-
-
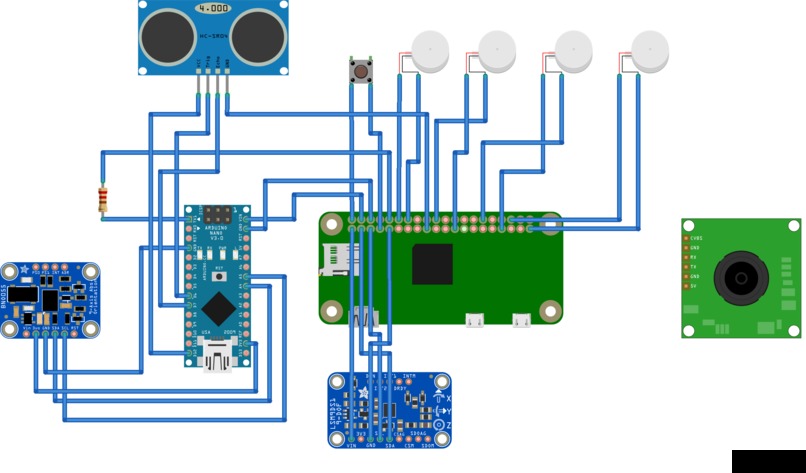
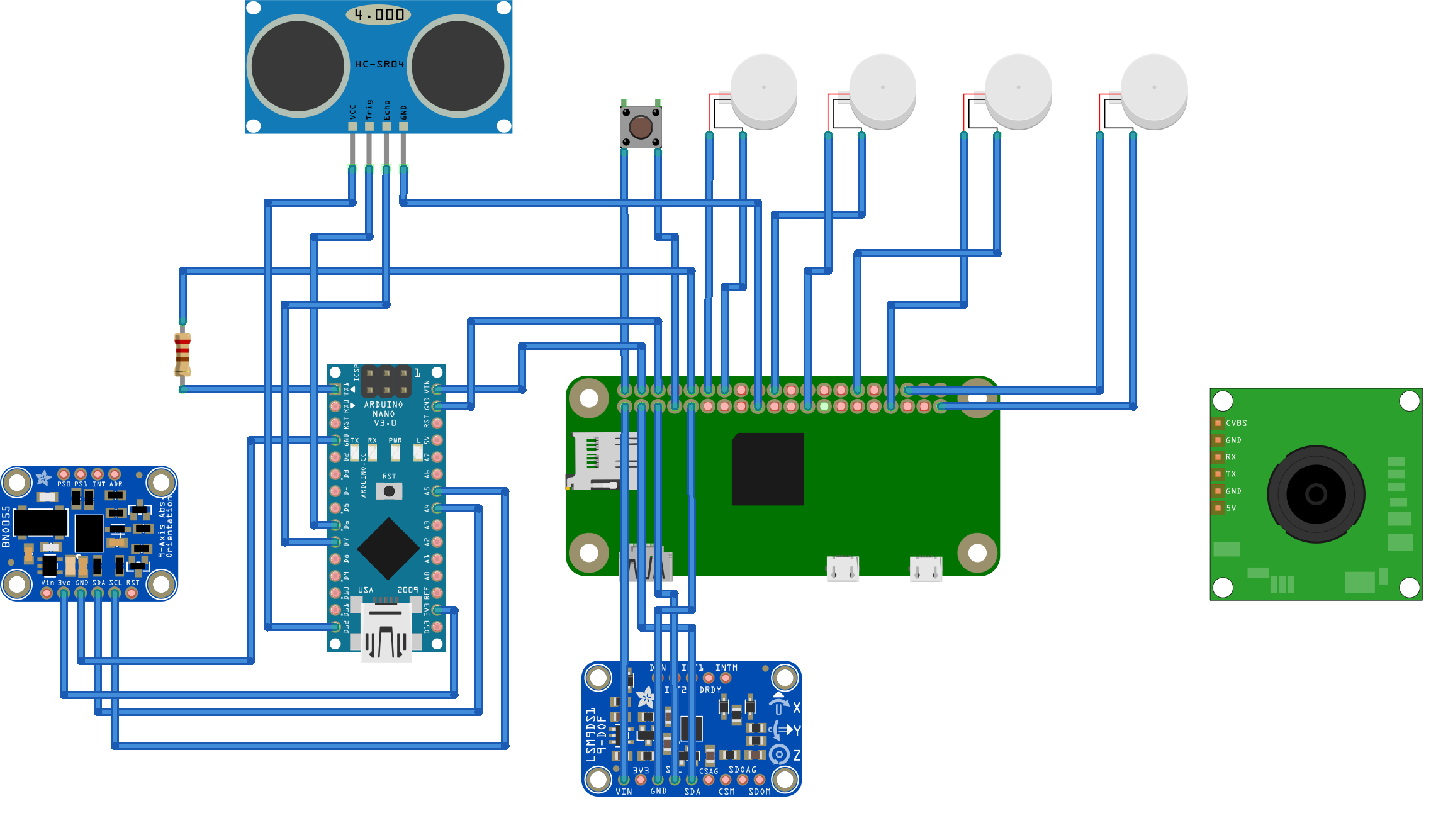
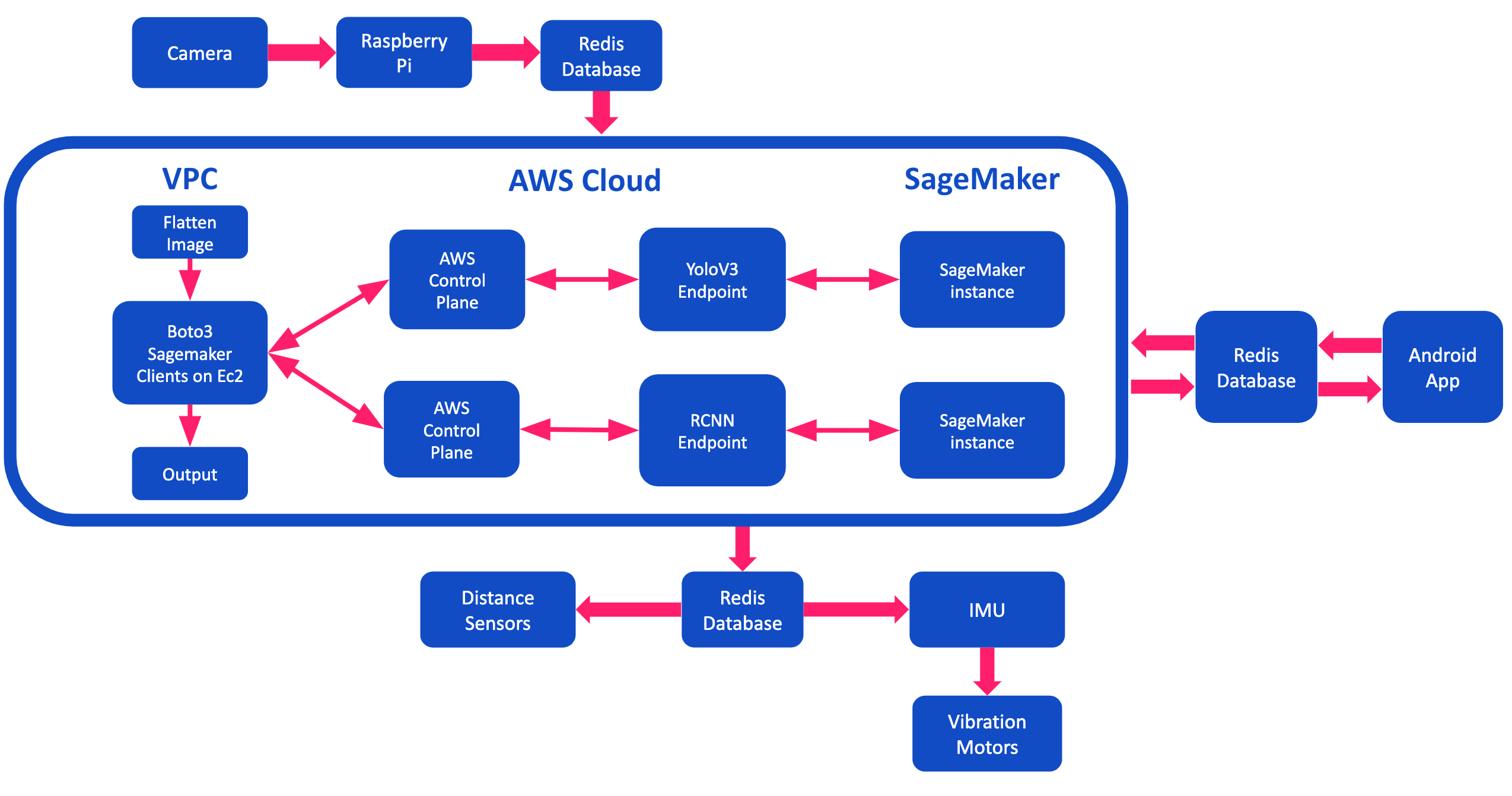
A diagram of the circuits
-
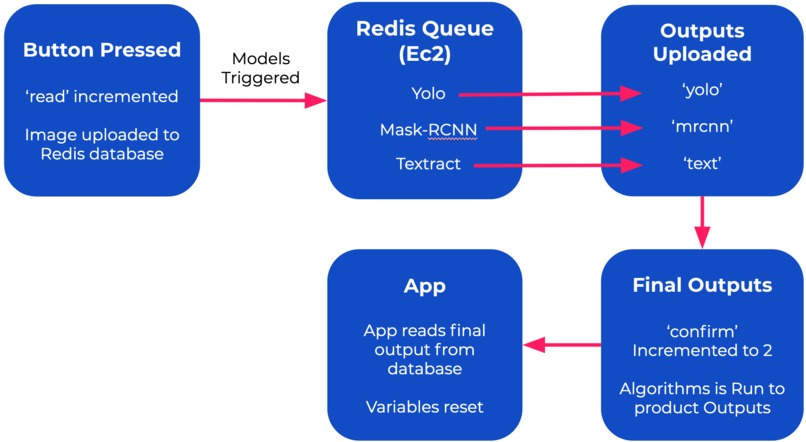
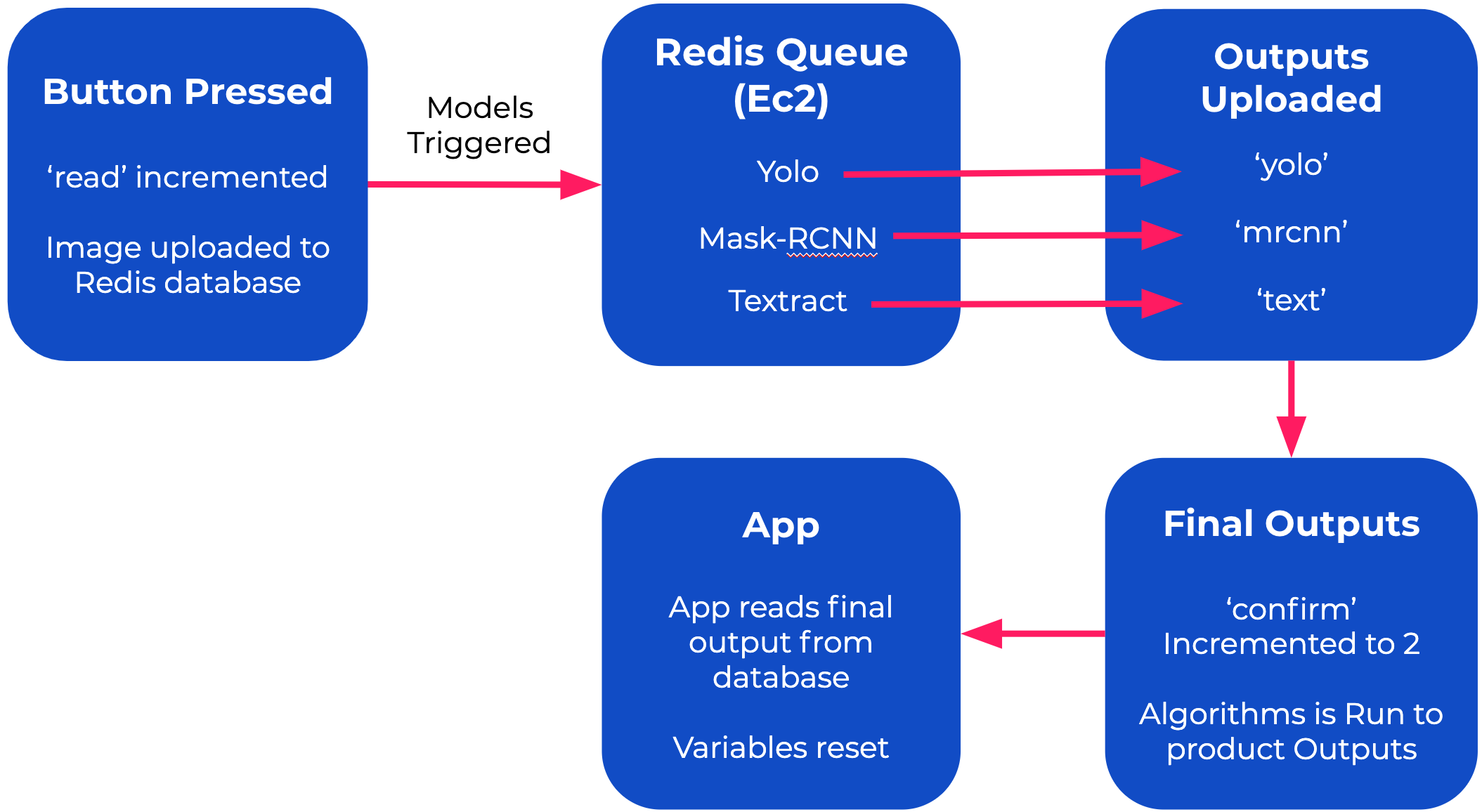
Diagram of how we use Redis - the things in quotes represents the Redis implementation for each computer vision model.
-
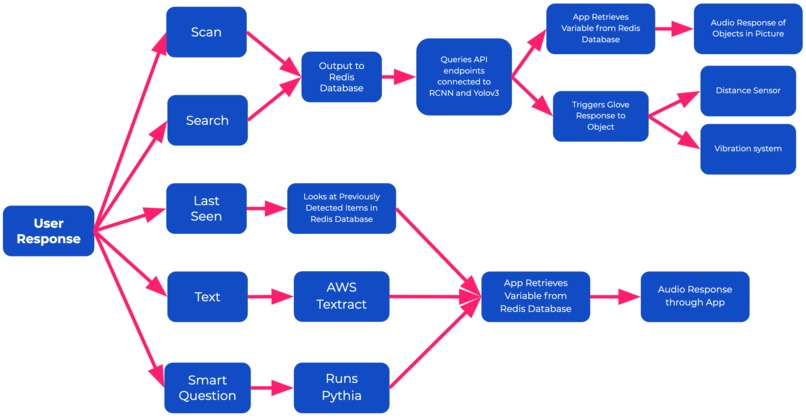
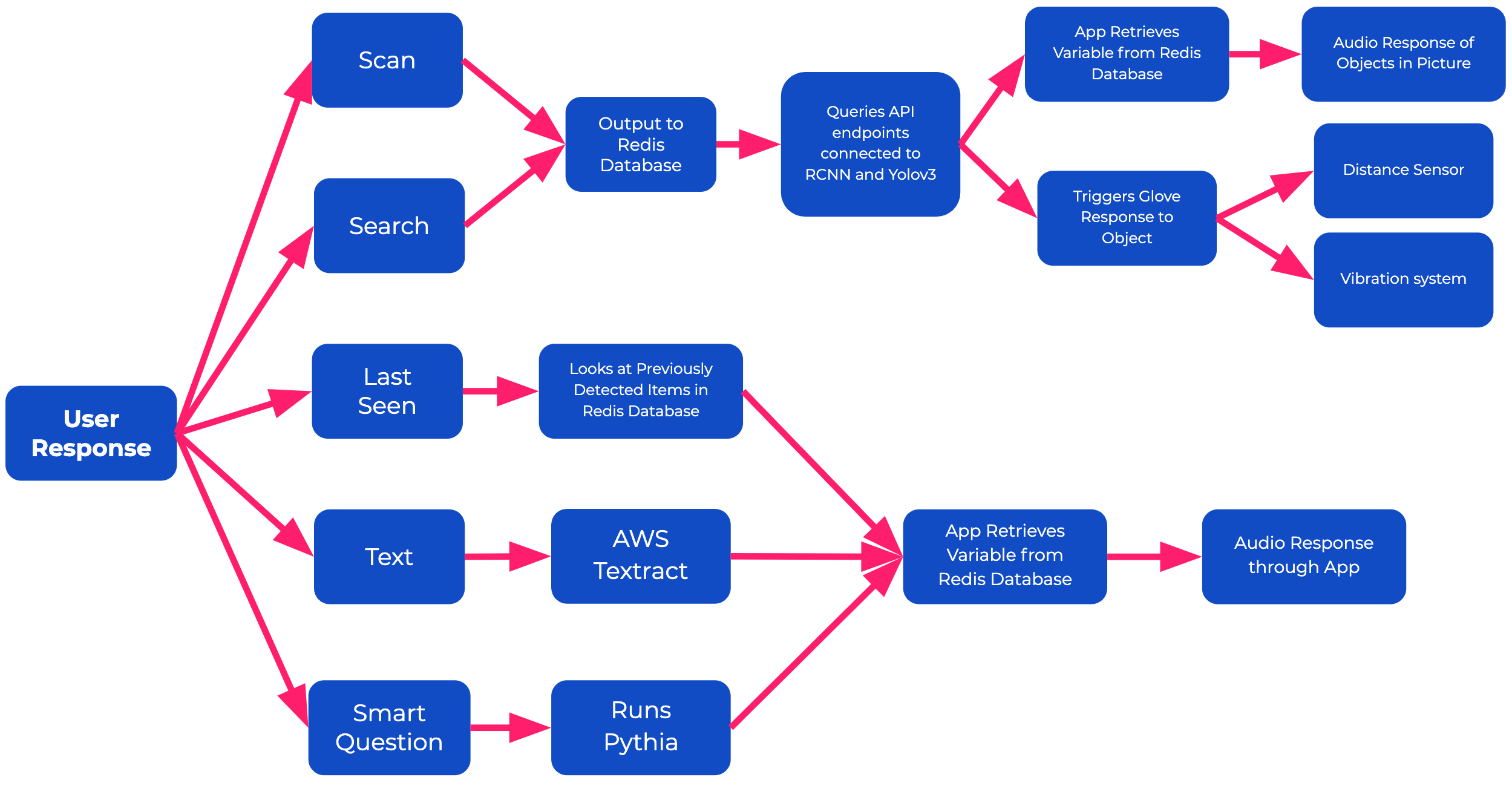
Diagram of all of our features and how Redis is implemented at every level for communication between all of our interfaces.
-
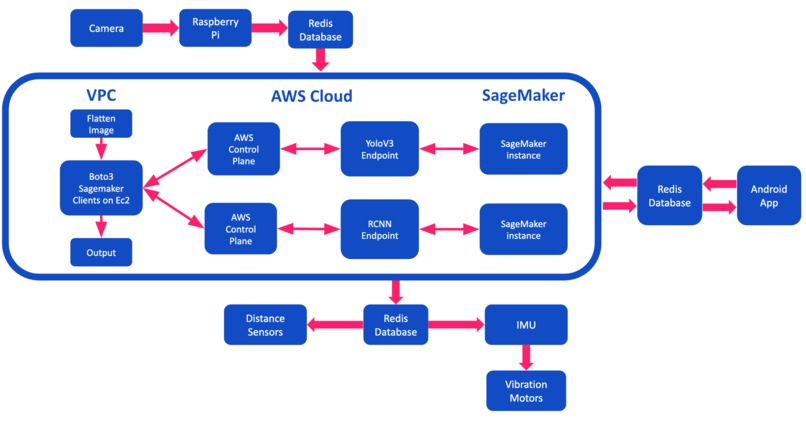
Diagram of how search works. At each step Redis allows all of our interfaces to communicate.
-
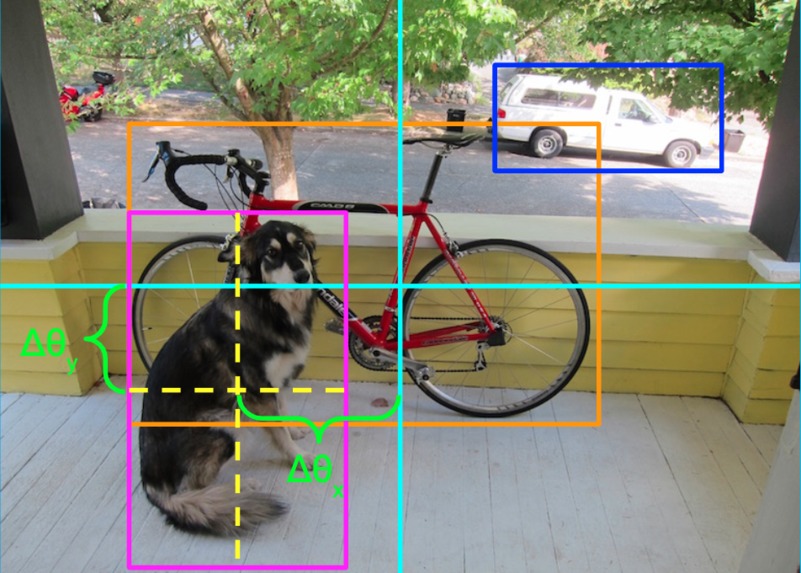
An example of how we designed the search mechanism to work.
-

An overhead, back, and frontal view of the device.


Inspiration
When we first began delving into machine learning and CV last summer, our first project was a simple object detection app. Now, using the tools from AWS and Redis Enterprise, we wanted to take use of object detection to the fullest with a completely new and innovative project. When we began researching the use of CV to help the visually impaired, we realized that the products in this field could be improved. Many of the solutions were simple apps that read out what was in front of the phone, while some companies built wearables that were in the hundreds to thousands of dollars. There are over 289 million people who are visually impaired worldwide and we believe, with our product, we can make their lives a bit easier.
What it does
The PalmSight is a glove that serves as a visual aid for the blind and works with a mobile app. The glove has a camera and a Raspberry Pi Zero W embedded in the back of the hand. To use it, the user a the back of their hand towards their surroundings and presses the button on the side of the glove to take a picture. Using Redis Bitfields and Strings, the image and appropriate user data is sent to an Ec2 instance where, using several AWS models and services, it stores a list of the objects surrounding the user, any text, and the location of each object. This data is also stored in a log so that the user can search for it. Using this data, the user can choose 1 of 5 features through the mobile app. To activate the feature, they must say its name and a specific object if necessary. The features are:
The Scan feature simply relays what the user’s surroundings are, along with the count of each object. For example, “1 table, 1 laptop, and 3 cups detected.”
The Text feature reads out any text in the picture. It first says the surface the text was detected, such as a sign or a book, then the actual writing. For example, “The sign says, “No parking”.
The Observations feature takes questions that look for the detail in the image. For example, “Is there a car in front of the building?” or “What is the value of the coin on top of the paper?”.
The Search feature guides users towards the desired objects which they choose through audio input. Each detected object is accompanied by an x and y degree separation in relation to where the picture was taken. As soon as the picture is taken, the IMU built into the sleeve begins to track the user’s movement. This way, it calculates how far left, right, up or down the user has to move to be aligned with the desired object. To guide the user, vibration motors on the top, bottom, and both sides of the wrist vibrate to signal the user where to move. As the user gets closer to the object, the vibrations intensify until the user presses the button again to signal that they have located the object. Of course, moving in with the motors might be dangerous in some environments, as the user may collide with obstacles. To prevent this, an infrared sensor below the camera alerts the user when they are within 1.5 ft of an object with the audio producing, “collision alert” and then “safe distance” once the user has backed away.
The Last Seen function asks the user for an object and then returns the time, place, and location the object was last seen. The detected objects for every picture are stored in the database, along with the time taken and the location of the phone. Using a search algorithm, the app is able to detect the latest log containing their object.
How we built it
The PalmSight performs object detection by using the AWS GluonCV Faster-RCNN Object Detector and the AWS GluonCV YOLOv3 Object Detector. To make the final output more accurate, we employed a technique similar to an Ensemble Learning technique called stacking. Stacking is a technique where base model predictions are combined through a meta-classifier. In our case, the base models were the Yolov3 and Faster -RCNN models. Both ran simultaneously and their outputs, the objects’ name, respective accuracy, and location in the image, were stored in a set of Redis variables. Redis uses in-memory storage, making it easier to store and retrieve data within the Ec2 instance as opposed to storing it in SSD. The outputs of both models are then sent to a network of filters that serves as our meta-classifier. This data was used for the scan and search functions of the glove. For the text function, we used the AI Amazon service Textract to detect and read any text within the image. We deployed and configured the models using Amazon SageMaker. To simplify the process, we used Amazon’s SDK for Python, Boto3. Using the Boto3 clients for Sagemaker and Sagemaker-runtime, we were able to construct, configure, and utilize those API gateway endpoints at any time. When the raspberry pi takes a picture, it sends the image to our Redis cloud enterprise database. The Ec2 instance then detects this change and makes an inference on both of the endpoints previously generated in the process, creating a JSON consisting of the objects’ name, respective accuracy, location in the image, and any text found within the image. The contents of the JSON file were stored in Redis cache where they were then read by the mobile app and raspberry pi.
Because we run multiple models in parallel, we use Redis to communicate between the scripts since they run independently of each other. We used the Redis database to store our variables across our 3 interfaces, the raspberry pi, the app, and the server. We stored the outputs and entries of the outputs of our server in the database The entire process begins when the user clicks a button on the side of the glove. As soon as that occurs, an image is captured and uploaded to the Redis database through a byte field. When the image finishes uploading, it changes a Redis variable, called “read”, which triggers all the models to process the images. This all happens while the user is in the process of giving the instructions. We do this so that the outputs are ready by the time the user finishes the instructions, decreasing the perceived loading time. Since the models all run at slightly different times, we have another Redis variable called “confirm” which tracks the progress of models. When each model is run, they each independently increment “confirm” by 1. Also, the outputs from each model are saved in Redis under the name of the model. Since there are 2 models, if “confirm” equals two, we know that both models have run. When “confirm” equals two, the meta-classifier script is triggered, which processes the outputs from all the models through several filters. After the script finishes running, and uploads its output to the Redis database, it increments “confirm” one last time, which triggers another event in the app, making it read out loud the outputs saved in the redis database. This also triggers all the variables to reset so that it can be run again. To manage all these processes simultaneously and efficiently, we utilized Redis’ unique enque service and multithreading. First, we created two threads to check if there was a state change in any of the Redis variables, such as ‘confirm’ and ‘read’, and then used the other thread to manage the queue. The queue contained jobs such as the AI services and methods such as, YoloV3, FasterRCNN, Textract, and were only processed when a state change in the “read” variable occurred. Thanks to Redis’ queue service, we were able to simplify the process needed to manage all our machine learning services.
The app was built on Android Studios and allowed the user to select which function they wanted to use. We put a listener that would use the Google speech-to-text API that would prompt the user for a voice. We set an array of keywords that would match a function, so a command containing the word “scan” would pull the outputs of the meta-classifier from the Redis database and use the Android text-to-speech API to give an audio output. If the user calls the search function, the app does not give an audio response, instead, the glove activates. The Raspberry Pi Zero W attached to the glove uses the Raspberry Pi camera module to take a picture and send it to the database if the user presses a push-button on the side of the glove. However, the glove has a listener set on the database to check if the search function is called on the app. It then calculates the location of the object relative to the user by the angular separation of the center of the bounding boxes relative to the center of the user’s view field, giving us how far the user needs to move degree-wise. We use 4 vibration motors around the glove to vibrate in the direction of any of the boxes. We also use an Inertial Measurement Unit (IMU) to track their movement to give real-time feedback.
Challenges we ran into
One difficulty we faced was dealing with communications across different platforms. Our original solution to synchronously share and receive data across the Android App, raspberry pi, and the Ec2 was to secure copy images or SCP, but this took around about 30 seconds alone. This is why we migrated towards the Redis Enterprise database which allows for the different systems to exchange information dynamically through various data structures, such as Strings, Bit-Fields, and Queues. Another was avoiding redundancies within the meta-classifier. Usually, both models would detect several objects in common. At first, we placed a filter that would remove a classification from one of the models if it was found in both. For example, if a single car was detected by both models, the detection with a lower accuracy would be removed in the final output. This did not always work, as the models would often classify the same object with different names. Our solution was employing an area filter. The area filter examines classifications from different models with overlapping boundary boxes. If the intersection is 70% or above, the final label for that class is determined by a hierarchy of the models based on their MAP. This means that the output for this filter is the output of the overlapping model with the highest MAP.
Accomplishments that we're proud of
The inertial measurement unit (IMU) tracks the angular displacement of the user with a gyroscope and magnetometer for X and Z axis measurements. Getting a compatible Kalman filter to work with the IMU’s library was a difficult task and something that we are definitely proud of. Another thing we’re proud of is having our interfaces working in real-time. We had to make several optimizations between Redis functions and our Ec2 virtual machine, to bring down the output time to just a few seconds. Also, we're proud of our compact design since getting all the electronics to fit on the upper arm was a difficult task.
What we learned
We learned a lot about how models could be integrated with AWS and learned how to deploy models and endpoints on SageMaker. We also learned how to use the AWS Python3 SDK, Boto3. We also learned about more conceptual topics, mainly about ensemble learning, from this project. Ensemble learning is the use of several classifiers in a certain combination to enhance the accuracy of a model. This concept served as the basis of our object detection and filter system. In addition, we learned how to use an IMU with a Raspberry Pi. This takes some time, as we not only had to look for several libraries to learn how to use it, but we also had to find an efficient way to calibrate the IMU routinely to keep the search function working accurately. We also learned how to use the Google speech-to-text and text-to-speech APIs in Android Studios
What's next for PalmSight
We plan to reduce the cost of this device even more, improve our object detection algorithms, and be able to integrate the AWS models and the app with fast live video object detection. We also want to incorporate Redis Streams for more user specific data, and manage user functions more efficiently. In the future, we plan to work with organizations helping the visually impaired. We have been in contact with a representative from the National Institute for the Blind to test our product and to receive feedback.
** Testing instructions on Github
Built With
- amazon-web-services
- arduino
- computer-vision
- javscript
- python
- raspberypi
- rcnn
- redis
- rpi
- tensorflow
- yolov3






Log in or sign up for Devpost to join the conversation.