-
-
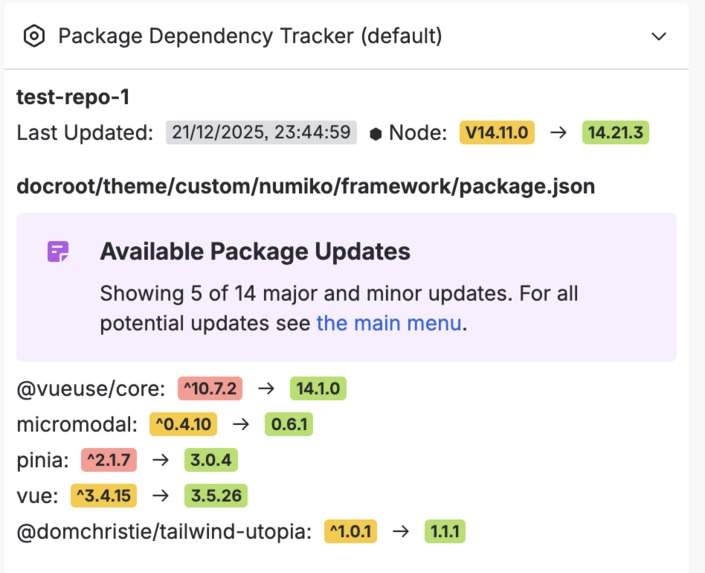
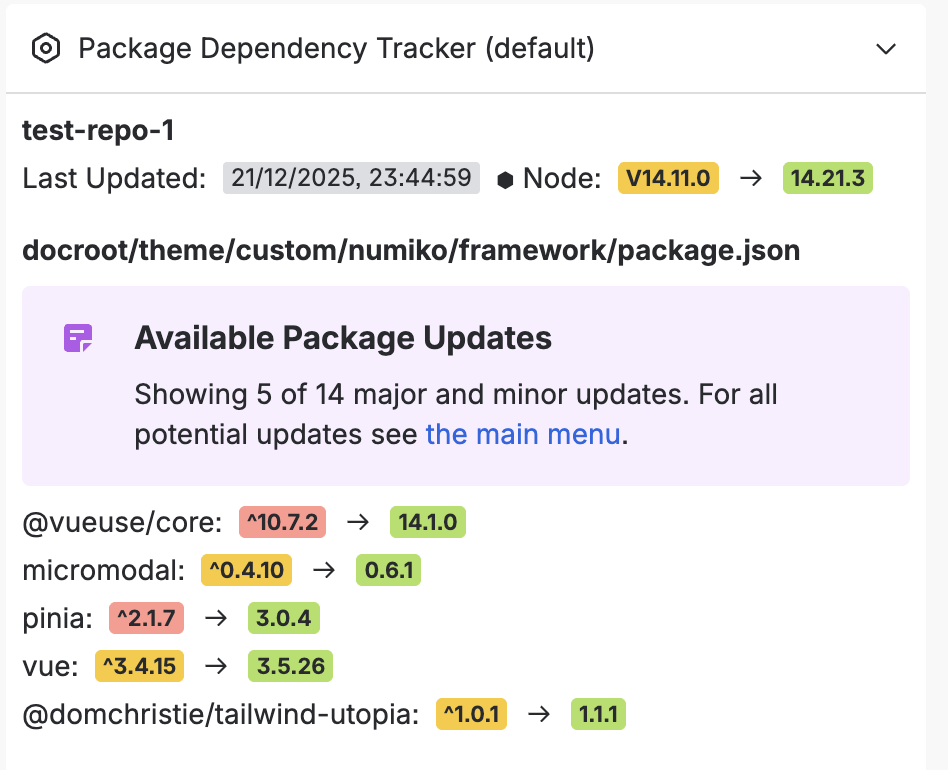
Repo Card Overview
-
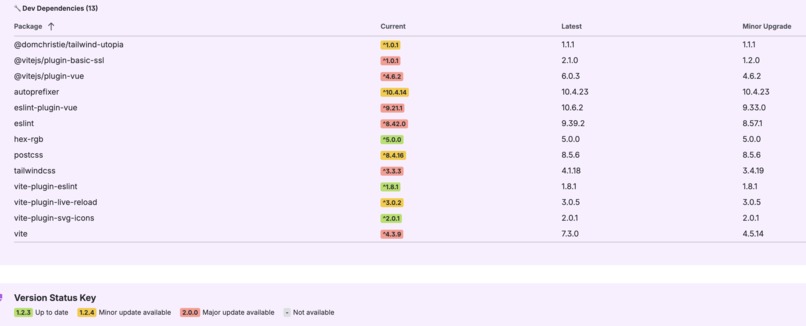
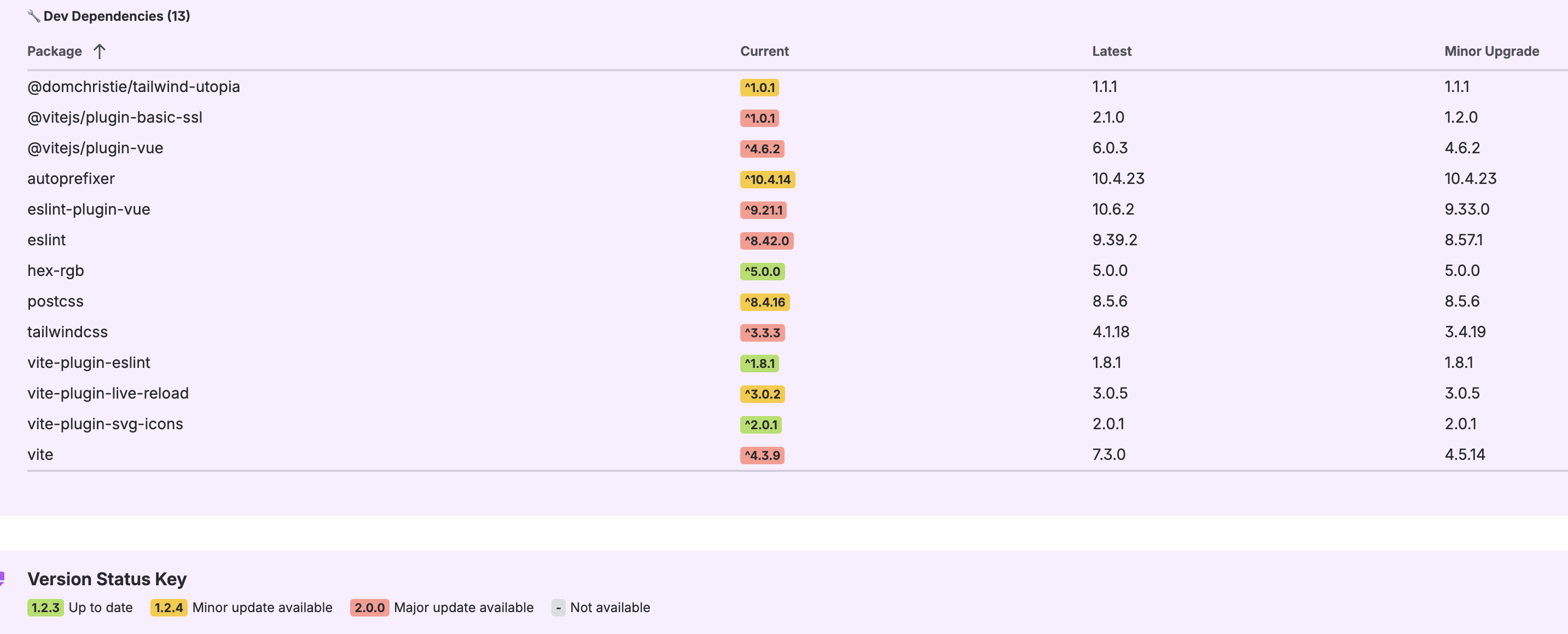
Repo Main Menu
-
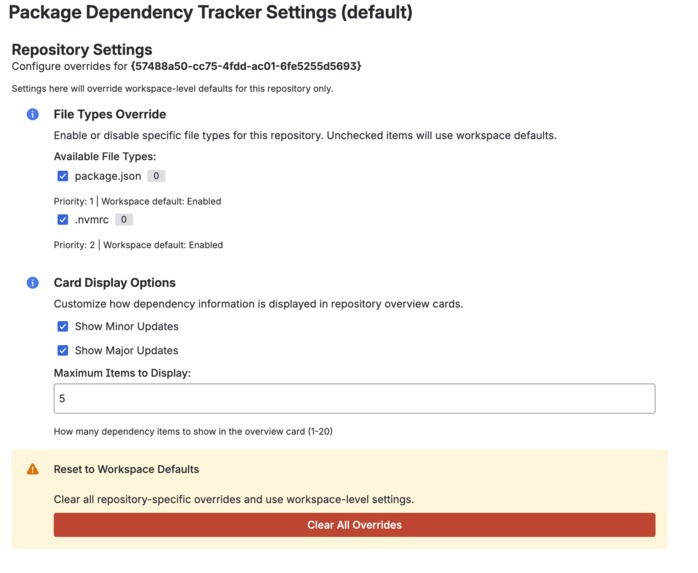
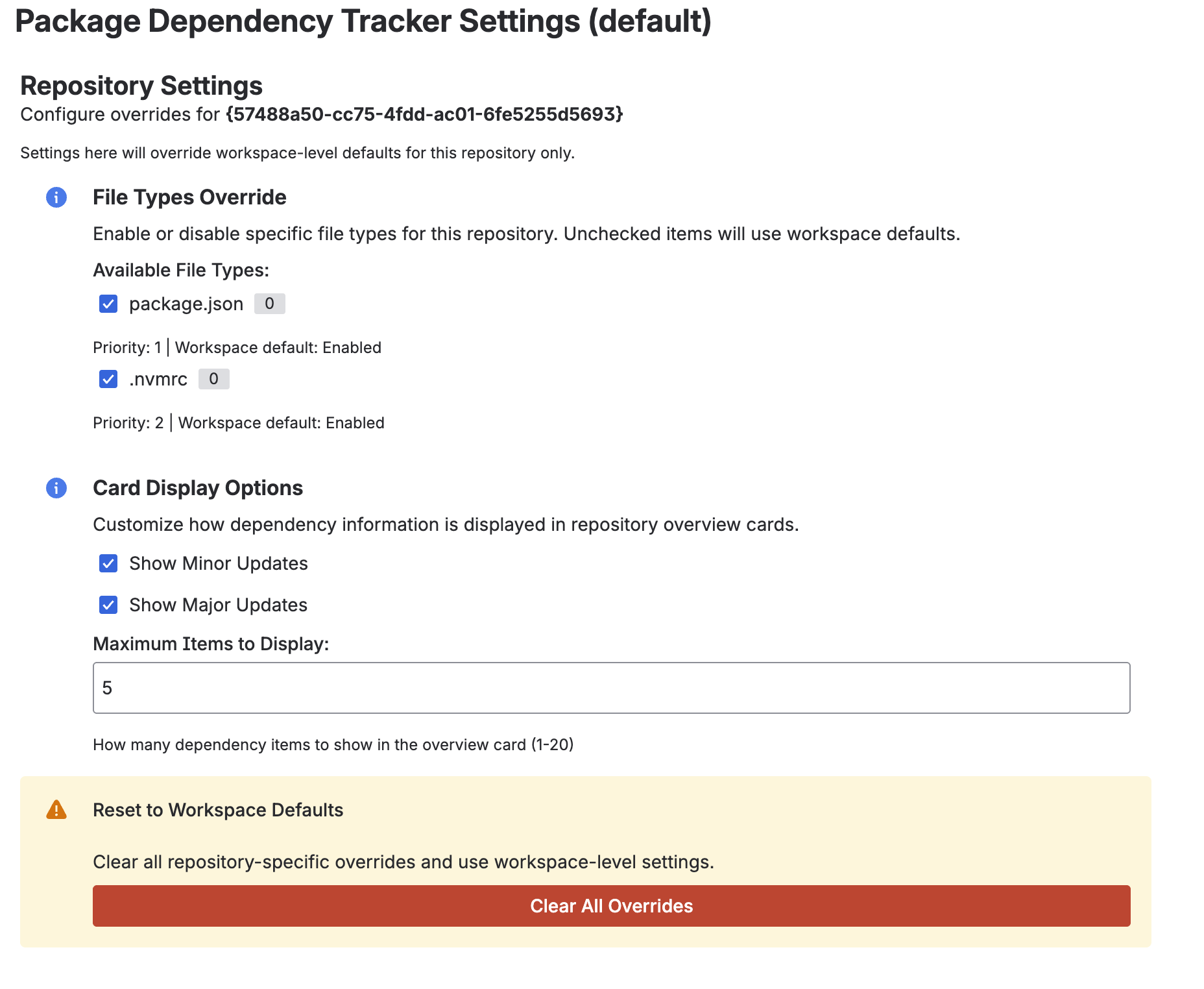
Repo Settings
-
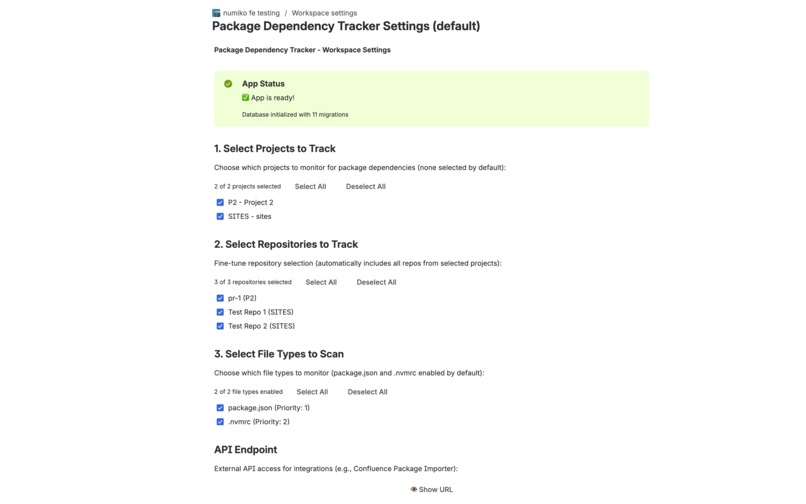
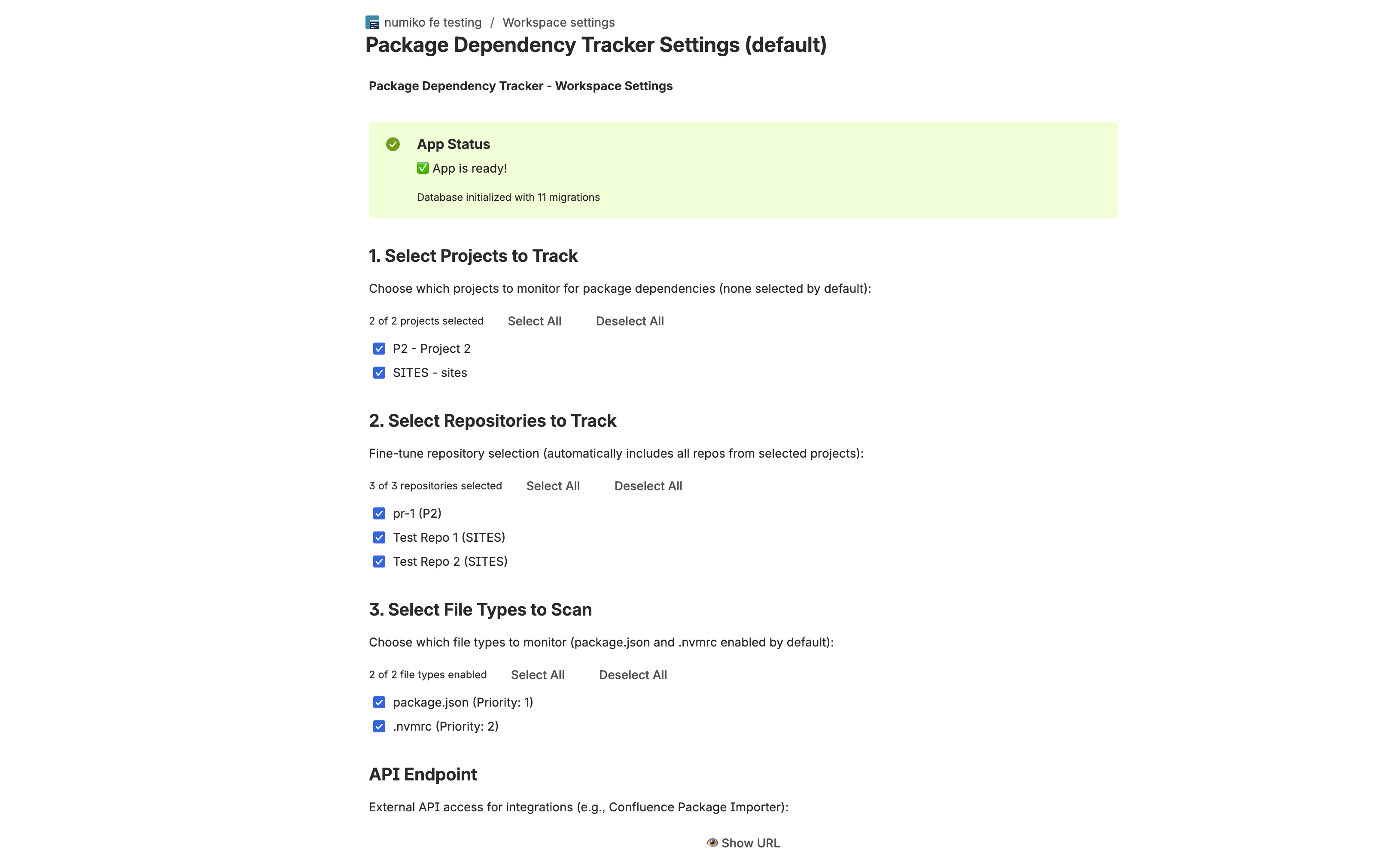
Workspace Settings
Setup
- This project takes a while to start up (up to 1 day for forge sql migration to run, although added button to speed this up in workspace setting, see video for help).
- Once thats done (check workspace settings), you can select projects and repos to track in workspace settings also.
- After which it runs batches of 10 dependencies every 5 minutes so if you have a large number of repos or dependencies to track it could take potentially hours to days to update all the values. I would suggest installing, go to workspace settings (forge apps > package dependency tracker), clicking button, selecting projects and repos, then check back in a few hours on the repo page that it has values.
- If that fails, run scan in repo main menu app page, then run batch jobs in workspace settings developer tools a few times and check again
Inspiration
You know that feeling when you finish a ticket and think "I should probably update those dependencies"... and then you don't? Yeah, we all do it. Dependencies pile up, updates get scarier, and suddenly you're 10 major versions behind. I wanted to fix that by making updates impossible to ignore , surfacing safe, non-breaking changes right in Bitbucket where developers actually work. The idea: nudge people to knock out a few updates each time they're in a repo, before they become a mountain of technical debt.
What it does
Package Dependency Tracker scans your Bitbucket repos, finds your package.json and .nvmrc files, and hits the NPM registry to see what's new. Then it puts that info exactly where you need it:
- Right sidebar overview card: Quick health check with colour-coded updates (green = you're good, yellow = safe updates available, red = major version jump)
- Full dependency dashboard: Detailed tables showing everything that needs updating
- Node.js version tracking: Catches .nvmrc files too
- Workspace-level config: Admins pick which projects and repos to track
- Batch processing: Handles huge workspaces without timing out
- Repo-level customisation: Override settings per repository
- API for Confluence integration: Serves data to a companion Confluence app (Package Importer) so you can document dependencies across your whole organisation
How we built it
This started as a hardcoded 10-repo prototype just for my team. During the hackathon, I rebuilt it from scratch to work for any workspace.
Tech stack:
- Backend: Forge SQL database, scheduled triggers (daily scans + 5-minute batch processor), resolver APIs
- Frontend: Forge UI Kit React components with custom state management
- External APIs: NPM registry for version data
- Job orchestration: Custom queue system with retry logic and parallel NPM fetching
- Data pipeline: Repo scan > file discovery > dependency parsing > NPM enrichment (all batched and async)
- API endpoint: Exposes dependency data for the Confluence Package Importer app
The job queue is the secret sauce, it keeps everything under Forge's 20-second timeout while processing hundreds of repos and thousands of packages.
Challenges we ran into
- UUID vs slug hell: Bitbucket uses UUIDs in some contexts and slugs in others. Had to design resolvers that gracefully handle both identifiers depending on which UI surface you're on
- Timeout whack-a-mole: 100+ repos with 1000+ packages blew past Forge's limits fast. Fixed it with parallel NPM fetching and smart batching (10 packages at a time)
- Zombie jobs: Batch jobs would time out and get stuck in 'processing' limbo forever. Built auto-recovery to detect and reset stuck jobs
- Race conditions: Making sure NPM data updates cascade through the job queue without everything stepping on each other's toes
- Workspace-agnostic rewrite: Ripping out all the hardcoded repo IDs and rebuilding for dynamic workspace discovery was ambitious for a hackathon timeline
Accomplishments that we're proud of
- Rebuilt the entire thing from a hardcoded prototype to workspace-agnostic in one hackathon
- 3x performance boost: Parallel NPM fetching cut batch processing from ~24s (with timeouts!) down to 8-10s
- Bulletproof job recovery: Jobs now recover automatically from timeouts and failures
- Smart settings hierarchy: Workspace defaults + repo-level overrides that actually make sense
- Optimistic UI updates: Config changes feel instant, even though they're queued
- Battle-tested at scale: Successfully running on our biggest workspace (100+ repos, 20+ packages each)
- API integration: Built an endpoint to feed dependency data into Confluence for organisation-wide visibility
What we learned
- **Job orchestration is critical
- Promise.all() saves lives: When you're timeout-constrained, parallelisation is everything
- Design for identifiers upfront: UUID vs slug handling needs to be baked into your architecture, not bolted on later
- Users hate waiting in silence: Loading states and progress indicators are non-negotiable when jobs run for minutes
- Build for scale on day one: Adding batch processing and job queues after you've written everything is painful. Do it early
- API-first thinking: Building the API endpoint opened up integration possibilities I hadn't even considered initially
What's next for Package Dependency Tracker
- Code cleanup: There's definitely room for improvement in the codebase (hackathon/vibe code)
- Faster card loading: Optimise the overview card rendering
- Custom file patterns: Let users define their own file types to track (would need a smart UI for specifying parsers)
- Smoother onboarding: It can take a while to start up, getting info faster would help users.


Log in or sign up for Devpost to join the conversation.