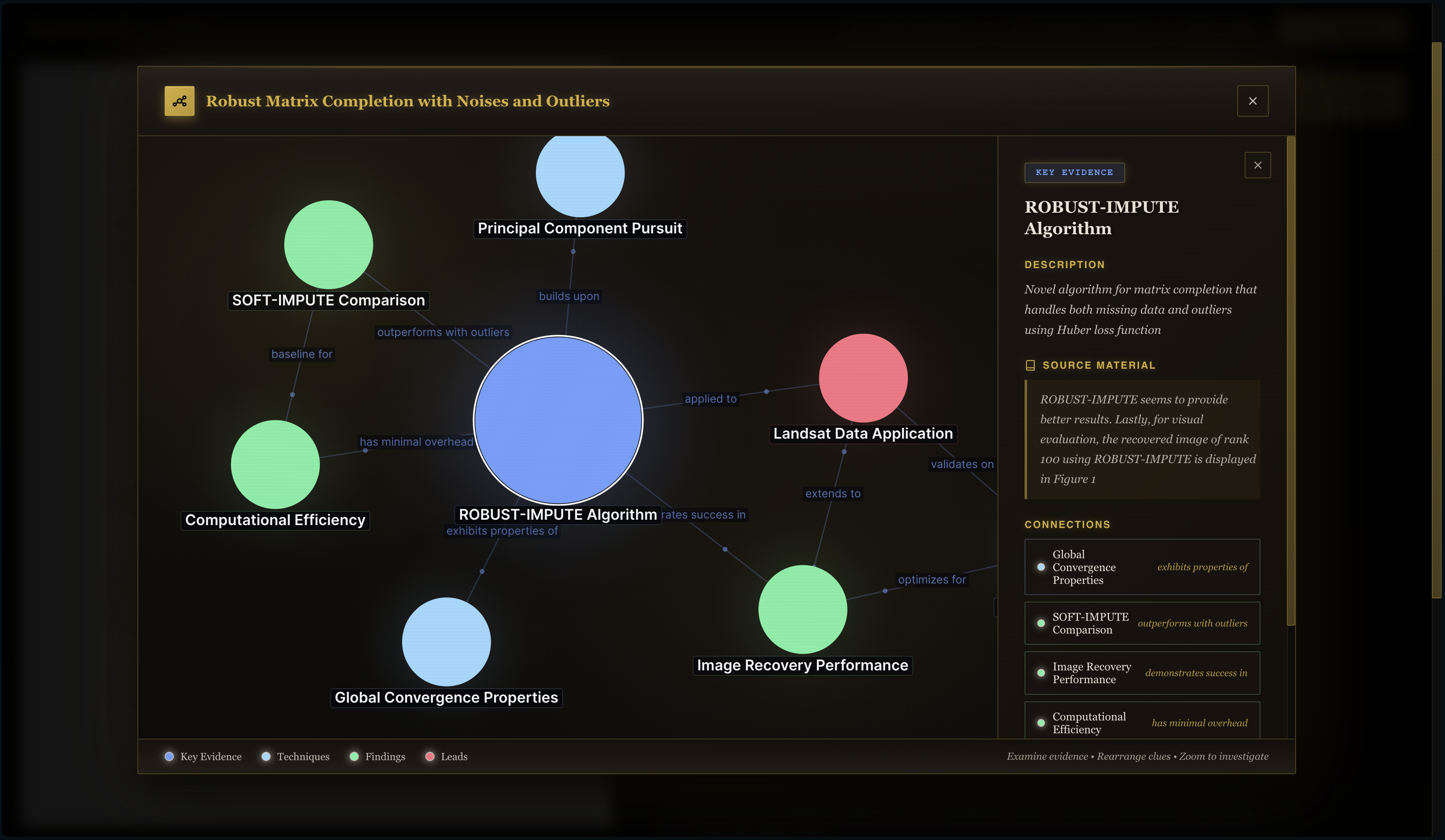
Research Paper Structure Visualization
-
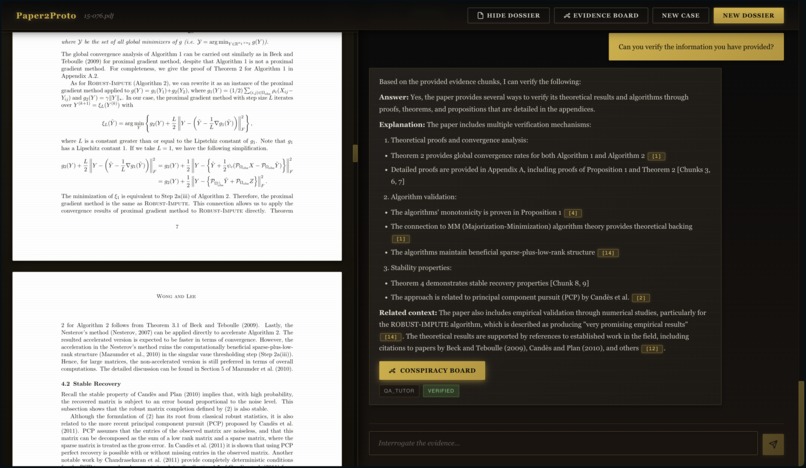
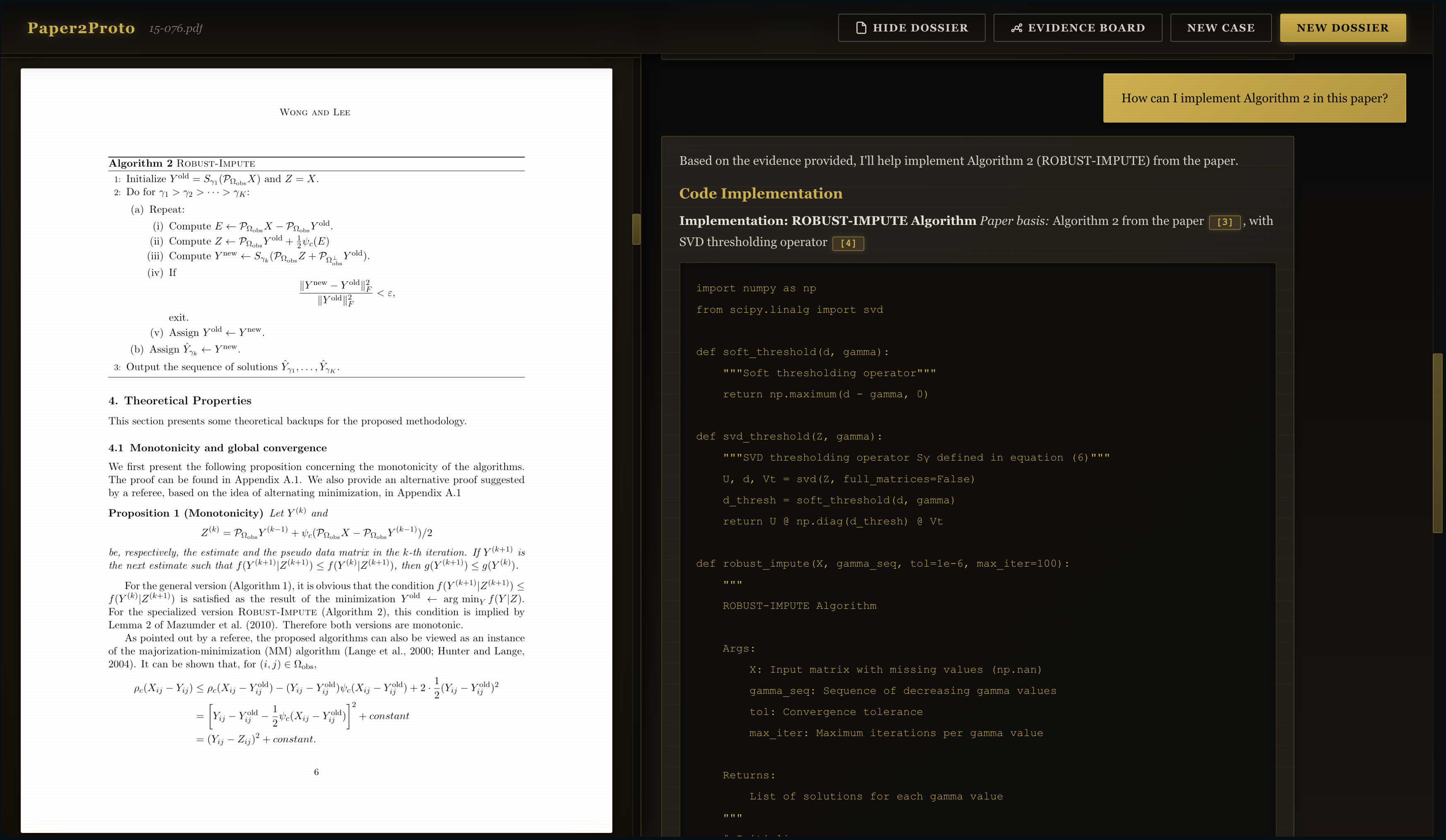
Theoretical Research Implementation -> Builder AI Agent
-
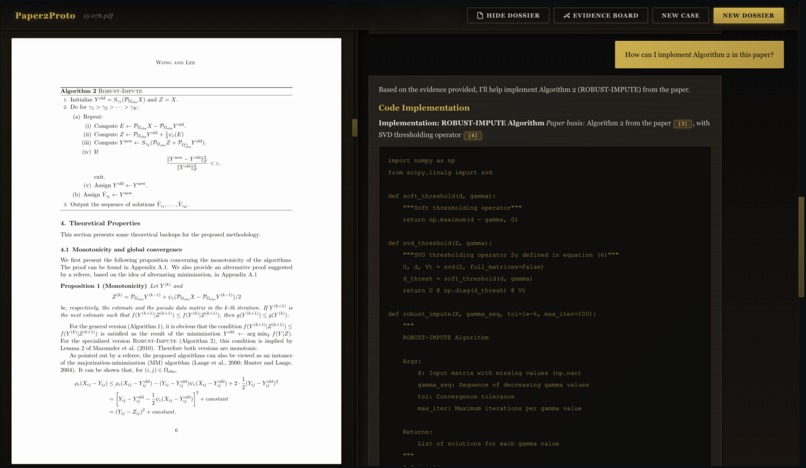
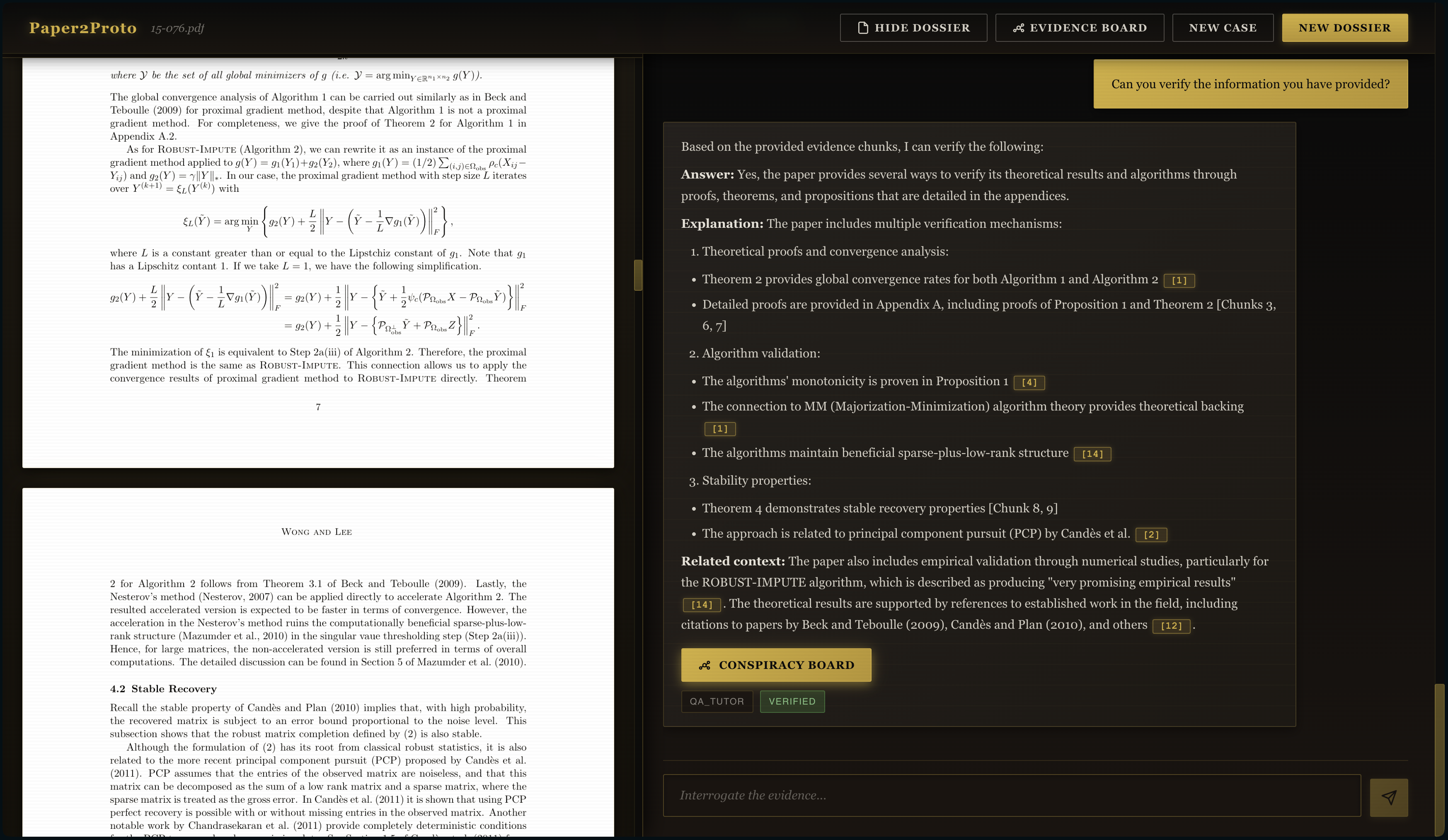
Validation of Generated Content -> Verifier AI Agent
Inspiration
Reading ML papers often feels like detective work: nice equations, but missing details. We wanted a tool that behaves like a grounded, tireless research assistant instead of a generic, hallucination‑prone chatbot.
What it does
Paper2Proto turns PDFs into a conversational, evidence‑grounded workspace.
You upload a paper, and in chat you can:
- Ask for summaries, clarifications, and derivations.
- Get code‑oriented “protos” for experiments.
- See answers that are verified against the original text, not invented.
How we built it
- Frontend (React): Upload UI (“Evidence Locker”) and chat interface calling FastAPI endpoints.
- Backend (FastAPI): Receives PDFs, stores them in Amazon S3, parses and chunks text, embeds via Amazon Bedrock, and indexes vectors + metadata into Amazon OpenSearch.
- LangGraph agents (inside the backend):
- Router: Chooses task type (SUMMARY / QA_TUTOR / BUILD / MIXED).
- Retriever: Builds an Evidence Pack from OpenSearch.
- Producers: Summarizer, Tutor/Q&A, and Builder agents powered by Bedrock (and future providers).
- Verifier: Checks drafts against the Evidence Pack and drives a verify → re‑retrieve → regenerate loop.
- Router: Chooses task type (SUMMARY / QA_TUTOR / BUILD / MIXED).
Challenges we ran into
- Designing a verification loop that improves answers without adding too much latency.
- Keeping all agents strictly grounded in the paper instead of drifting into plausible fiction.
- Handling messy, real‑world PDFs for chunking and retrieval.
- Structuring the LangGraph so that agents are specialized but not overly complex.
- Abstracting the LLM layer so we can mainly use Bedrock now but plug in others later.
Accomplishments that we're proud of
- Moving beyond “chat with your PDF” to a clear, inspectable agent graph: Router → Retriever → Producer → Verifier.
- Implementing an Evidence Pack + Verifier loop that actually corrects itself instead of just apologizing.
- A Builder agent that proposes code and configs while citing the exact passages it relied on.
- A modular architecture (FastAPI + S3 + OpenSearch + Bedrock + DynamoDB + LangGraph) that we can evolve without rewrites.
What we learned
- Grounding is a pipeline property: indexing, retrieval, agents, and verification all matter more than a single clever prompt.
- Retrieval quality dominates everything downstream; better chunks and metadata beat over‑tuned prompts.
- Explicit graphs (via LangGraph) make debugging and extending agentic systems far easier.
- Users trust honest “not found in the paper” answers more than confident hallucinations.
What's next for Paper2Proto
- Multi‑paper Evidence Packs for literature reviews and comparisons.
- Stronger Builder flows that generate end‑to‑end experiment scaffolds while staying faithful to the paper.
- Better handling of math and figures, with links from questions to the exact equations/sections.
- Human‑in‑the‑loop tools to inspect evidence, adjust reasoning, and feed back preferences.
- A provider‑agnostic LLM layer so Bedrock, Gemini, and future models can power different agents without changing the graph.
Built With
- amazon-bedrock
- amazon-bedrock-embeddings
- amazon-dynamodb
- amazon-opensearch
- css
- fastapi
- javascript
- langgraph
- node.js
- npm
- python
- react
- s3
- uvicorn





Log in or sign up for Devpost to join the conversation.