-
-
Homepage
-
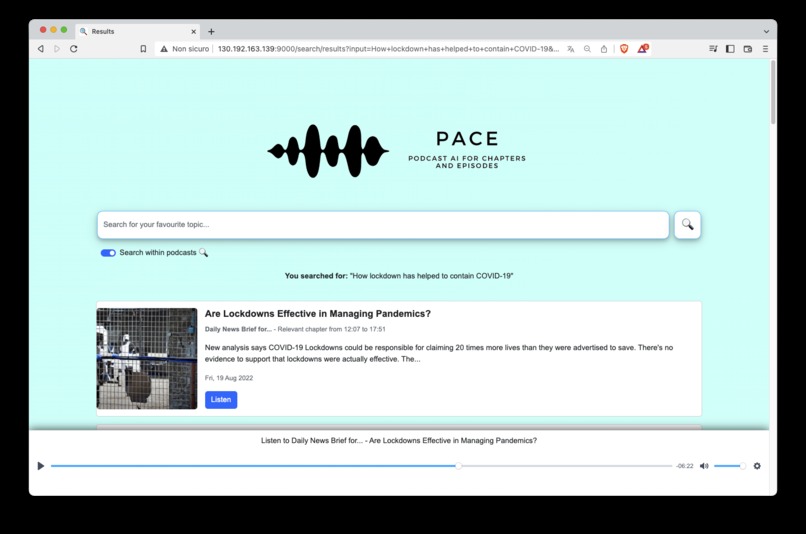
Podcast search
-
Mobile search and player
-
Mobile homepage

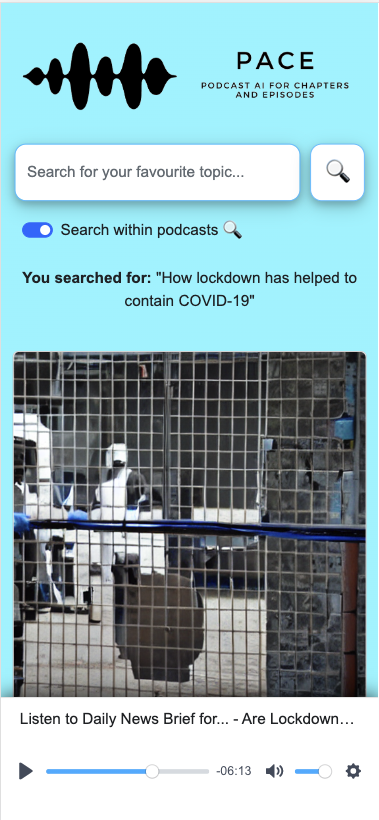

Using PACE, you can search for podcast episodes and chapters based on their semantics. Using artificial intelligence, it can understand what you're looking for and provide you with precisely what you need.
Inspiration
The podcast industry is growing at a rapid pace. In 2023, the number of podcast listeners will reach 160 million. It is a great opportunity for podcasters to reach a large audience and monetize their content. However, the podcast industry is still in its infancy. There is a lot of room for improvement. Our inspiration came from the fact that we are podcast listeners and we wanted to build a product that would make the podcast experience better. We also wanted to build a product that would leverage the latest advances in AI to make podcasting more accessible to everyone. We believe that PACE is a step in the right direction.
What it does
PACE is a semantic search engine that understands what you are looking for and provides you with podcasts that contain the exact information you need. It both indexes podcast episodes and chapters, and allows you to search for episodes or chapters using natural language. Here's what it does:
- Search for episodes: you can search for episodes using natural language. PACE will give you back the episodes that best match your idea.
- Intra-podcast search: you can search for chapters inside episodes to find the exact information you need.
- Automatic chapter covers: PACE presents you with a chapter cover that summarizes the content of the chapter. This makes it easy for listeners to quickly identify and navigate to the specific information they are looking for within an episode.
How we built it
We built PACE using the following technologies:
- 🔈 Speech Processing: is used to identify chapters inside episodes. We use AssemblyAI audio intelligence to transcribe the audio and identify chapters. Each chapter is then indexed in PACE and can be searched for using natural language.
📃 NLP: both episode descriptions and chapter summaries are indexed in PACE and can be searched for using natural language. We use both open-source embedding models (for episodes) and Cohere (for chapters) to embed the text and build a semantic search engine.
🎨 Computer Vision: using the latest advances in text-to-image synthesis, we can automatically generate chapter covers that summarize the content of the chapter. We use open-source models from Stable Diffusion available on the HuggingFace Hub to generate the chapter covers.
💻 Web: to get the best out of PACE, we built a web interface that allows you to search for episodes and chapters using natural language. It is built using Flask and the search engine is built using Elasticsearch. We also built a podcast player that allows you to listen to episodes and navigate to chapters using the chapter covers. It is built using plyr.js.
The project repository and the demo link are available here.
Challenges we ran into
Each hackathon has its own challenges, but each one is also an opportunity to learn.
We crawled ~23K podcast series from the web, each one with a list of associated episodes. Our goal was to use AssemblyAI to transcribe the audio and identify chapters for all of them. However, we quickly realized that we would have not been able to do that in the time we had. We made a choice and we focused on news-related podcasts. We were able to index ~350K episodes with their associated description. For the chapters, we focus on 2 podcast series: The Daily Good and Daily News Brief. The total number of episodes with chapter-level semantic information is ~300 (~2500 chapters).
We had similar limitations for text embeddings. We wanted to index all the episodes using the Cohere API but the limit of 100 calls per minute was too restrictive. For this PoC we use open-source models from sentence-transformers to embed the episode descriptions. We leverage Cohere APIs to embed the chapter summaries only.
The last challenge we had was related to the chapter covers. We wanted to use text-to-image synthesis to automatically generate chapter covers. As you can imagine, this is a very computationally intensive task but we finally managed to generate chapter covers for all the chapters using Google Colab.
Accomplishments that we're proud of
We are proud of the fact that we managed to build a working prototype in 48 hours. We are also proud of the fact that we managed to build a working web interface that allows you to search for episodes and chapters using natural language.
The podcast player allows you to listen to episodes and chapter covers are an innovative way to quickly grasp the content of a chapter even if the artwork is not available for them.
We integrated both open-source and commercial APIs to build PACE. They allowed us to build a working prototype for the hackathon and we are looking forward to make a more robust version of PACE in the future (maybe a real product?).
What we learned
We learned a lot about modern AI technologies and how they can be used to build innovative products. The podcast industry is a mix of audio and text and we learned a lot about how to leverage both to build a better podcast experience. We also integrated computer vision to generate chapter covers and had a lot of fun doing that.
The hackathon was a great opportunity to open our minds and learn about new technologies. Web development is not our main area of expertise but we learned a lot about Flask and Elasticsearch, something we will definitely use in the future.
As deep learning researchers, we are used to train our own AI models. We learned a lot about how to leverage commercial APIs to build a working prototype in a short amount of time. We are looking forward to integrate more APIs in the future.
What's next for PACE: Podcast AI for Chapters and Episodes
We thought about a lot of features that we would like to add to PACE. Here are some of them:
- More episodes and chapters: we would like to index more podcasts and chapters. We definitely need more time and compute resources to do that, but we are looking forward to achieve this goal. Limiting the project to news-related podcasts was a choice we made to be able to build a working prototype for the hackathon.
- Subtitles: we would like to add subtitles to the podcast player. This would allow us to enhance the user experience and make it easier for people to understand the content of the podcast (non-native speakers, people with hearing problems, etc.).
- Misinformation detection and other AI superpowers: we would like to add more AI superpowers to PACE. We are thinking about misinformation detection, audio-to-text translation, etc. We are also thinking about adding more podcast-related features like podcast recommendations but it would require a well-thought-out and long-term strategy.
Finally, we would like to explore the possibility of building a real product out of PACE. We are looking forward to work on this project in the future.
Built With
- assemblyai
- cohere
- elasticsearch
- flask
- huggingface
- plyr
- python
- pytorch
- stable-diffusion


Log in or sign up for Devpost to join the conversation.