-
-
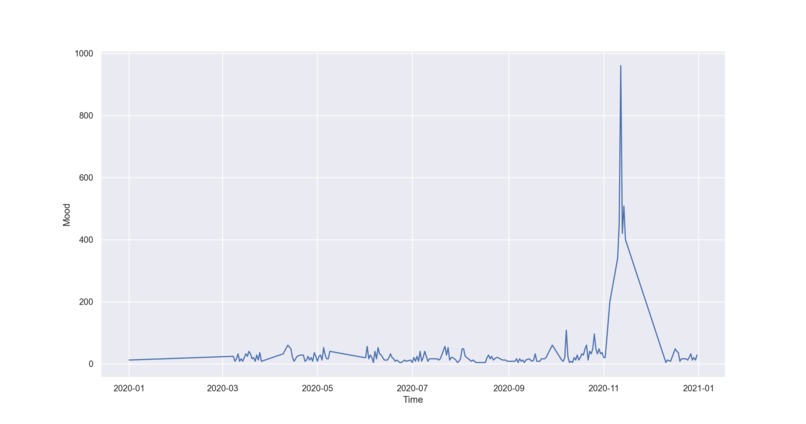
Mood analysis over last 6 months
Inspiration
Feeling happy having finished another problem sheet, we wondered if everyone in Oxford was feeling the same right now... Having asked our friends, we had a range of answers, but the data set was not big enough to understand the full complexity of Oxford University mood. So, we decided to use data collected from posts on Oxfess (the university confessions page) and find the of Oxford over time. Does 5th week Blues actually exist?
What it does
The program classifies each post as positive or negative, each with a score. We then graph the score for each day.
How I built it
We built a web scraper which scrolls through the Facebook page and turns each post into a dictionary containing the content of the post, date posted and other relevant information. The ML algorithm classifies each post as positive or negative. This model was trained on 1.6 million tweets which had already been classified. We then assigned a score to each post. We plotted each day's score on a graph.
Challenges I ran into
Data cleaning: Certain posts had to be excluded due to special characters. It was also a struggle reformatting the dates of each post. Training data: We had to find relevant training data for the ML model. The data had to be in a similar style to Oxfess posts (so movie reviews wouldn't do) - we eventually settled on Twitter due to its short-form posts. Web scraping: As we did not have time to go through the Facebook API, we used a handmade script. This went wrong a few times as it did not capture all the posts.
Accomplishments that I'm proud of
Working with large amounts of data Working to a strict deadline.
What I learned
Data cleaning is very important and takes significantly longer than expected!
What's next for OxMood
We hope to improve the prediction accuracy by using better training set as well as ML models. Our current accuracy is at around 76-78%, which, while high for a small project like that, is far from ideal. We can also roll this out to other university confession pages. We also notice a huge spike recently. This is probably due to a quiet summer. We would want to scrape data from before lockdown begun.
Built With
- machine-learning
- matplotlib
- python
- scikit
- web-scraping






Log in or sign up for Devpost to join the conversation.