About PantryPilot
Inspiration
I opened my fridge one Sunday night, found a bag of spinach that had been on the shelf for nine days, and threw it out. That single bag wasn't dramatic — but the USDA says the average American household does this routinely, wasting roughly $1,500 of groceries a year. Globally, the UN puts food loss and waste at ~30% of all food produced, responsible for ~8% of greenhouse-gas emissions.
The annoying part: most of that waste isn't spoilage, it's forgetting. Recipe apps assume you already know what's in your kitchen. Calorie trackers assume you'll type every item. Nobody closes the loop between "what I bought" and "what I should cook tonight before it goes bad."
PantryPilot is that loop. Snap a receipt, the agent does the rest.
What it does
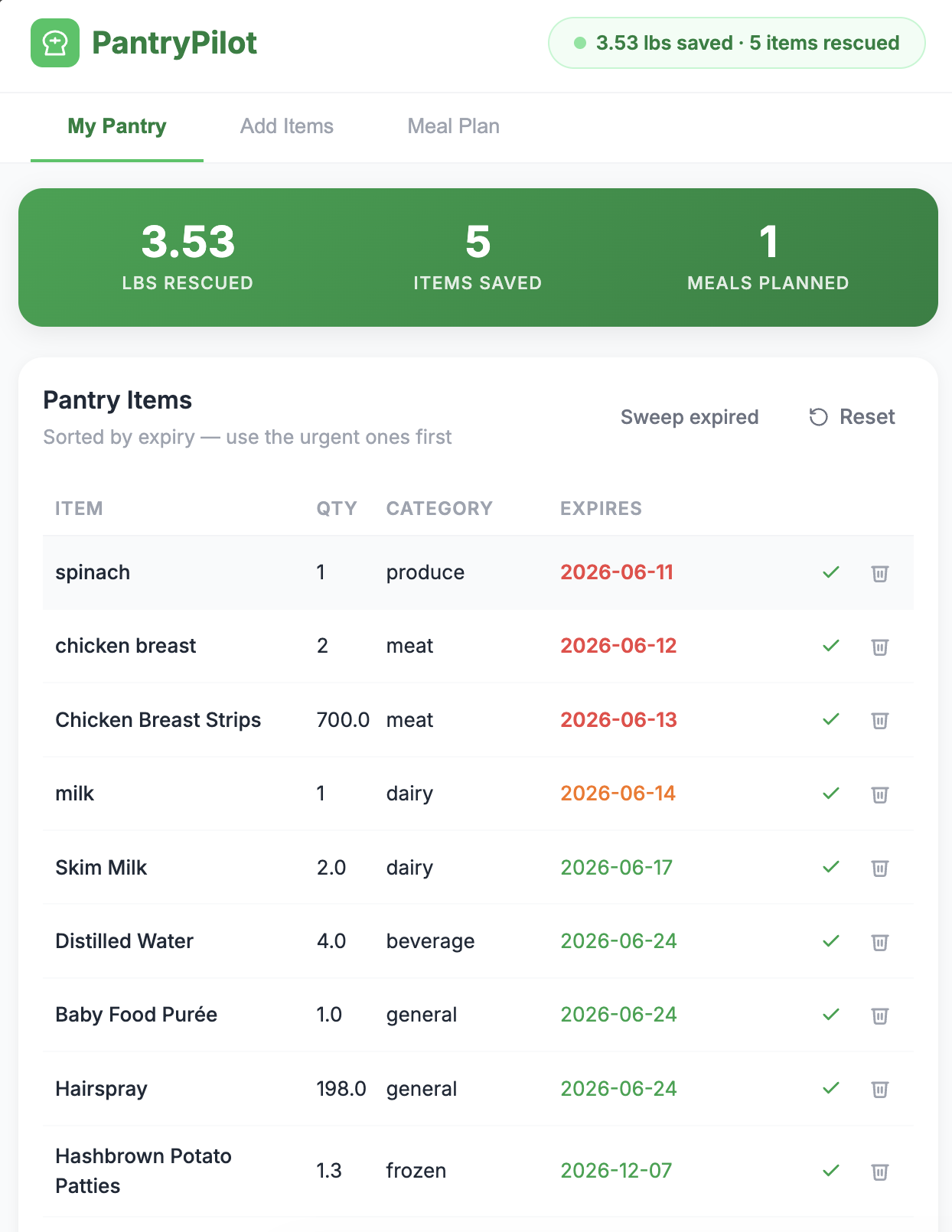
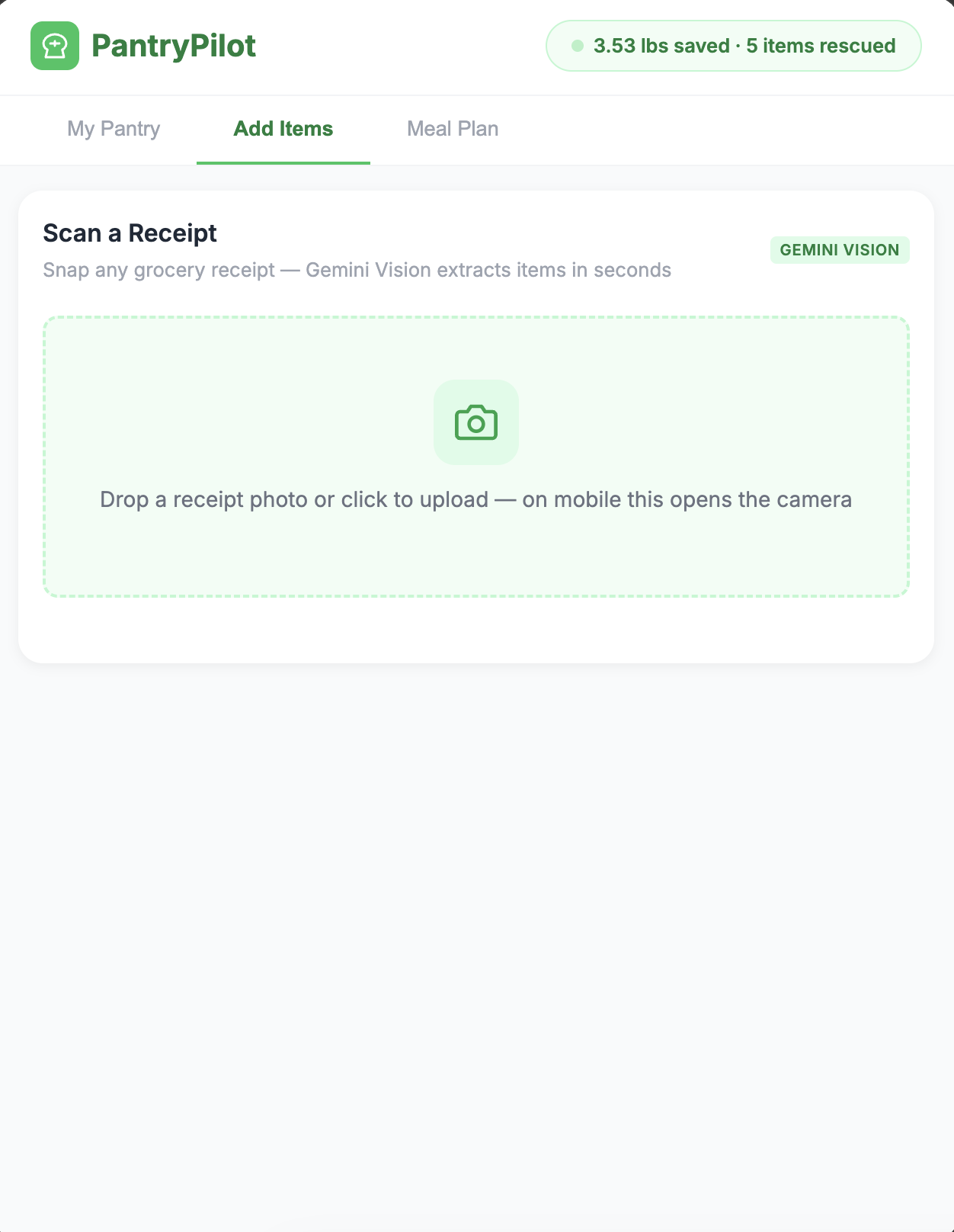
- Ingest — Drop a grocery receipt photo. Gemini Vision OCRs it into structured items; a category-aware shelf-life table fills in expiry dates.
- Track — Items live in MongoDB Atlas, sorted by
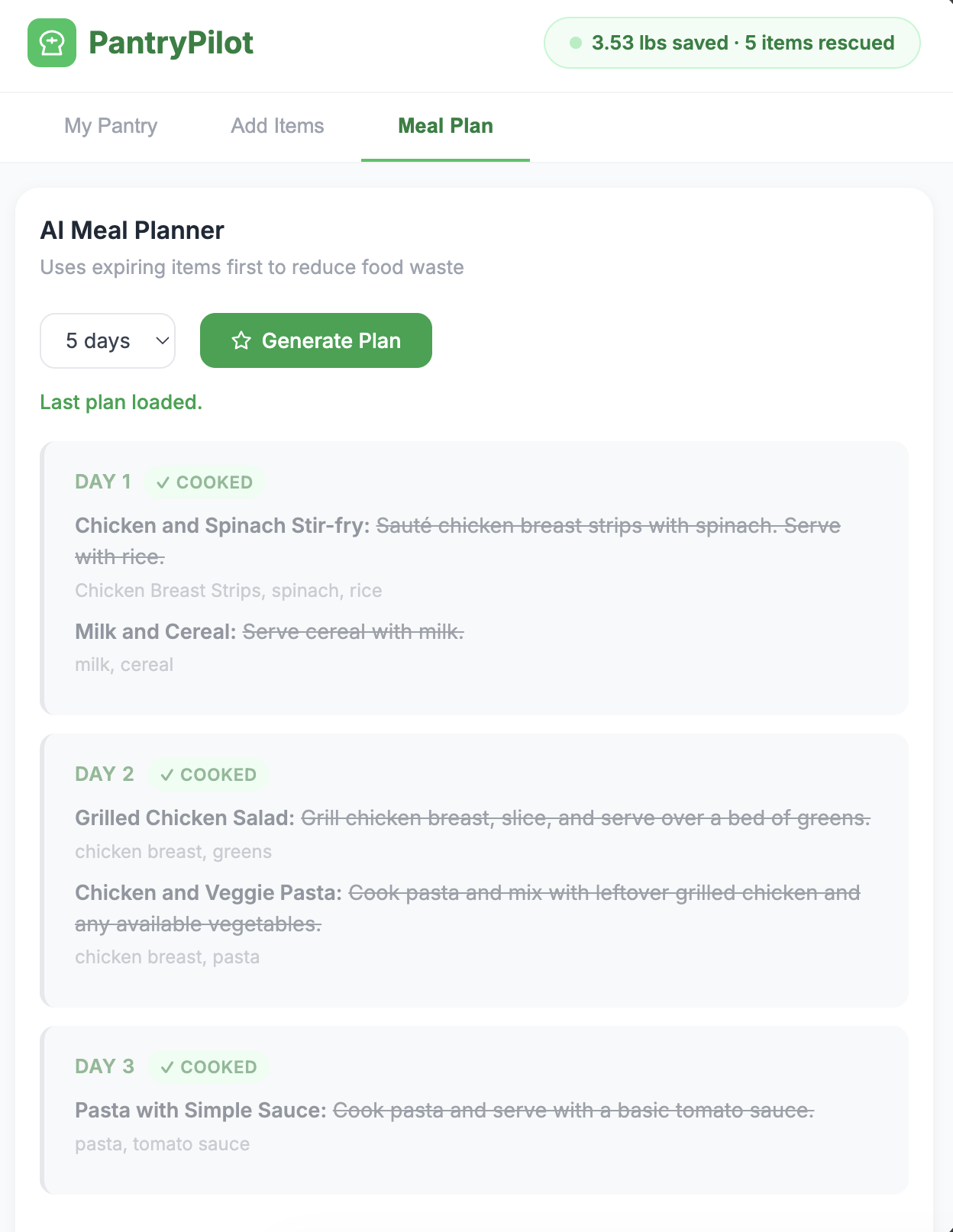
expires_atand colour-coded in the UI (red ≤ 2 days, orange ≤ 5, green otherwise). - Plan — A Google ADK agent on
gemini-2.5-flashreads the pantry, identifies priority items, drafts an N-day meal plan that cooks those items first, and writes the plan and waste-saved events back to Atlas. - Close the loop — Mark a day as cooked. The pantry shrinks, the lbs saved badge ticks up.
How I built it
Stack
| Layer | Choice |
|---|---|
| Backend | FastAPI 0.136 + uvicorn, Python 3.13 |
| Frontend | HTMX 2.0 partials + a thin app.js (no SPA framework) |
| Agent | Google ADK 2.1, model gemini-2.5-flash, four FunctionTools |
| Database | MongoDB Atlas via motor (async) |
| Partner MCP | Official mongodb-mcp-server as a Cloud Run sidecar on :3001 |
| Vision | Gemini Vision for receipt OCR |
| Deploy | Google Cloud Run, region us-central1, 2 GiB RAM, 1 CPU |
Architecture
The same Atlas cluster is reached two ways:
- The FastAPI hot path uses
motordirectly so every HTMX partial render avoids a JSON-RPC hop. - The official
mongodb-mcp-serverruns as a sidecar so any MCP-aware client (Claude Desktop, an external ADK agent, a future Slack bot) can read/write the same data — that is the partner integration surface.
The data layer keeps the original mcp_* function names (mcp_find, mcp_insert_many, …) so the two transports stay interchangeable.
The agent prompt
The system prompt is opinionated:
- Call
read_pantry().- Identify items expiring within 5 days — these are PRIORITY ingredients.
- Draft an N-day plan that uses priority ingredients on Day 1 and Day 2.
- Call
save_meal_plan()andrecord_waste_saved()per priority item.- Respond with one final JSON message — no prose, no markdown fences.
The expiry model
The shelf-life lookup is a simple per-category table indexed by storage condition. For an item with category \(c\) stored under condition \(s\), the projected expiry date is:
$$ \text{expires_at}(c, s, t_0) \;=\; t_0 \;+\; \Delta(c, s) $$
where \(t_0\) is the time of ingest and \(\Delta(c, s)\) comes from expiry_days.json (e.g. produce/refrigerator = 5 days, meat/freezer = 90 days).
The waste-saved metric
When the agent uses a priority item in a meal, it estimates rescued mass by category. For a plan with priority items \(\mathcal{P}\):
$$ W_{\text{saved}} \;=\; \sum_{i \in \mathcal{P}} g_{\text{cat}(i)} $$
with \(g_{\text{produce}}=200\)g, \(g_{\text{dairy}}=500\)g, \(g_{\text{meat}}=300\)g, \(g_{\text{condiment}}=100\)g, \(g_{\text{other}}=400\)g. Imperfect, but enough to make the impact tangible in the UI without asking the user to weigh anything.
Challenges I ran into
1. The agent kept returning prose instead of JSON
ADK's Runner emits a stream of events: tool calls, intermediate model thoughts, and a final response. My first implementation only collected text from event.is_final_response() events — but gemini-2.5-flash sometimes ended a turn with a tool call event and no trailing text part. That produced an empty final_text and a 500 from /plan.
Fix: accumulate text from every event, fall back to that buffer when the final event has no text, and tighten the system prompt to mandate "your final message MUST be a single JSON object — do not end the turn with only tool calls."
2. Cloud Run cycled 503s on long requests
I had uvicorn --reload enabled in the container. WatchFiles in --reload mode cycles workers on its own filesystem activity, which kills in-flight requests — fatal for a 30-second agent run.
Fix: drive reload via env var (UVICORN_RELOAD=1 only locally) and always run the production container without it.
3. Cloud Run rejected my smoke-test POSTs with HTTP 411
Cloud Run's frontend requires a Content-Length header on POST. curl -X POST with no body omits it.
Fix: curl -X POST --data '' in smoke.sh. Tiny, easy to miss, broke every CI check until I traced it.
4. The Safari double-click receipt bug
The upload zone was a <label for="receipt-file"> with the <input> nested inside. Safari/iOS double-fires the file picker in that arrangement (the label-for opens it, then the bubbled click on the input closes it). Picker opened then immediately cancelled.
Fix: keep the nested input, remove the for= attribute. Click bubbling alone is enough and Safari only fires it once.
5. URL-import was a tar pit
The original plan included Bright Data MCP to scrape any retailer URL into items. Public category pages are SPA shells; private cart pages are login-walled. After two days of fighting it I cut the feature, deleted ~150 lines of dead code, and rewrote the README/demo around receipt OCR. Killing scope is a feature.
6. Type collision on gcloud run deploy --set-env-vars
The service had GOOGLE_API_KEY bound as a Secret Manager reference. A later --set-env-vars deploy tried to overwrite it as a plain literal and Cloud Run refused: "Cannot update environment variable to string literal because it has already been set with a different type."
Fix: either redeploy without touching env (secret binding carries over), or --remove-secrets first and re-add as a literal. Documented both paths so I don't trip on it again.
What I learned
- MCP is a discipline, not just a library. The honest way to claim a "MongoDB MCP integration" is to actually run the official server and let an external client talk to it — not to wrap
motorcalls and rename themmcp_*. I do both, and the README says so. - Cloud Run rewards boring choices. No queues, no Pub/Sub, no Cloud Tasks. One container, one sidecar, one cluster. Total infra spec in YAML: ~20 lines.
- HTMX is genuinely faster than a SPA for this kind of app. Every interaction is one round-trip that returns an HTML partial. No build step, no hydration, no client-side state machine. The agent's plan render is ~3 KB of HTML, not a JSON blob the client has to template.
- Agents need brutally explicit output contracts. "Respond with JSON" is not a constraint; "your final message must be one JSON object with these exact keys, no prose, no markdown fences" is. Even then, defend the deserialiser with a fallback.
- The reflog will save you. A misfired
git reset --hard origin/mainlooked catastrophic and was a 30-second fix.
What's next
- Multi-week patterns. Aggregate
waste_saved_eventsto surface which categories the user habitually over-buys (e.g. "you've thrown out cilantro 4 times this month"). - Push notifications. Cloud Scheduler → Cloud Run job → web push when high-priority items hit 24h to expiry.
- Voice ingest. Whisper + Gemini for "hey, I just bought a bag of carrots and two yogurts" on the way home from the store.
- Family sync. One Atlas document, multiple devices, optimistic HTMX updates with
Conditional GET.
Live demo: https://pantrpilot-833993910148.us-central1.run.app
Source: https://github.com/faketut/PantryPilot


Log in or sign up for Devpost to join the conversation.