-
-
paddleocr-vl-receipt
PaddleOCR-VL-Receipt - A SFT Model Extract Info From Receipt
Inspiration
PaddleOCR-VL is not just an OCR model, but also a Vision-Language Model (VLM). This dual characteristic provided us with a new approach: since it's a VLM, we can use VLM fine-tuning methods to fine-tune the OCR model, going beyond the predefined recognition tasks like tables and formulas.
We realized that if we could directly extract structured information from images through the model, we could significantly simplify the subsequent processing steps in traditional OCR pipelines. Traditional methods typically require OCR recognition to obtain text first, followed by NLP techniques for information extraction. Our approach attempts to combine these two steps into one, going directly from image to structured data.
What it does
PaddleOCR-VL-Receipt is a fine-tuned version of PaddleOCR-VL specifically designed for extracting structured information from receipts. The project includes:
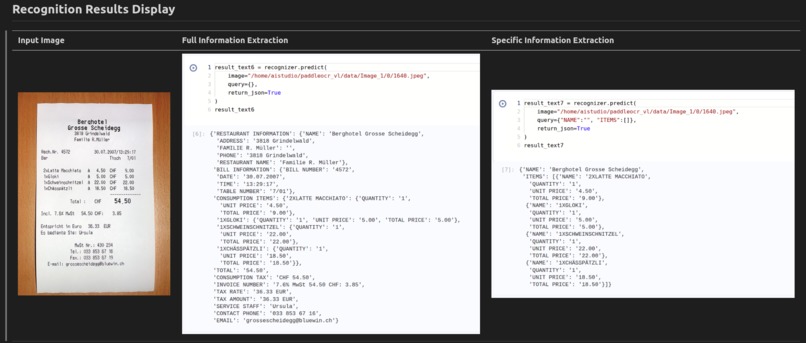
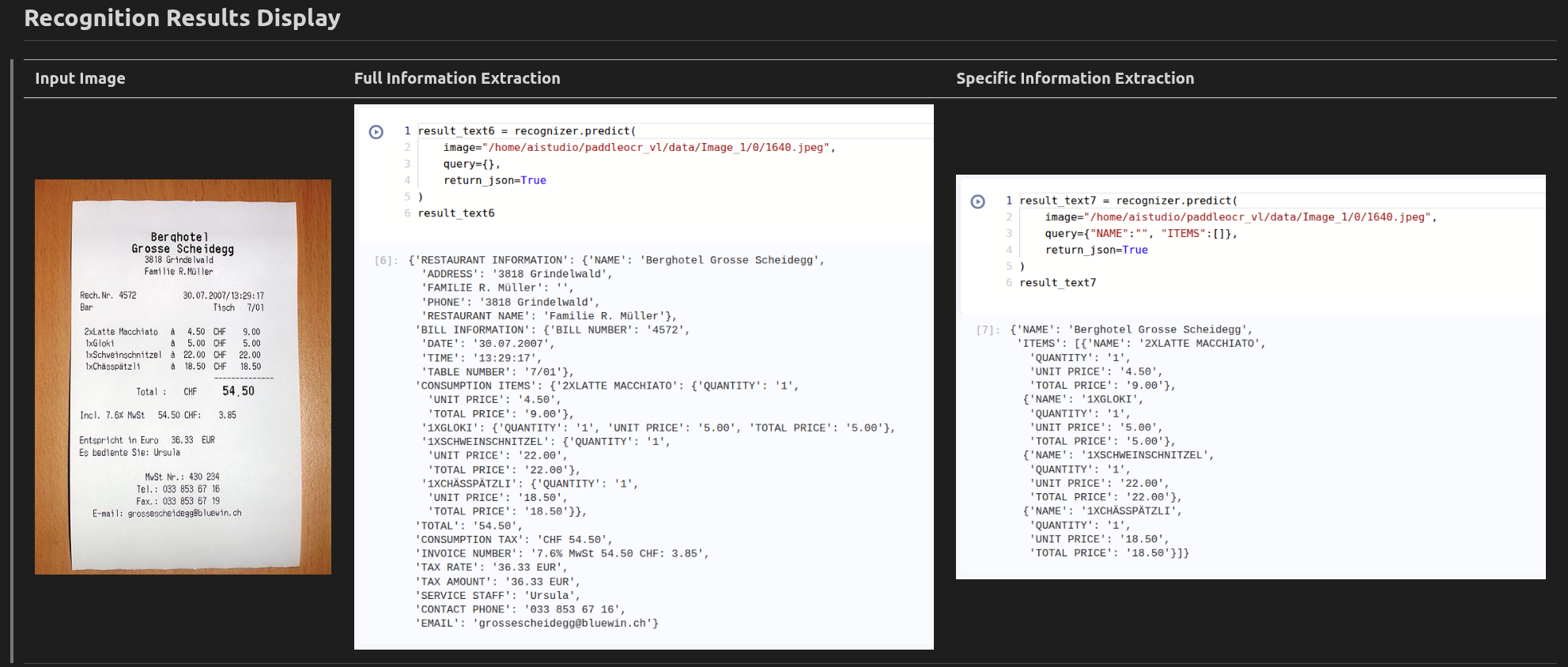
Custom Prompt Engineering: Extends the original PaddleOCR-VL prompt system to support user-defined JSON-based prompts, allowing for targeted information extraction.
Structured Data Extraction: Transforms unstructured receipt images into structured JSON data, making it easy to integrate with downstream applications.
Flexible Query System: Supports various query formats (string, list, dictionary) to specify exactly what information should be extracted from the document.
Simplified Interface: Provides a streamlined Python API and command-line interface that focuses solely on the VL recognition functionality, removing unnecessary components for document processing.
How we built it
The project was built through several key steps:
Base Model Selection: We started with PaddleOCR-VL-0.9B as our foundation, a vision-language model specifically designed for document understanding tasks.
Custom Dataset Preparation: Based on WildReceipt,we created a specialized dataset of receipt images with corresponding JSON annotations. The data was formatted in a specific way to teach the model to respond to custom prompts:
{
"image_info": [{"matched_text_index": 0, "image_url": "path/to/image.jpg"}],
"text_info": [
{"text": "OCR:{\"RECEIPT NUMBER\": \"\"}", "tag": "mask"},
{"text": "{\"RECEIPT NUMBER\": \"123456789\"}", "tag": "no_mask"}
]
}
Prompt Engineering: We designed a new prompt system that extends the original PaddleOCR-VL prompts:
- For full values:
"OCR:{}" - For string values:
"OCR:{\"FIELD\":\"\"}" - For dictionary values:
"OCR:{\"FIELD\":{}}" - For list values:
"OCR:{\"FIELD\":[]}"
- For full values:
Model Fine-tuning: Using the ERNIE framework, we fine-tuned the base model on our custom dataset. The fine-tuning process took approximately 3 hours on an A800 GPU, with the loss steadily decreasing throughout training.
Interface Development: We created a simplified Python script PaddleOCR-VL-REC that focuses only on the VL recognition functionality, removing unnecessary components like document preprocessing, layout detection, and chart recognition.
Patch Implementation: We developed a patch to bypass the original PaddleX restrictions that only allowed four predefined prompt types, enabling our custom prompts to work with the fine-tuned model.
Challenges we ran into
Limited Prompt Support: The original PaddleOCR-VL implementation only supported four predefined prompt types ('ocr', 'table', 'formula', 'chart'). We had to develop a patch to bypass these restrictions and allow our custom JSON-based prompts.
Data Preparation Complexity: Creating the training dataset in the required format was challenging, as it needed to pair images with specific JSON structures and prompts. To address this issue, we utilized the ERNIE 4.5 VL model to generate comprehensive JSON-structured data for subsequent data extraction in training tasks. Additionally, we developed custom tools to process and format the data correctly.
Model Integration Issues: Integrating the fine-tuned model with the existing PaddleOCR infrastructure required simplifying the interface design, keeping only the VL REC MODEL part.
JSON Parsing Limitations: The original model wasn't designed to output structured JSON data. We had to implement robust JSON parsing using the
json_repairlibrary to handle potentially malformed JSON outputs.Resource Constraints: Fine-tuning required significant computational resources, and we had to optimize the process to work within these constraints.
Output Consistency: Ensuring the model consistently outputs valid JSON format required careful prompt engineering and fine-tuning strategies.
Accomplishments that we're proud of
Successful Fine-tuning: We successfully fine-tuned PaddleOCR-VL to understand and respond to custom JSON-based prompts, extending its capabilities beyond the original four task types.
Structured Output Generation: The model can now output structured JSON data instead of just raw text, making it much more useful for downstream applications.
Flexible Query System: We implemented a versatile query system that accepts strings, lists, or dictionaries, allowing users to specify exactly what information they want to extract.
Simplified Interface: We created a clean, focused API that removes unnecessary complexity while maintaining the core functionality needed for information extraction.
Practical Application: The solution addresses a real business need for automated receipt processing, with potential applications in accounting, expense management, and financial automation.
Open Source Contribution: We've made our work available to the community, providing both the fine-tuned model and the tools needed to use it effectively.
What we learned
Vision-Language Model Adaptation: We learned how to effectively adapt a pre-trained vision-language model for specific domain tasks through targeted fine-tuning and prompt engineering.
Custom Prompt Design: We gained insights into designing effective prompts that guide models to produce structured outputs in specific formats.
Data Formatting for VLMs: We learned the importance of proper data formatting when training vision-language models, particularly how to structure image-text pairs for optimal learning.
Model Integration Techniques: We developed techniques for integrating fine-tuned models with existing frameworks, including how to work around system limitations and restrictions.
JSON Output Generation: We learned strategies for training models to generate valid JSON output, which is particularly challenging for language models not originally designed for this purpose.
Resource Optimization: We gained experience in optimizing model training and inference processes to work within computational constraints.
What's next for PaddleOCR-VL-Receipt - A SFT Model Extract Info From Receipt
Expanded Dataset: We can use data from more industries, types, and languages to expand the dataset according to specific needs, improving the model's generalization capabilities.
Multi-language Support: Currently focused on English receipts, we aim to extend support to receipts in multiple languages, particularly English and other major languages.
Enhanced Field Extraction: We plan to improve the model's ability to extract a wider range of fields, including more complex tax calculations, discount information, and line-item details.
Performance Optimization: We'll work on optimizing the model for faster inference and lower resource requirements, potentially through quantization and model compression techniques.
Error Handling and Validation: We plan to implement more robust error handling and output validation to ensure the extracted information is accurate and properly formatted.
Tool Continuous Improvement: We plan to continuously improve the PaddleOCR-VL-REC tool for information extraction needs of PaddleOCR-VL similar models, optimizing interface design and functionality implementation to provide users with a better experience.
Built With
- aistudio
- ernie
- erniekit
- paddleocr
- paddlepaddle
- paddlex
- python


Log in or sign up for Devpost to join the conversation.