Inspiration
- To be a student is to learn, and the pinnacle of learning is discovery.
- However, it can be difficult for students to approach the research experiences preceding discovery.
- Without intimate knowledge and experience within the research industry, it can be hard to find good mentors and what to look into to get involved.
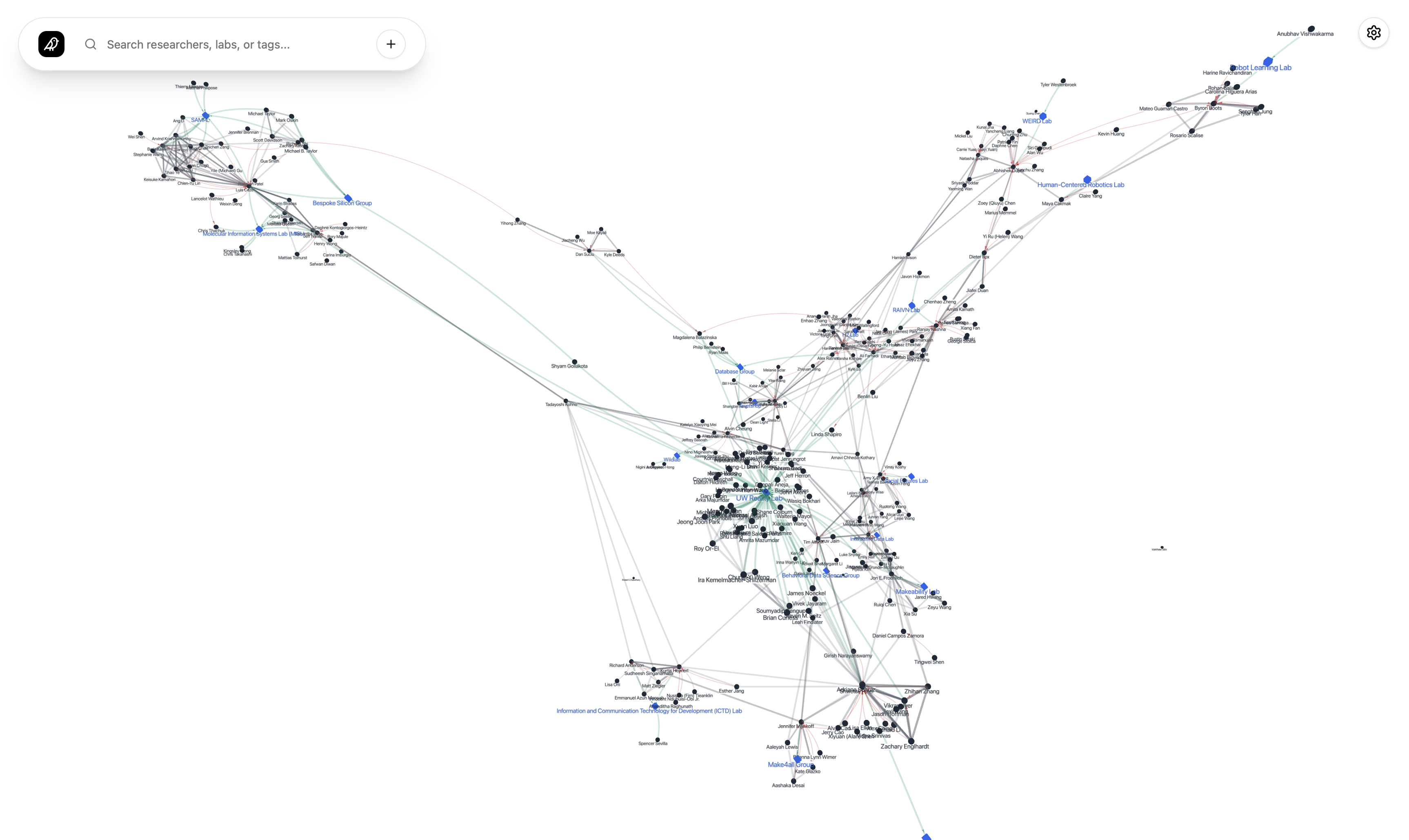
We built Paper Pigeon: a homing pigeon carrying just the info you need, finding and mapping associations between papers, researchers, and labs in the Allen School.
- By navigating a three-dimensional graph that visually and intuitively demonstrates research connections, students can find labs, topics, and areas of interest in one centralized location.
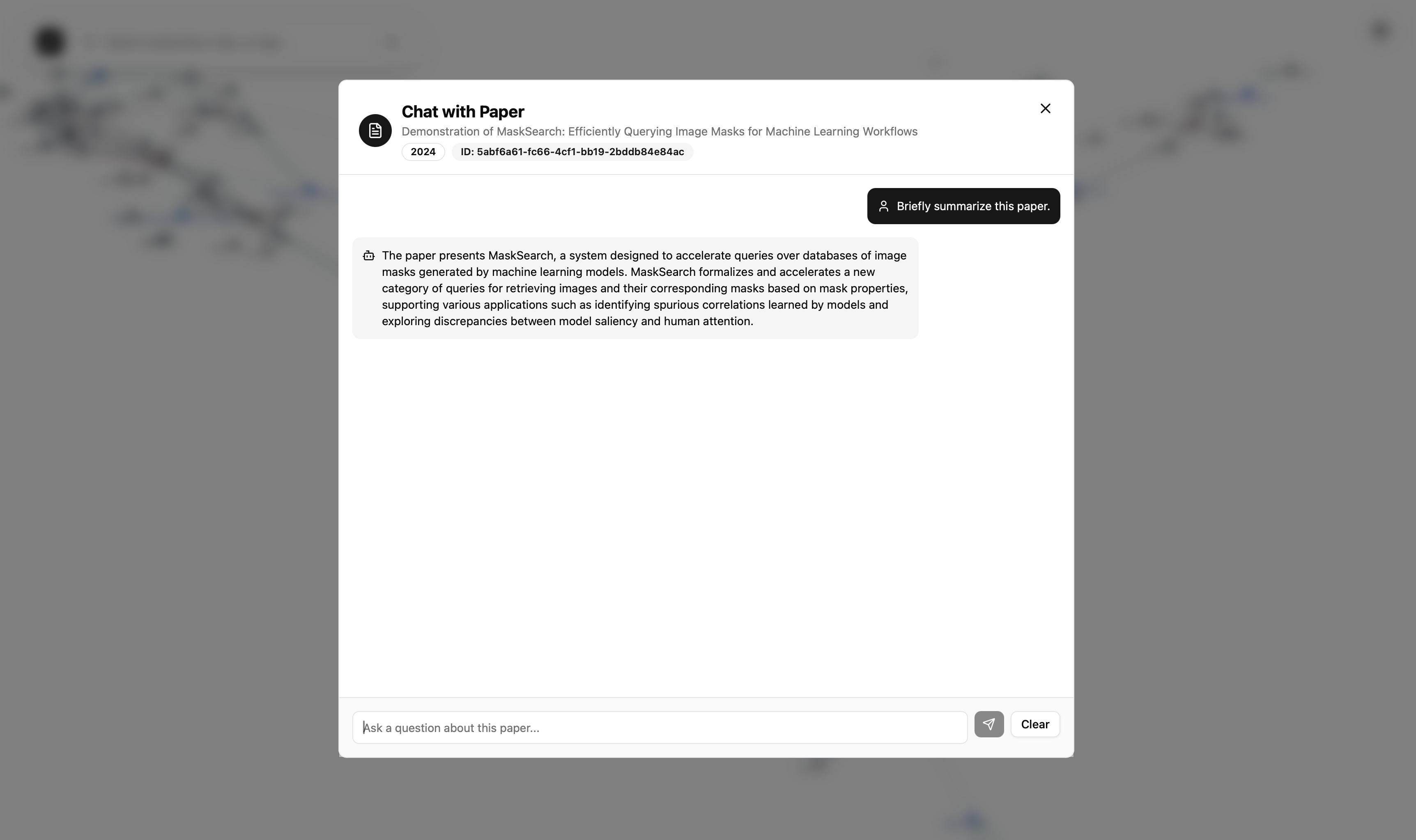
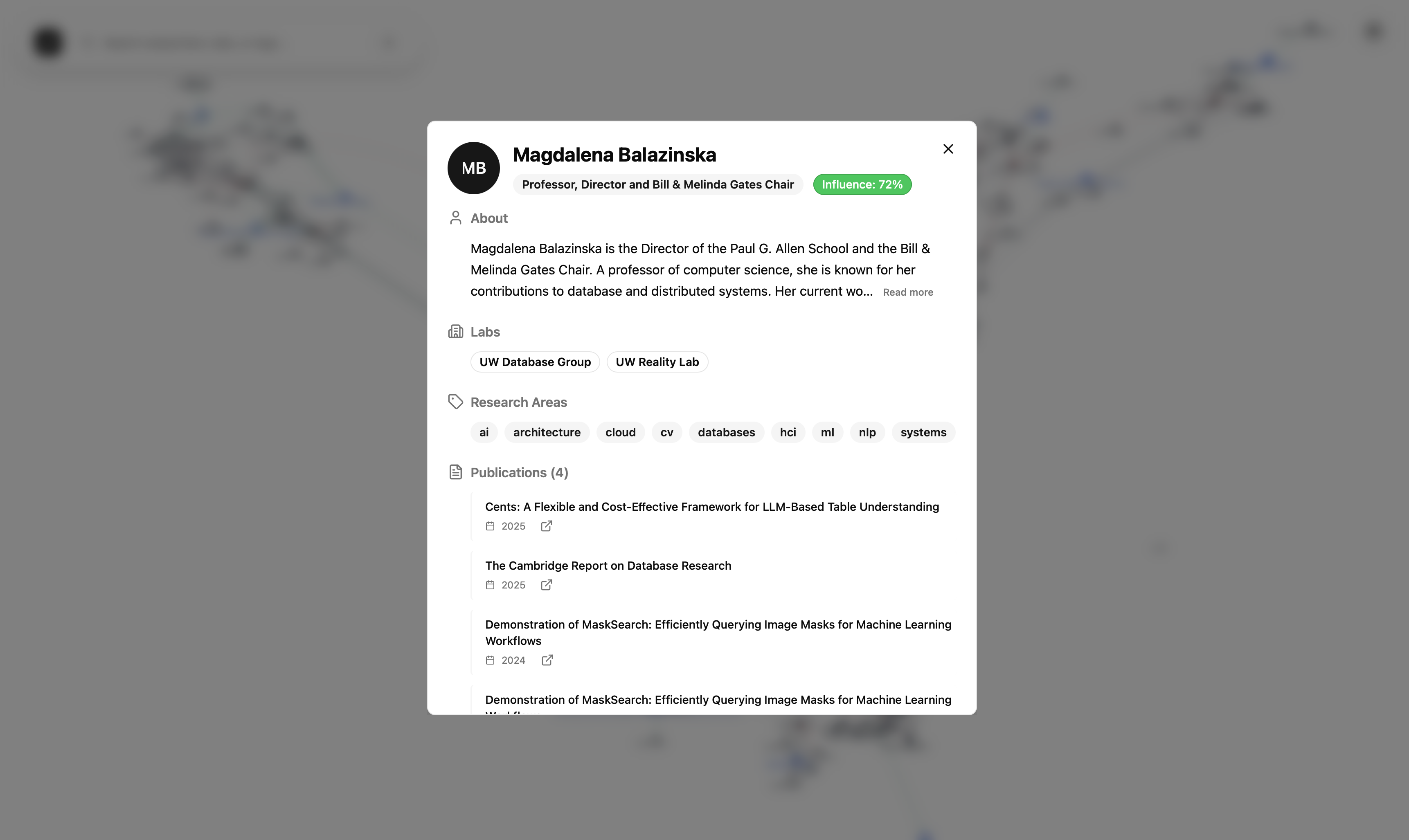
- Paper Pigeon’s entire graph can be queried to find highlighted topics of interest, and users can click any node to learn detailed information, including research contacts, links to related papers, and other resources that would be difficult to find.
- We've mapped almost one thousand connections across papers from 25 labs spanning the past five years.
- Through extensive querying, students can understand the impact of research in a more holistic way, thereby understanding the steps they would need to take to contribute to these fields.
Paper Pigeon is, truly, an opportunity that paves the way for aspiring scientists.
What it does
- Our app creates an interactive 3D knowledge graph that connects research papers, professors, graduates, and labs from UW's CSE department.
- Users can learn about UW’s influential contributions to computer science by surfing through research connections and topics that interest them.
- Paper Pigeon includes a resume-matching feature that analyzes a user's background and recommends papers, researchers, and labs optimized with their interests and qualifications.
How we built it
- Paper Pigeon uses Amazon Bedrock to process and generate embeddings from research papers to retrieve relevant responses through RAG.
- We first store over 500 raw PDFs in S3 buckets, where Amazon Bedrock processes and parses through the data to create vector embeddings.
- We then use the Gemini 2.5 Flash API to parse through thousands of pages to extract meaningful metadata, including the title and author of each paper.
- We store such metadata in DynamoDB, creating unique UUIDs for each paper and researcher for fast retrieval.
- Data gets organized into structured tables that feed into a React app running the 3d-force-graph framework, a physics-based library to visualize complicated graph networks.
- To chat with research papers, we implement RAG by semantically chunking our PDFs and embedding our chunks into a Bedrock Knowledge Base full of vector embeddings, allowing efficient semantic search across the knowledge graph.
- For the resume-matching feature, we implemented a similar RAG-based approach that parses resume content and queries the vector database to find relevant papers, researchers, professors, and labs based on semantic similarity.
Challenges we ran into
- The most significant challenge was creating a robust data pipeline to process large volumes of research papers—which lack standardized formats—and transform them into a structured knowledge graph.
- We spent considerable time ensuring that paper embeddings, labels, and metadata were organized efficiently for both storage and retrieval.
- One particular issue was when we had trouble “talking” to our papers via RAG: the model would confidently return gibberish output from our paper’s citation list.
- To solve this, we extracted metadata and allowed the model to apply its own filters to the user query. Our metadata heavily structured the model’s tendency to only retrieve from the main body of our papers.
- We also faced challenges visualizing the colossal amount of data in an accessible way for the user.
- To provide a sleek experience, we built our frontend using ShadCN UI along with the 3d-force-graph library.
Accomplishments that we're proud of
- We're proud to have accurately modeled the wealth of research produced by UW's CSE labs in an intuitive, physics-based 3D graph network.
- Our use of DynamoDB greatly alleviated our problem, allowing us to create tables connecting researchers to respective papers and colleagues.
- Bedrock helped very much with orchestrating multi-stage queries where embeddings, metadata filters, and content displays were dynamically tuned based on user interactions.
- This allowed us to maintain context relevance even with millions of tokens in play while delivering responses in milliseconds.
What we learned
- Through this project, we gained fundamental insights into AWS services, scalability, data engineering, and the power of RAG systems.
- We learned that without adequate data preprocessing, even powerful LLMs struggle with large volumes of data.
- Working with Bedrock taught us how to build intelligent, cost-effective pipelines that prioritize smart data processing over raw compute power.
What's next for Paper Pigeon
- Because of its scalable architecture, Paper Pigeon's correlation mapping and data centralization approach can be applied to many fields with overlapping professions and professionals.
- For instance, our resume RAG system could be immediately adapted to other departments within the UW.
- In addition, Paper Pigeon can help map industry positions, linking people to jobs suited to their aspirations while helping them find resources and connections along the way.
- While our app is highly generalizable and scalable, we hope to build additional scaffolding to help students facing a complex, interconnected field they wish to excel in.
Built With
- amazon-dynamodb
- amazon-web-services
- bedrock
- css
- graph
- jsx
- python
- react
- sql
- tsx
- vectordb



Log in or sign up for Devpost to join the conversation.