-
-
Paper Cuts
-
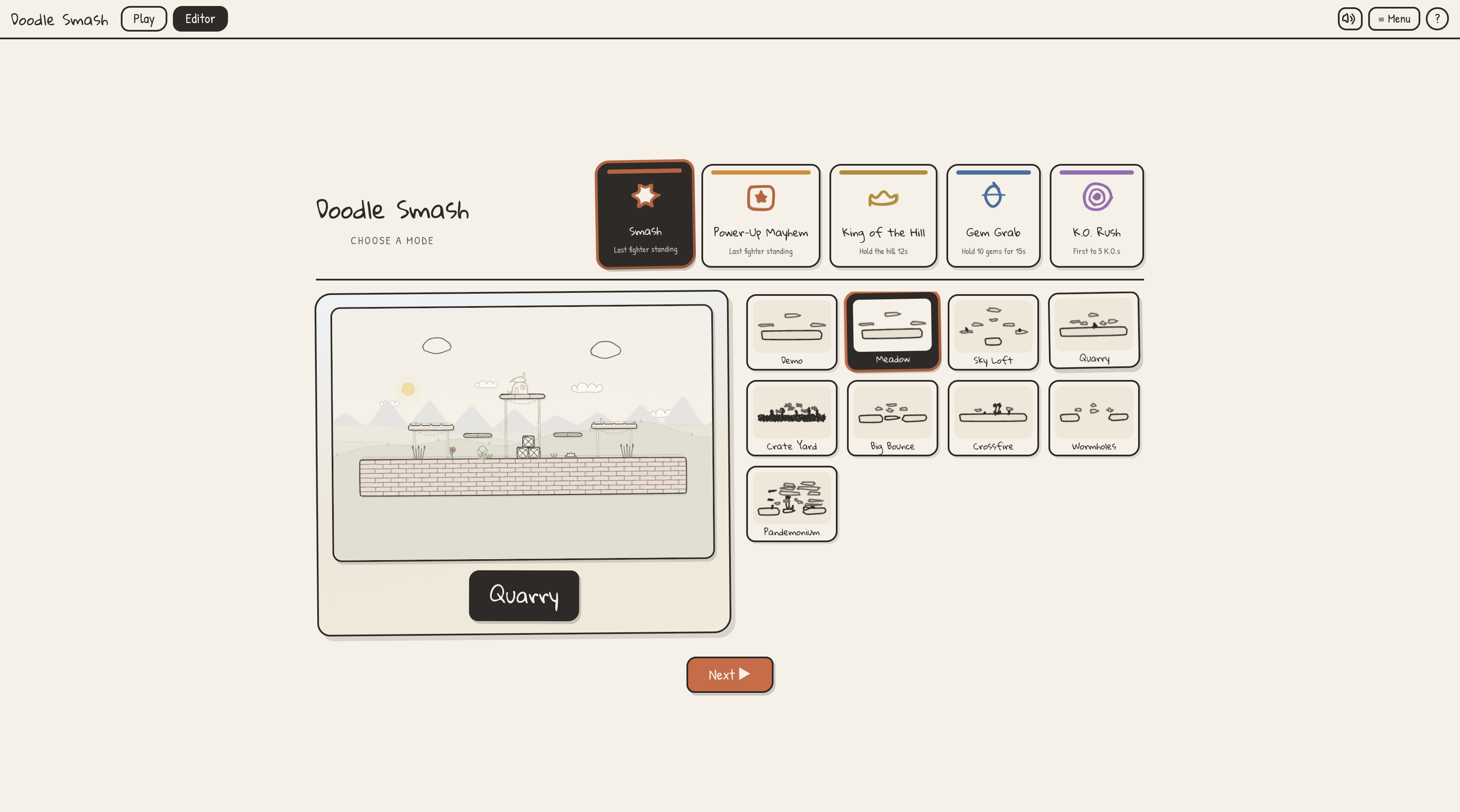
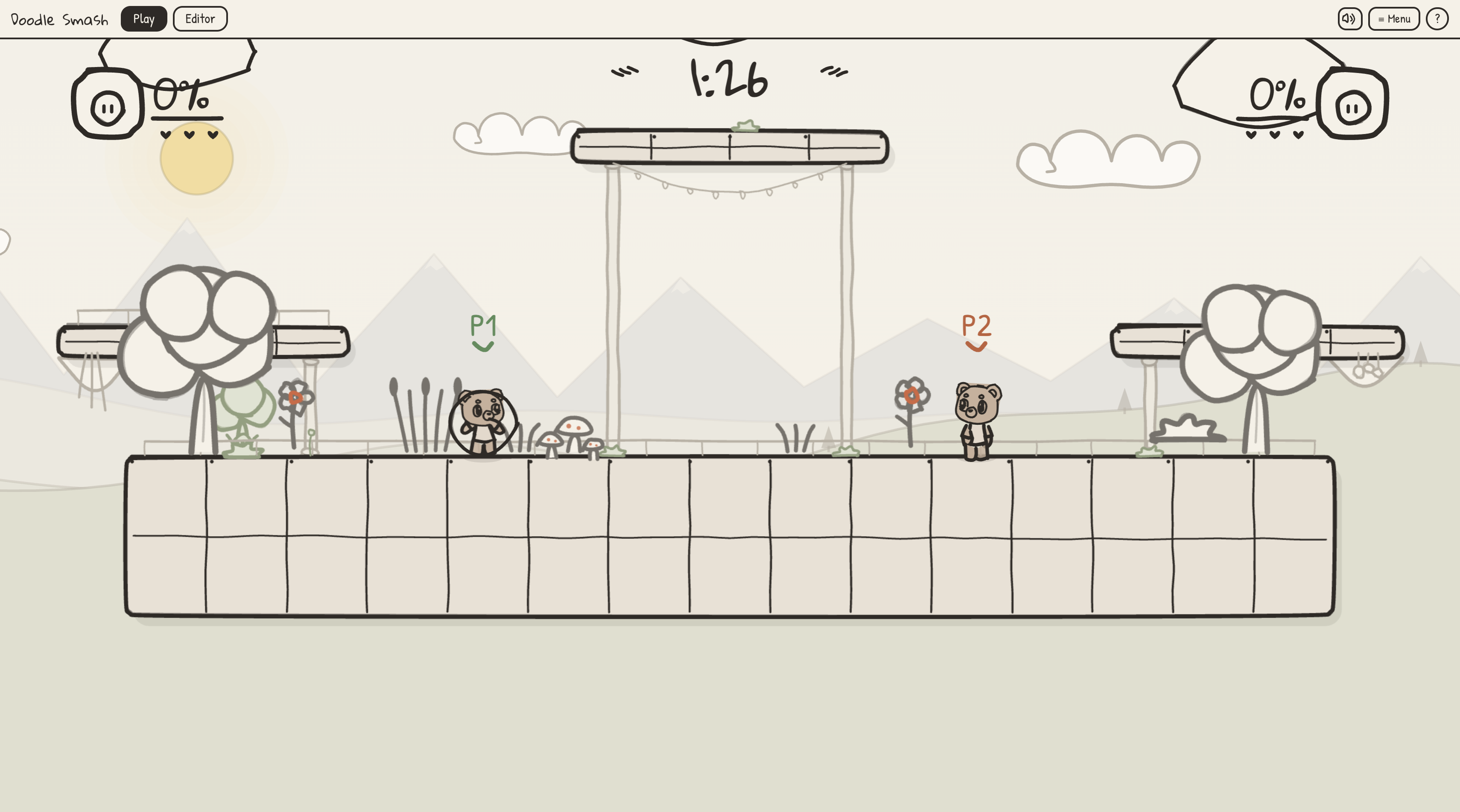
Variety of gamemodes to choose from
-
-
Draw --> Drag and drop --> Your doodle gets improved + our coder gives it game mechanics
-
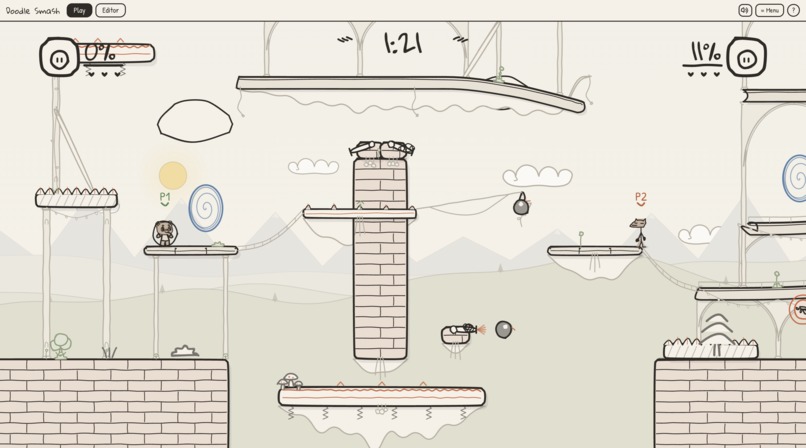
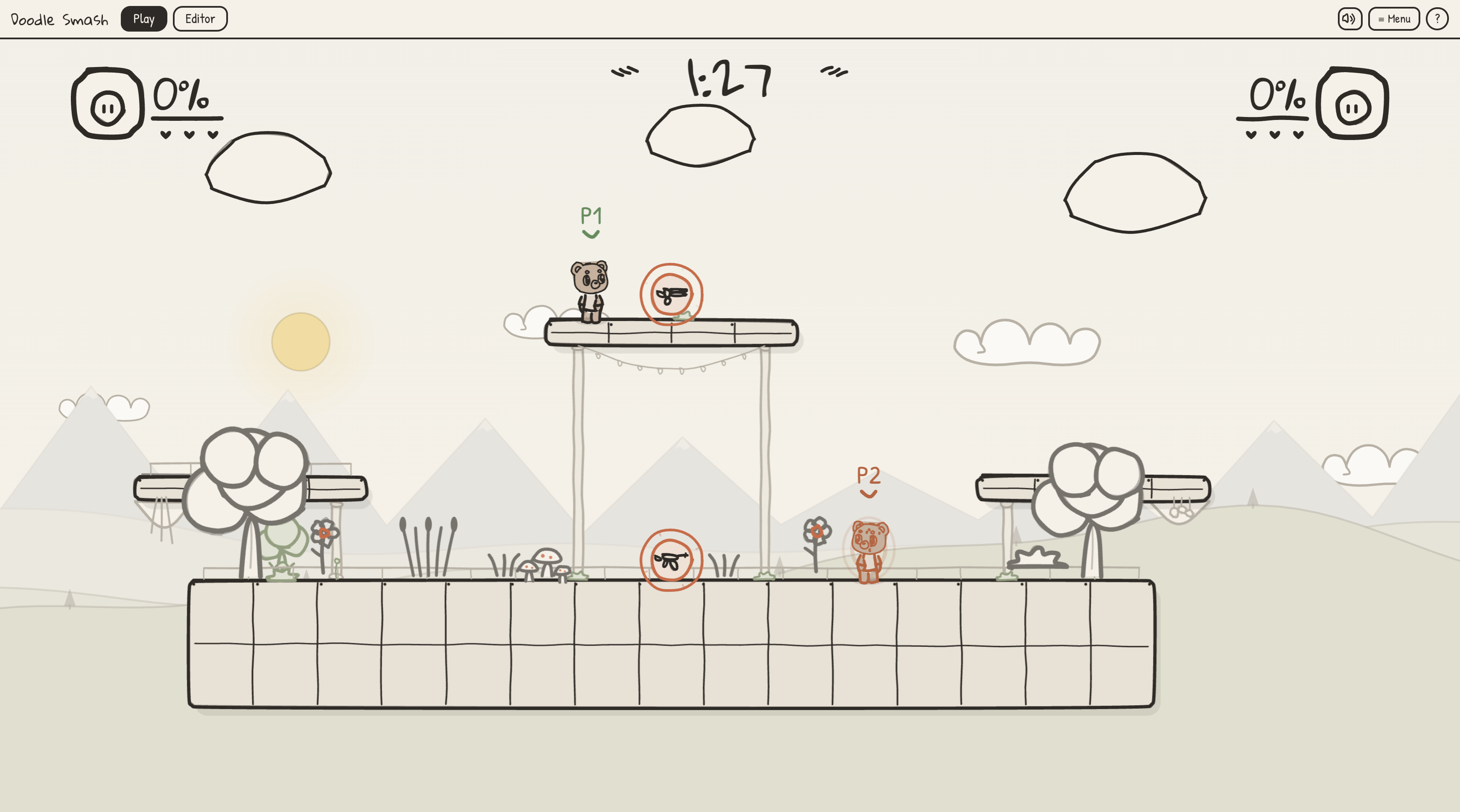
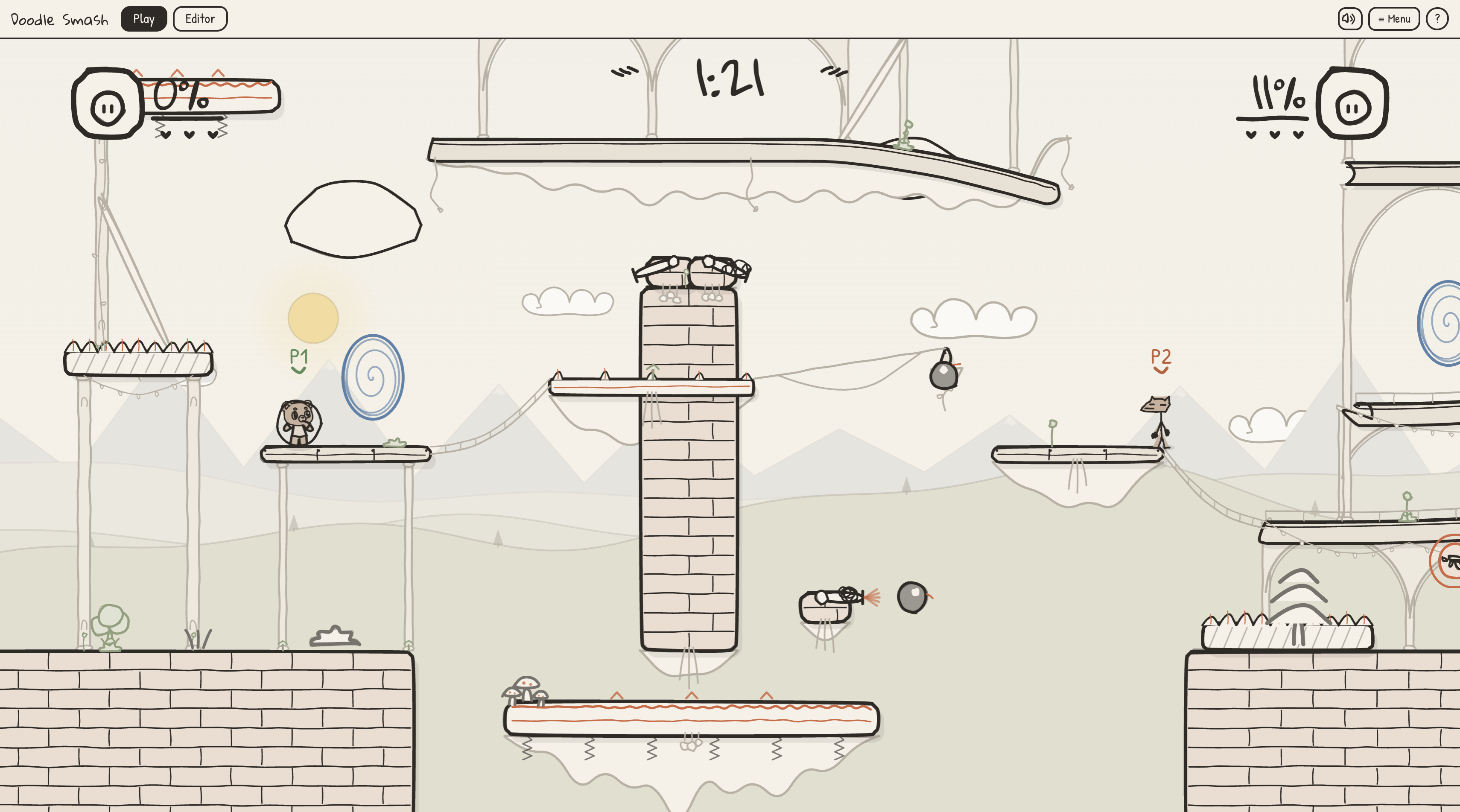
See your doodles come to life
-
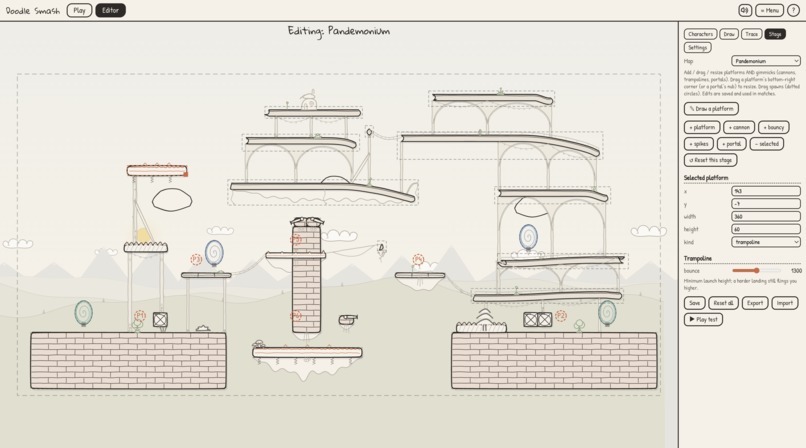
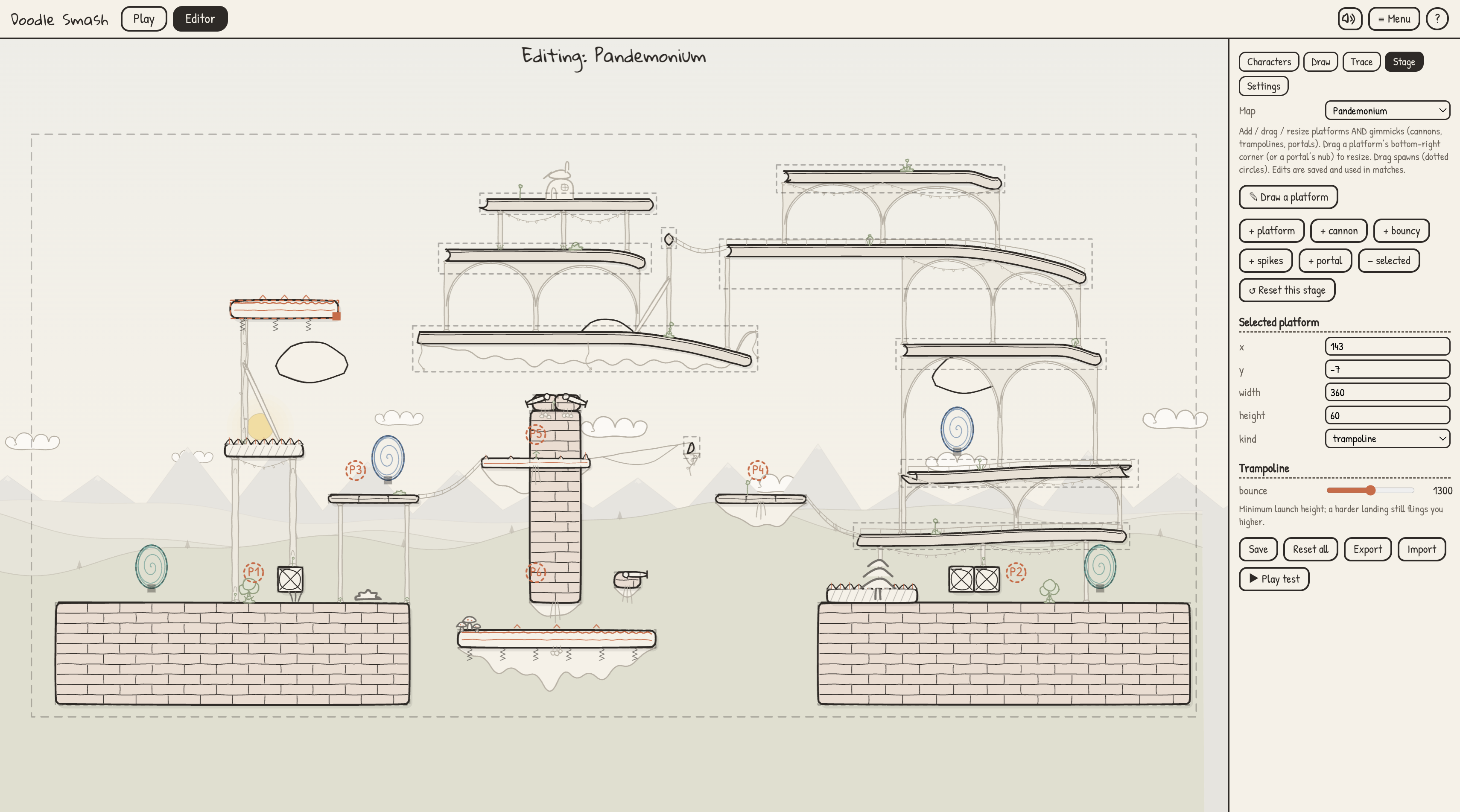
Create your own levels
Inspiration
Paper Cuts started from a simple belief: play is one of the best ways people learn to build. Today, most people grow up consuming games, videos, and apps, but far fewer get to create them. We wanted to make game creation feel less like opening a complex engine and more like drawing an idea on paper.
We are inspired by the creativity of childhood sketchbooks, playground games, paper prototypes, and the moment when someone says, “What if this was a level?” Paper Cuts is our attempt to turn that moment into something playable.
We do not want to constrain people to one game mode, one visual style, or one fixed idea of what a game should be. Our goal is to give people tools that make creation feel immediate, playful, and approachable.
What It Does
Paper Cuts lets people create playable game worlds by drawing, editing, and remixing game pieces. At its core, it is a creation-first game platform. Players can draw ideas on an iPad or browser canvas, turn those drawings into game objects, and then play inside the world they made.
The end-to-end loop:
- Draw a shape on the iPad canvas (or use a phone as a projector pen to draw directly into the shared scene).
- Recognize: a multi-tier perception stack names the drawing: a custom CNN fast-path for the common vocabulary, an open-vocabulary vision-language model for anything else, and retrieval-augmented recognition against a Redis vector memory of every doodle ever drawn.
- Enhance: the rough doodle is re-synthesized into a clean, on-style raster game sprite (label-conditioned image-to-image) and matted to a transparent asset, while preserving the kid's original shape.
- Compose mechanics: a neuro-symbolic composer turns the meaning of the drawing into actual gameplay: a sword swings, a drawn flame becomes a fire projectile that beats a drawn vine, a fruit heals, a star grants invulnerability, a spring launches you.
- Play: drag the object onto a live mini-map of the arena and it drops into the running match. Phones become gamepads via QR codes; the whole thing is built to be projected.
- Finish: the first item a fighter picks up imprints a generative cinematic finisher: a stylized KO sequence that ends the round in spectacle.
How We Built It
We built Paper Cuts as a multi-part web stack.
Web App
Game engine: vanilla JS + HTML5 Canvas. We deliberately avoided a heavyweight engine so we'd have direct control of the render loop, camera, physics, hitboxes, particles, and the procedural "marker-and-paper" art style (every stroke is drawn, never templated), with DPR-aware sizing for sharp projector output.
Drawing surface: React + Vite + tldraw. A first-class iPad/browser drawing experience: freehand strokes, shapes, labels, and touch, with platform reference overlays so you can draw onto the world.
Backend: FastAPI. Live rooms, drawing capture, semantic candidate generation, the clarification loop, generative-finisher jobs, the Paper Trail vector service, and WebSocket broadcasts.
Realtime layer: Node.js relay. Serves the game, mints QR codes, hosts phone-controller pages, runs the phone-as-gamepad WebSocket relay (lobbies, slots, input edges), and proxies backend routes.
AI Implementation
We run a small fleet of powerful, specialized models:
Recognizer — a multi-tier perception stack. A custom-trained CNN fast-path classifies the common vocabulary on-device in milliseconds; an open-vocabulary vision-language model handles true draw-anything recognition; and retrieval-augmented recognition (RAR) does k-NN vector search over our Redis doodle memory to recognize. The three are fused behind a single confidence-gated
recognize()call.Caecae — our drawing-to-asset visual model. A multi-stage image-to-image pipeline that takes a child's rough, shaky doodle and re-renders it as a clean, flat, bold-outline raster game sprite without discarding the original shape. The training stack was deliberately layered for reliability and fidelity:
- SD1.5 floor compile (guaranteed) — a Stable Diffusion 1.5 baseline that was certain to compile, as a floor we could always fall back to.
- SDXL primary compile in parallel — SDXL as the high-fidelity target, compiled concurrently so the floor never blocked the ceiling.
- Teacher dataset on Colab — we distilled a teacher dataset of doodle→sprite pairs on Google Colab.
- InstructPix2Pix fine-tune — an instruction-conditioned fine-tune so a label-based semantic hint from the recognizer steers the edit (it knows it's cleaning up a sword, not a snake).
- Fuse the best base → serve, then tune — model-merge the strongest base, ship it, and keep tuning online.
- Output is raster-sprite + rembg background stripping, yielding a transparent, drop-in asset. We trained Caecae on AWS Trainium (trn1) accelerators, but were unable to compile/serve the model on them.
Moose — a neuro-symbolic mechanic composer. Instead of letting a black-box model rewrite our game, Moose composes mechanics from a safe-by-construction operation graph (operations × triggers × element tags). A LoRA-tuned model proposes the intent of a drawing; the graph guarantees a valid, non-crashing, balanced mechanic. Interactions (fire melts ice, fire burns through vines, water douses fire) are generated on the fly with element-tag algebra.
Asset isolation pipeline. Generated sprites pass through saliency-based matting (rembg / BiRefNet) and a connected-component "keep-largest" pass that strips backgrounds and stray decoration blobs, yielding clean transparent assets that drop straight into the scene.
Generative finishers. The first item a fighter grabs imprints a cinematic KO, generated with a generative-video model (Pika via fal.ai) styled to the characters and scene, then cached and pre-baked so the spectacle lands with zero in-match latency.
Paper Trail — Redis as our vector brain (sponsor track)
Every doodle anyone draws is embedded and written into a Redis Stack (RediSearch) HNSW vector index alongside its confirmed label, composed mechanic, and a thumbnail — a living, shared visual memory of every drawing.
Today that memory powers Retrieval-Augmented Recognition (RAR): a new drawing is embedded and recognized by k-NN vector search over the community's collective memory, so recognition gets smarter and cheaper the more people play — and we lean on the expensive, high latency VLM less and less. Redis is our vector brain and agent memory, not a TTL cache: RediSearch HNSW does the similarity search, and the doodle index is the model's long-term memory.
The same vector memory is built to power "Déjà Draw" remixing and cross-room mechanic consistency for Moose; see What's Next.
Realtime, multi-device coordination
The desktop game has its own camera, zoom, and world coordinates; the iPad has a completely separate canvas. We built a coordinate-reconciliation layer so a stroke drawn over a platform reference lands pixel-correct in the real game world, and a WebSocket fan-out so phones-as-controllers, phones-as-pens, and the host screen all stay in lockstep.
Challenges We Ran Into
Training Caecae on Trainium. Getting Caecae to compile and train on AWS Trainium was a real fight, the toolchain had many unforgiving nuances. We hedged with a layered compile strategy: an SD1.5 floor that was guaranteed to compile while the SDXL primary compiled in parallel, a teacher dataset on Colab, an InstructPix2Pix fine-tune fused onto the best base, then serve-then-tune. We ultimately ran out of Trainium access before serving the full SDXL weights at our target latency, so we swapped in hosted inference for the live demo while keeping the trained pipeline intact.
Latency vs. quality. Turning a doodle into a beautiful asset and a fast asset pull in opposite directions. We chased sub-500ms enhancement, profiled diffusion paths (including on-device distilled variants), and learned exactly where the quality/latency cap is for flat 2D art on custom trained models. We were also forced to introduce clever latency masking features after running out of Trainium access.
Keeping the doodle a doodle. Generative models love to add realistic shading, depth, and motion at the cost of time. Preserving the crisp, flat, hand-drawn aesthetic through image-to-image (and especially generative-video) took heavy prompt constraint, strength tuning, label-conditioning, and rembg post-processing.
How much should the AI control? We refused to ship a black box that silently mutates the game, so we built a clarification loop — the system proposes candidates, the player confirms or corrects and made mechanics safe-by-construction so a quick wrong guess never causes a crash.
Redis as memory, not cache. Designing the doodle embedding, the RediSearch HNSW schema, and the retrieval-augmented recognition vote (so the vector memory improves recognition without ever blocking the game) was a difficult part of integration.
Coordinate systems across devices. Reconciling the iPad canvas, the projector world, and phone inputs into one coherent, drift-free scene was a surprising amount of math.
Orchestrating a fleet of models. Recognizer, Caecae, Moose, the generative-video finisher, and the Paper Trail vector service (plus graceful degradation when any one is slow, rate-limited, or offline).
Accomplishments That We’re Proud Of
- A real draw → recognize → enhance → compose → play loop that feels like magic.
- A multi-tier, open-vocabulary recognition stack — CNN + VLM + retrieval-augmented recognition over a Redis vector memory.
- Caecae's layered diffusion training stack (SD1.5 floor + SDXL primary, Colab teacher set, InstructPix2Pix fine-tune, model fusion) on Trainium.
- Moose's neuro-symbolic, safe-by-construction mechanic composition — AI creativity with deterministic guarantees.
- Paper Trail — a living Redis (RediSearch HNSW) vector memory of every doodle that powers retrieval-augmented recognition.
- A character system where custom sketches animate through the same rig as the built-in cast.
- Generative cinematic finishers that turn a KO into a moment.
- Custom maps, portals, hazards, cannons, bouncy platforms, and breakable objects.
- Phone-as-gamepad and phone-as-projector-pen multiplayer over QR codes.
Most importantly, we are proud that the project feels playful and isn't boring. You can draw something, make a choice, and see it become part of a game world.
What We Learned
We learned that making creation feel simple requires a lot of structure underneath.
We also learned that game creation tools should not start with complexity. Most engines ask people to think like developers before they can play. Paper Cuts tries to reverse that: start with play, drawing, and imagination, then gradually expose more power.
Technically, we learned a lot about real-time sync, WebSockets, canvas rendering, semantic object detection, structured game patches, and multi-device workflows.
What’s Next For Paper Cuts
Next, we want to expand Paper Cuts from a single playable prototype into a broader creation platform.
The next steps are:
- Support more game modes beyond the current platform-fighter demo
- Let creators choose or define different art styles
- Add richer character creation and prop refinement
- Let users build rules, win conditions, pickups, enemies, and hazards
- Add better world saving, sharing, and remixing
- "Déjà Draw" discovery & remix and cross-room mechanic memory, built on the Paper Trail vector index — surface and remix kindred community creations.
- Collaborative multi-author creation and richer world saving, sharing, and remixing — scaling the Paper Trail vector memory into a global, cross-session creation graph.
- Create a smoother “draw → clarify → playtest” loop
- Add collaborative creation, where multiple people can draw and edit together
The long-term dream is that Paper Cuts becomes a bridge from imagination to interaction. Instead of only consuming games, people can sketch, remix, test, and play their own ideas.
Built With
- aws-trainium
- birefnet
- cnn
- diffusion-models
- fal.ai
- fastapi
- generative-video
- google-colab
- hnsw
- html5
- image-to-image
- instructpix2pix
- lora
- model-fusion
- neuro-symbolic-ai
- node.js
- openai
- pika
- python
- pytorch
- qr
- rag
- react
- redis
- redis-stack
- redisearch
- rembg
- sd-1.5
- sdxl
- stable-diffusion
- tldraw
- vanilla-js
- vector-search
- vision-language-models
- vite
- websockets










Log in or sign up for Devpost to join the conversation.