-
-
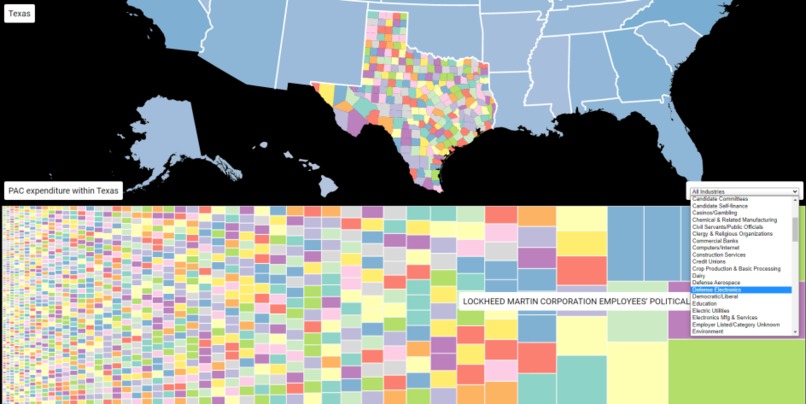
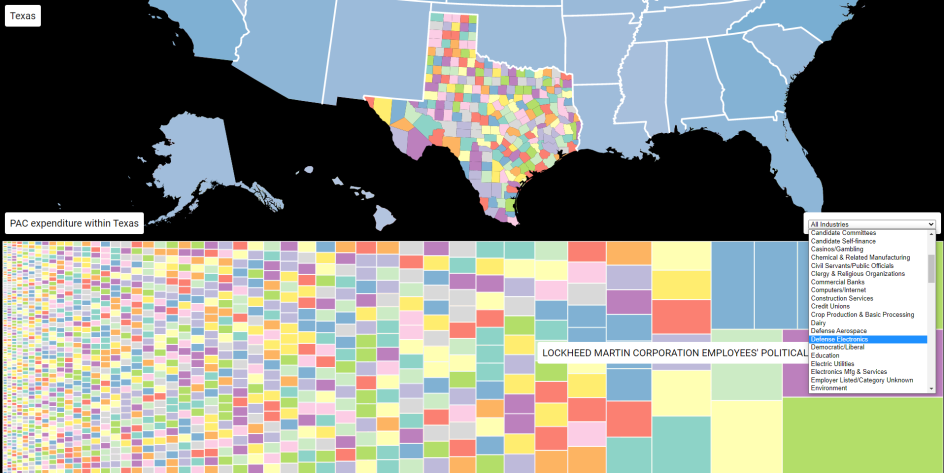
All the PACs that contribute to a candidate in Texas
Inspiration
As active participants in this country's democratic processes, we were disappointed that there weren't many good data visualizations of campaign finance data. It was difficult to keep track of where and who each candidate received money from. We were curious to see what industries backed which candidates for issues we cared about, so we decided to make an intuitive data visualizer that grouped the data based on what the user was looking for.
What it does
This project aims to clarify what PACs are donating to candidates running for office. Users can sort by state, county, industry, and more to view issues that are important to them. By grouping FEC campaign finance data, voters will be more educated on who donates to their representatives and how much their representatives receive during an election cycle.
How we built it
We used public data from the FEC to build our database using Google Cloud SQL. Our database kept track of candidates, PACs, industries, and donations made by PACs to candidates. Using Google Cloud App Engine, we deployed endpoints to retrieve the campaign finance data from our database. For our frontend, we used d3.js, a data visualization library to intuitively plot relations between candidates and the industries that back them. We utilized a tree graph to represent the proportion of money spent per PAC and utilized a map of the United States and its counties to find relevant congressional candidates.
Challenges I ran into
The first challenge that we ran into was a problem with the Google Cloud Platform SQL database. We were set on using this technology because of the large amount of data that we could store, as well as the ability to make fast, relational queries. The major problem was being able to store massive amounts of FEC data quickly. Using insert query calls with the data that we had would cause the database to timeout. To combat this, we broke up the data and insert queries into smaller chunks so that the SQL server wouldn't become overstrained with one call of a large volume of data. Since MySQL was fast on read-only operations, changing our already massive tables caused lots of performance issues when it came to editing the data. Since we had scripts to automatically enter data, it was easier to repopulate tables after any mistakes. The second challenge appeared when we started to use the data visualization JS library that we chose. Initially, we thought of surrounding the map with nodes, where each node represented one PAC. We quickly found that this wouldn't work out, as there were thousands of PACs and the entire screen would be filled with nodes unless we changed their sizes to be extremely small. We couldn't find a way to visualize the nodes in an appealing fashion, so we decided to pivot to using a treemap. The treemap allowed us to store each node as a scalable rectangle based on the amount of money that a PAC donated to that state/candidate. The treemap visualization library came with challenges of its own, but it provided a much cleaner, and aesthetically pleasing, product in the end.
Accomplishments that we are proud of
We were really proud of our MySQL database and the amount of data we had stored in it. Since we had multiple tables, we were able to create meaningful relations between the data to serve to our frontend. Each query was optimized to read from our dataset to quickly return any data we were looking for.
We were also really proud of the backend endpoints that we were able to create with GCP's App Engine. These endpoints allowed our frontend to easily receive the necessary data from our database without a large number of unnecessary calls with esoteric/poorly-maintained javascript libraries that might have caused even more problems. One simple fetch command brought the data from the SQL server, through the flask router + pre-processing, and returned a nicely formatted JSON object which the frontend could use. Even though the team has a large amount of Python experience, it was our first time using Flask which made us even more proud that we got the endpoints up and running so quickly.
The data visualization aspect of the project was also a big accomplishment that we were proud of. Since this was such a cornerstone of the project, a large amount of the effort was dedicated to making the frontend work well and look elegant. We used many different technologies and combined their strengths to create, in our opinion, an aesthetically pleasing and smooth UI for the user to explore the hidden world uncovered by the FEC data. The district outlining, zoom in/out, and treemap were all very cool libraries and techniques that we are very proud to have gotten working.
What we've learned
- How to set up and run a Python Flask API on GCP App Engine
- How to connect to a GCP SQL server and send multiple queries (select, insert, create, etc.)
- Advantages for both MySQL and PostgreSQL as databases
- How to visualize data using the d3.js library with SVGs and map data
What's next for PAC Finder
- [ ] Expand the timeframe of PAC contributions (currently 2019 - 2020)
- [ ] Filter by political party, candidate, etc.





Log in or sign up for Devpost to join the conversation.