-
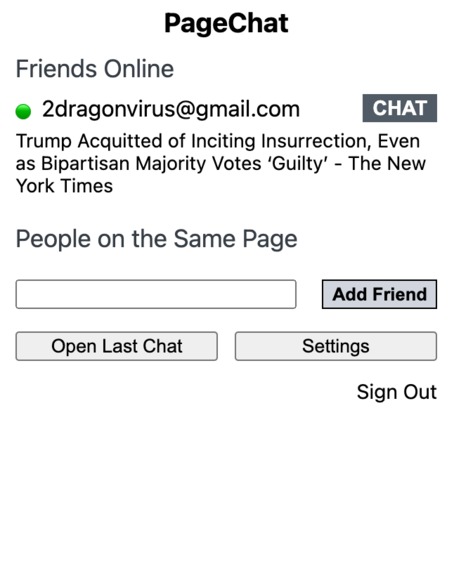
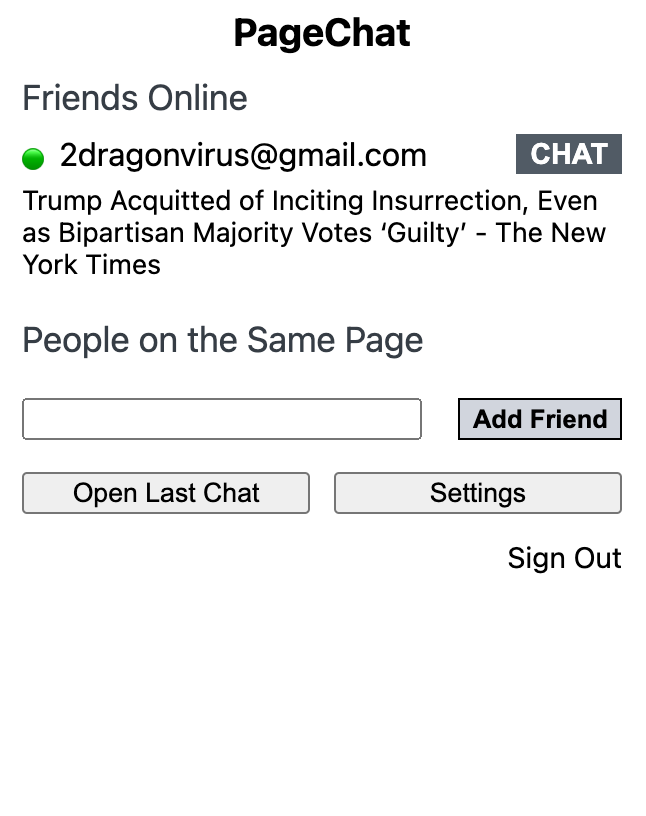
List of friends and what they are looking at, and a list of users on the same page (if there is one).
-
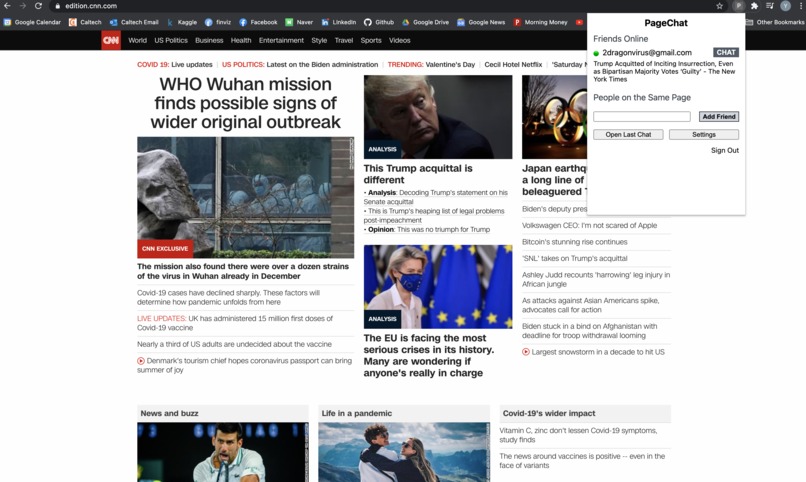
-

Chatting Room.
-
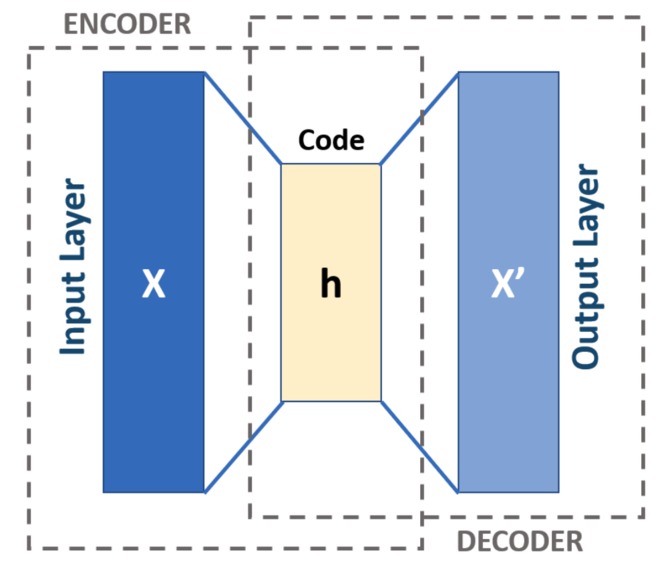
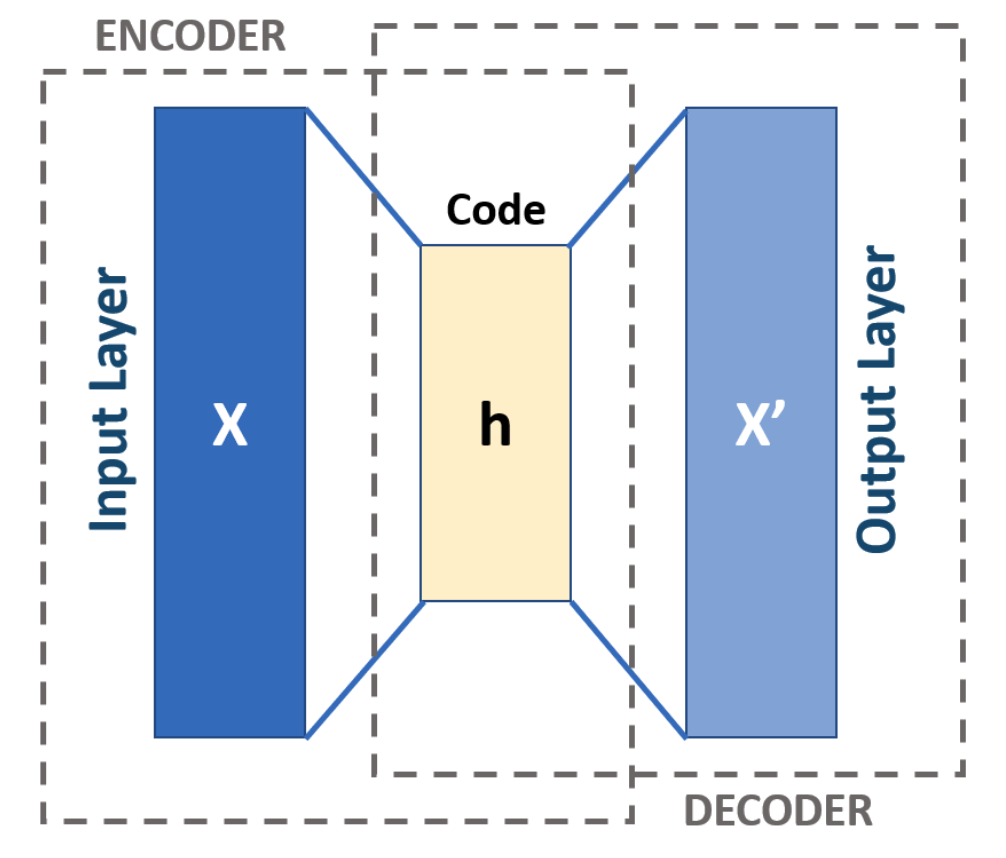
Diagram of the model to obtain the feature vectors.
-
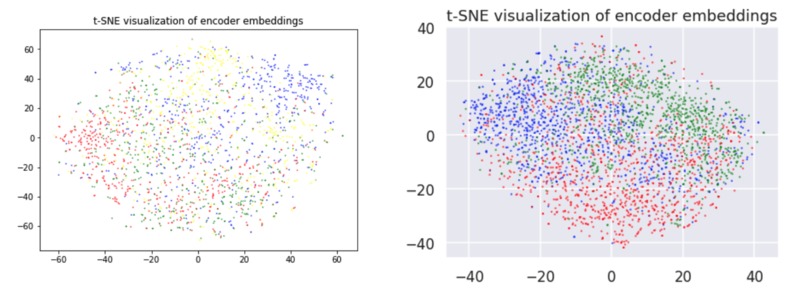
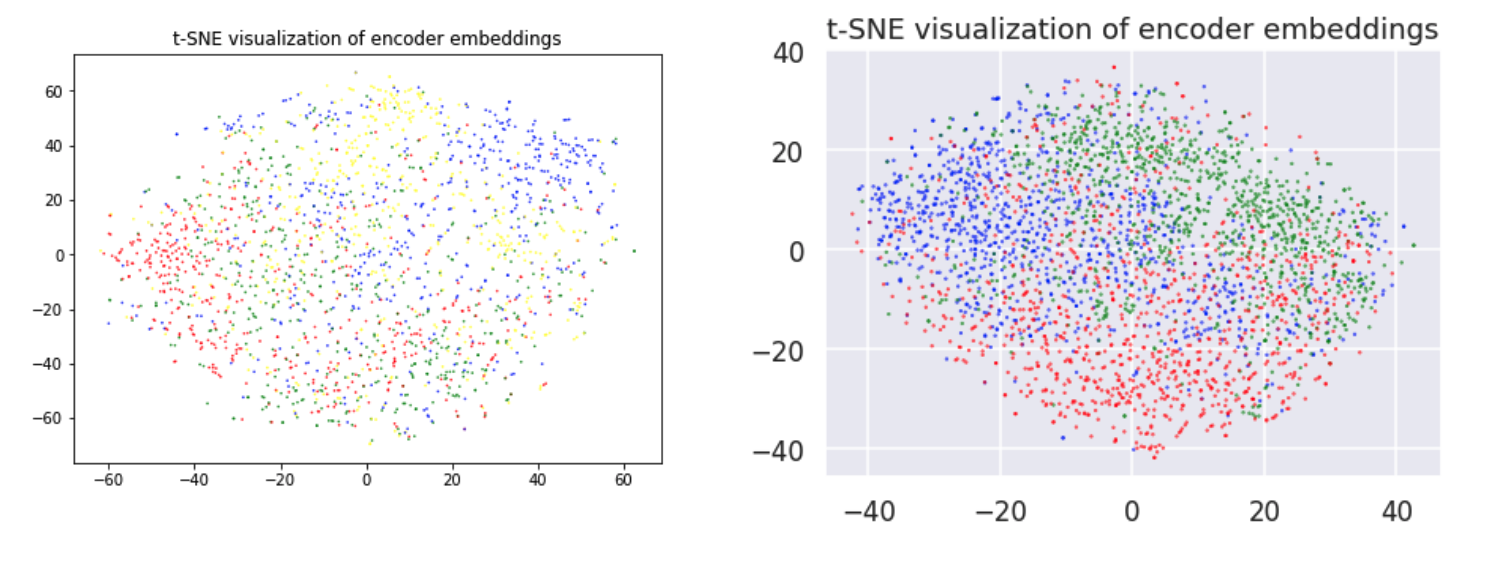
Visualization of the encoder feature vectors.

Inspiration
Have either of the following happened to you?
- Ever since elementary school you've been fascinated by 17th century Turkish ethnography. Luckily, you just discovered a preeminent historian's blog about the collapse of the Ottoman Empire. Overjoyed, you start to text your friends, but soon remember that they're into 19th century Victorian poetry. If only you could share your love of historical discourse with another intellectual.
- Because you're someone with good taste, you're browsing Buzzfeed. Somehow "27 Extremely Disturbing Wikipedia Pages That Will Haunt Your Dreams" is not cutting it for you. Dang. If only you could see what your best friend Alicia was browsing. She would definitely know how to help you procrastinate on your TreeHacks project.
- On a Friday night, all your close friends have gone to a party, and you are bored to death. You look through the list of your Facebook friends. There are hundreds of people online, but you feel awkward and don’t know how to start a conversation with any of them.
Great! Because we built PageChat for you. We all have unique interests, many of which are expressed through our internet browsing. We believe that building simple connections through those interests is a powerful way to improve well-being. We built a convenient and efficient tool to connect people through their internet browsing.
What it does
PageChat is a Google Chrome extension designed to promote serendipitous connections by offering one-on-one text chats centered on internet browsing. When active, Pagechat
- displays what you are your friends are currently reading, allowing you to discover and share interesting articles
- centers the conversation around web pages by giving friends the opportunity to chat each other directly through Chrome
- intelligently connects users with similar interests by creating one-on-one chats for users all over the world visiting the same webpage
How we built it
Chatting
The chrome extension was built with Angular. The background script keeps track of the tab updates and activations, and this live information is sent to the backend. The Angular App retrieves the list of friends and other users online and displays it on to the chrome extension. For friends, the title of the page they are currently reading is displayed. For users that are not friends, only those who are on the same web page are displayed. For each user displayed on the Chrome extension, we can start a chat. Then, the list view is changed to a chat room where users can have a discussion.
Instead of maintaining our own server, we used Firebase extensively. The live connections are managed by Realtime Database. Yet, since Firestore is easier to work with, we use Cloud Function to reflect the changes of live usage to Firestore using Cloud Function. Thus, there is a ‘status’ collection that contains live information about the connection state and the url and page title each user is looking at. The friends relations are maintained with ‘friends’ collection. We use Firechat, which is an open-source realtime chatting app using Firebase. Thus, all the chatting activities and histories are saved in the chats collection.
One interesting collection is the ‘feature’ collection. It stores the feature vector, which is an array of 256 numbers, for each user. Whenever a user visits a new page (in the future we plan to change the feature vector update criterion), a Cloud Function is triggered, and using our model, the feature vector is updated. The feature vector is used to find better matches i.e. people that would have similar interests among friends and other users using PageChat. As more data is accumulated, the curated list of people users would want to talk to would improve.
User Recommendations
If several people are browsing the same website and want to chat with each other, how do we pair them up? Intuitively, people who have similar browsing histories will have more in common to talk about, so we should group them together. We maintain a dynamic feature vector for each user, which is based off of their reading history. We want feature vectors with small cosine distance to be similar.
When is active on PageChat and visits a site on our whitelist (we don't want sites with generic titles, so we stick to mostly news sites), we obtain the title of the page. We make the assumption that the title is representative of the content our user is reading. For example, we would expect that "27 Extremely Disturbing Wikipedia Pages That Will Haunt Your Dreams" has different content from "Ethnography Museum of Ankara". To obtain a reasonable embedding of our title, we use SBERT, a BERT-based language model trained to predict the representation of sentences. SBERT can attend to the salient keywords in each title and can obtain a global representation of the title.
Next, we need some way to update feature vectors whenever a user visits a new page. This is well-suited for a recurrent neural network. These models maintain a hidden state that is continually updated with each new query. We will use an LSTM to update our feature vectors. It takes in the previous feature vector and new title and outputs the new feature vector.
Finally, we need to train our LSTM. Fortunately, UCI has released a dataset of news headlines along with their respective category (business, science and technology, entertainment, health). We feed these headlines as training data for the model. Before training, we preprocess the headlines, embedding all of them with SBERT. This greatly reduces training times. We use the following three-step procedure to train the model:
- Train an autoencoder to learn a compressed representation of the feature title. SBERT outputs features vectors with 768 elements, which is large and unwieldy. An autoencoder is an unsupervised learning model that is able to learn high-fidelity compressed representations of the input sequence. The encoder (an LSTM) encodes a sequence of headlines into a lower-dimensional (128) space and the decoder (another LSTM) decodes the sequence. The model's goal is to output a sequence as close as possible to the original input sequence. After training, we will end up with an encoder LSTM that is able to faithfully map 768 element input vector to a 128 element space and maintain the information of the representation. We use a contractive autoencoder, which adds an extra loss term to promote the encoder to be less sensitive to variance in the input.
- Train the encoder to condense feature vectors that share a category. Suppose that Holo reads several business articles and Lawrence also reads several business articles. Ideally, they should have similar feature vectors. To train, we build sequences of 5 headlines, where each headline in a sequence is drawn from the same category. The encoder LSTM from the previous step encodes these sequences to feature vectors. We train it to obtain a higher cosine similarity for vectors that share a category than for vectors that don't.
- Train the encoder to condense feature vectors that share a story. The dataset also has a feature corresponding to the specific news story an article covers. Similar to step 2, we build sequences of 5 headlines, where each headline in a sequence is drawn from the same story. By training the encoder to predict a high cosine similarity for vectors that share a story, we further improve the representation of the feature vectors.
We provide some evaluations for our model and document our training process in this Google notebook. Feel free to make a copy and tinker with it!
What's next for Pagechat
- Implementation of more features (e.g. group chatting rooms, voice chats, reading pattern analysis per user) that make the app more fun to use.







Log in or sign up for Devpost to join the conversation.