-
-
AWESOME WEBSITE DISPLAY AT ITS FINEST
-

LOOK AT THREEJS MAN, SO INSPIRATIONAL
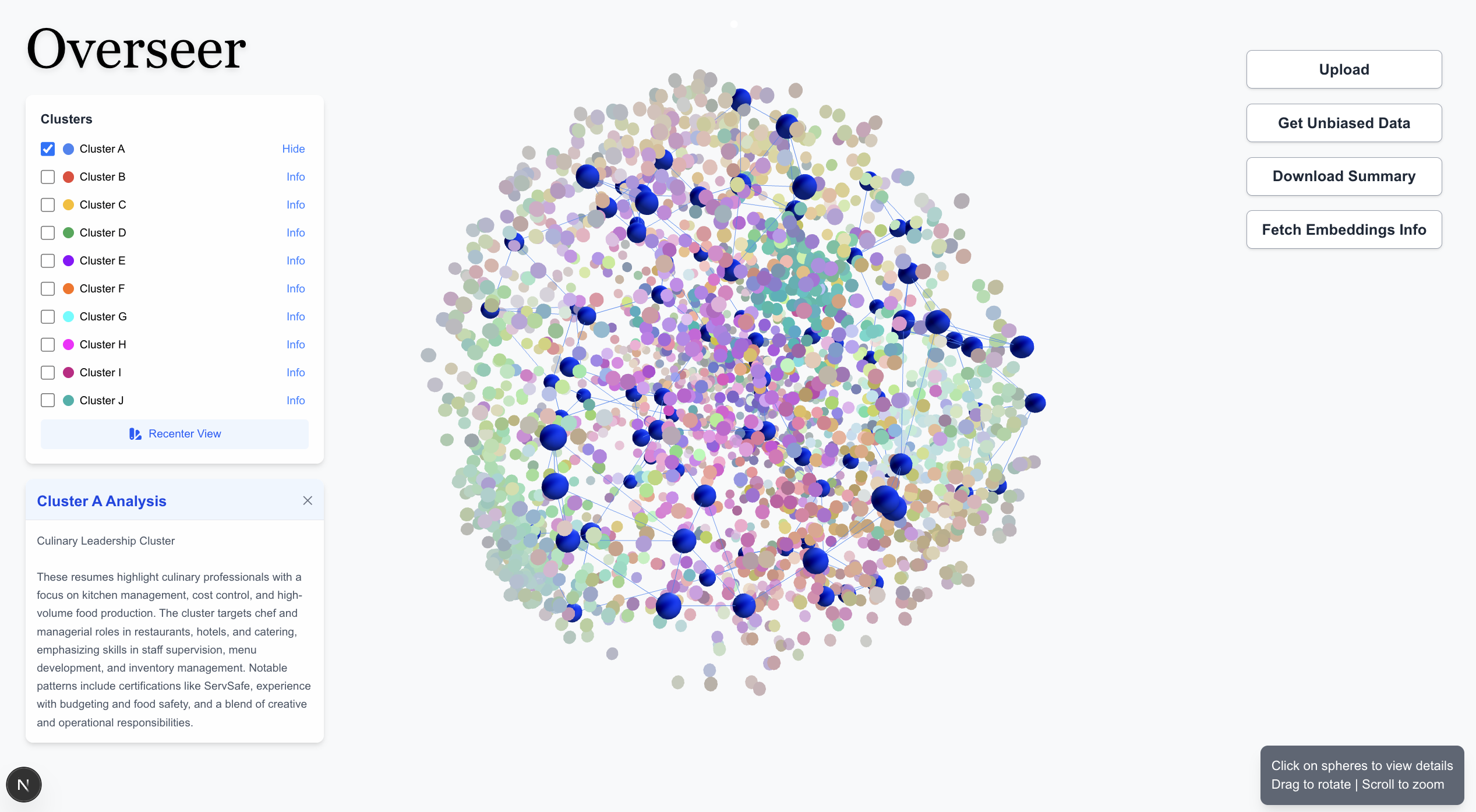

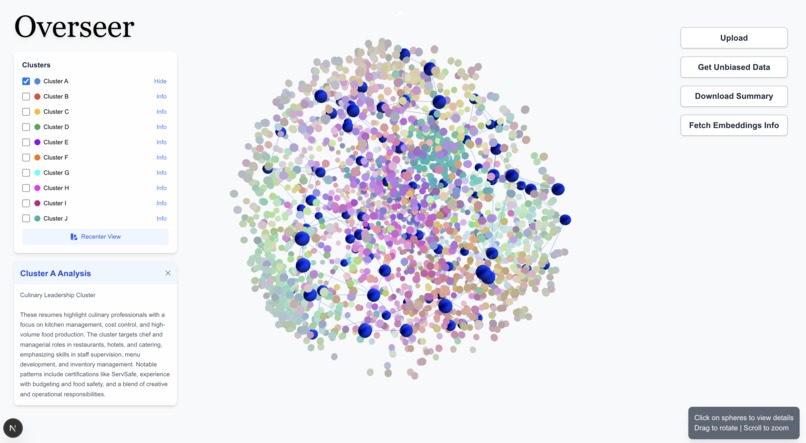
Overseer's goal is to mitigate bias in hiring by providing fair training data.
Biased data teaches models to focus on overrepresented examples, making it hard to evaluate underrepresented groups.
Users begin by inputting source data, such as resumes or text-based records, which are then transformed into text embeddings to capture the semantic meaning of the text. Next, we apply clustering algorithms to group similar data points based on their embeddings, and we use an LLM to analyze and extract common traits that define each group. Finally, we prune over-concentrated sections to ensure that no dominant category skews the dataset, leading to a more balanced and representative distribution. This process helps mitigate biases and improves the fairness of AI-driven decision-making systems.
By ensuring that the dataset accurately reflects a wide array of backgrounds and experiences, we empower organizations to build diverse and inclusive teams. This approach not only minimizes the risk of perpetuating existing biases but also actively promotes equitable opportunities for candidates from all walks of life.
Did you know?
In 2015, Amazon had to scrap its AI recruitment tool after it was discovered to be biased against women. This was found to be a result of the training data reflecting historical hiring practices dominated by male candidates, which taught the model to favor resumes from men. This case really demonstrates the critical need for unbiased data in cases that require objective decision-making, like hiring processes.
Tech Stack
Back-end: Flask, Python, Cohere API, Scikit Learn, numpy, pandas Front-end: Next.js, Three.js, TypeScript, HTML, CSS
Future Steps
Our method is designed to solve the larger problem of biased data in any context, a major challenge in the age of AI. In the future we would look towards implementing more optimized algorithms and expanding the application beyond hiring - generalizing the product for scalability and impact.











Log in or sign up for Devpost to join the conversation.