Inspiration
The inspiration for Oversight comes from a broken promise in the software industry: "Documentation is the Source of Truth."
We all know the "Ideal Flow": A developer writes code, then dutifully updates the documentation in Confluence. But the "Real Flow" is brutal. Workloads explode, deadlines tighten, and P1 bugs demand instant fixes. In the heat of the moment, the code changes, but the documentation is left for "later", a "later" that never comes.
The result is "Zombie Documentation": pages that look alive but describe a system that died three versions ago.
This creates a disastrous cycle:
- The Onboarding Nightmare: When a new member joins, they read the docs, try to run the project, and fail. They have to tap a senior developer on the shoulder, breaking their flow, just to ask, "Is this page still true?"
- Forensic Coding: When we need to debug old logic, we can't trust the specs. We are forced to become "Code Archaeologists," digging through years of Git commits and
git blamejust to understand why a decision was made.
We realized that humans are great at writing code and great at writing plans, but terrible at keeping them in sync. We built Oversight to stop asking humans to be perfect, and instead build a system that automatically ensures the Code (Reality) never drifts from the Docs (Intent).
What it does
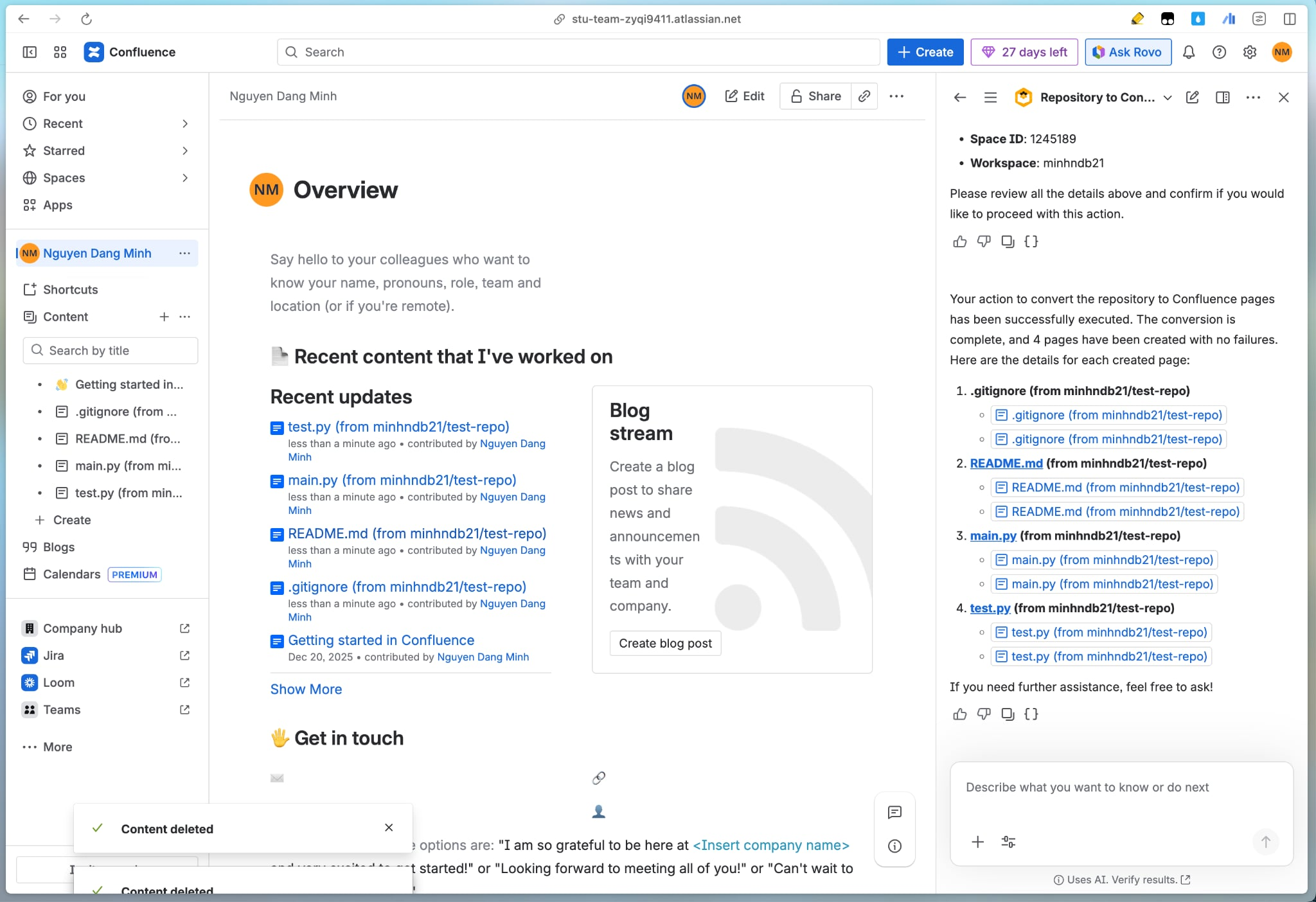
Oversight is an Atlassian Rovo Agent that acts as the "Autonomic Nervous System" for your project. It connects the separated worlds of Jira, Confluence, and Bitbucket into a single, living graph.
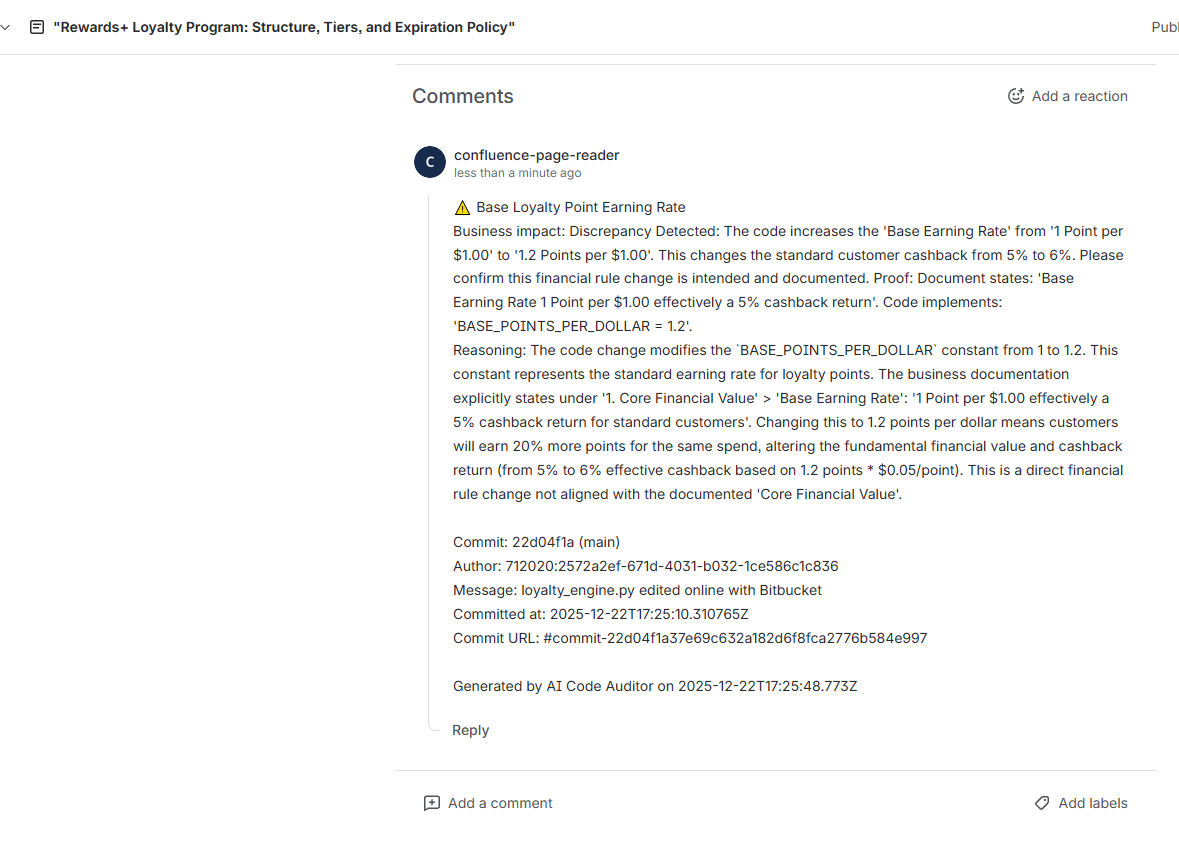
Oversight invisibly monitors the tension between your Confluence pages and Bitbucket code. If a developer changes the "Discount Logic" in Python, but the Confluence page still describes the old logic, Oversight flags the page immediately: "⚠️ Warning: Code logic in cart.py diverged from this paragraph 2 hours ago."
How we built it
- We use Vector Embeddings (via OpenAI) to map intent. This allows the system to understand that
TaxRules.jsonis mathematically similar to the concept of "Government Compliance," even if they don't share keywords.
2. The Tech Stack
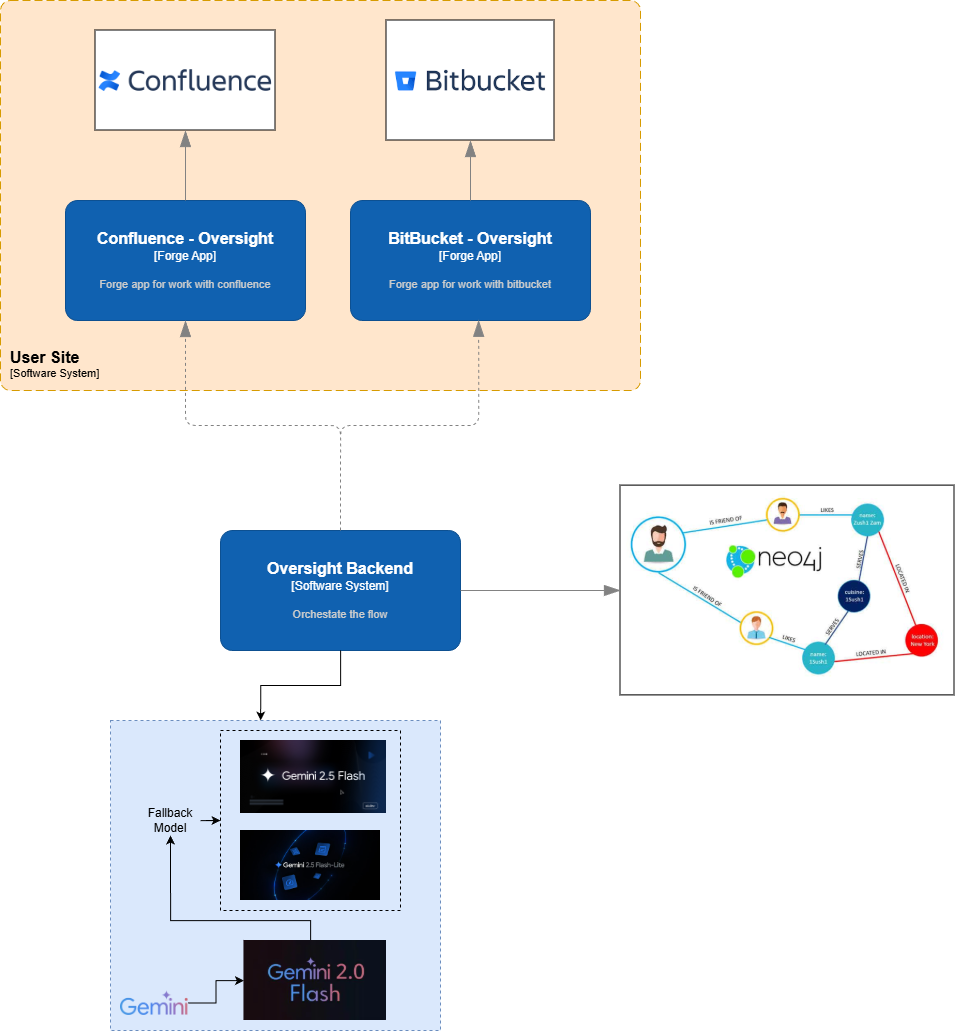
- The Brain (External Backend): Because analyzing a full Git history requires heavy compute, we built a Python/FastAPI backend integrated with Neo4j (Graph Database). This stores the relationships between every function, file, and requirement.
- The Agent (Atlassian Rovo): We utilized Rovo's conversational capabilities to allow developers to init old project -> into còn
Challenges we faced
- The "Context Window" Bottleneck: Real-world codebases are massive. We couldn't just feed an entire repository into an LLM to check for documentation drift. We had to rely on our Graph Database to pre-filter only the exact function snippets related to a specific documentation paragraph before sending it to the AI for verification.
- Defining "Drift": It was hard to tune the model to differentiate between a refactor (code changed, logic stayed the same) and a divergence (logic changed, docs are now wrong). We solved this by comparing the AST fingerprints alongside the semantic meaning.
Accomplishments that we're proud of
- Turning the "silent failure" of outdated documentation into a visible, manageable alert system.
- Successfully visualizing the "Invisible Dependencies" of a project—showing how a Jira ticket relates to a file deep in the backend.
What we learned
We learned that Trust is the most important metric. If a developer can trust the documentation, they move 10x faster. By automating the verification of that trust, we remove the fear of touching legacy code.

Log in or sign up for Devpost to join the conversation.