-
-

Logo
-
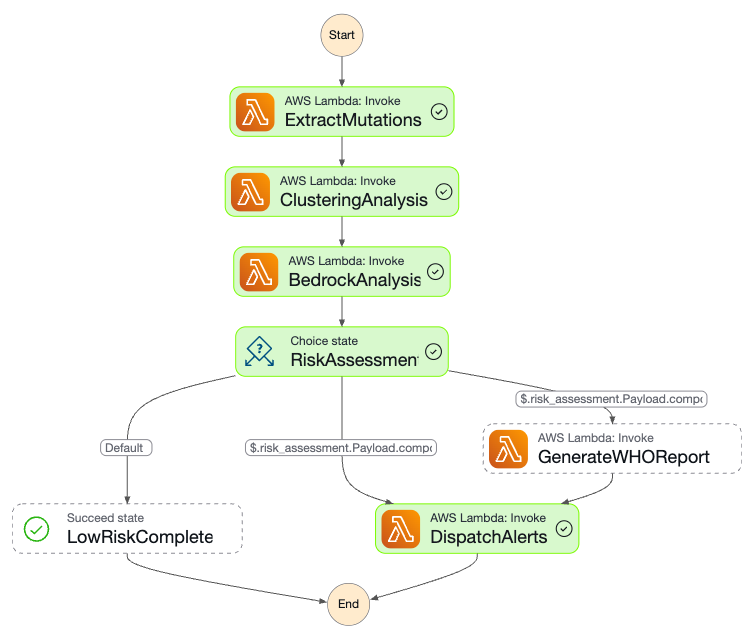
Workflow Graph
-
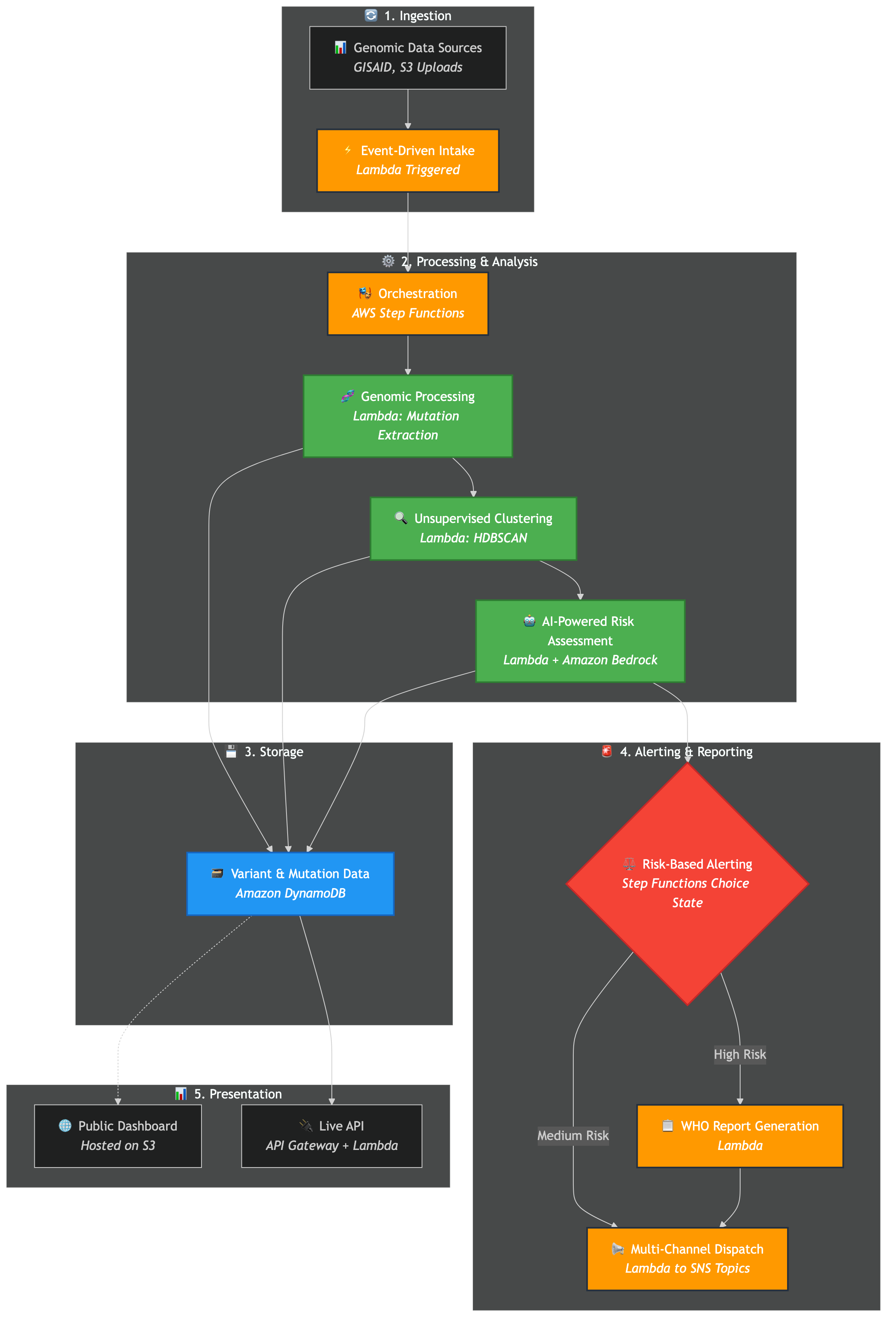
High Level Architecture
-
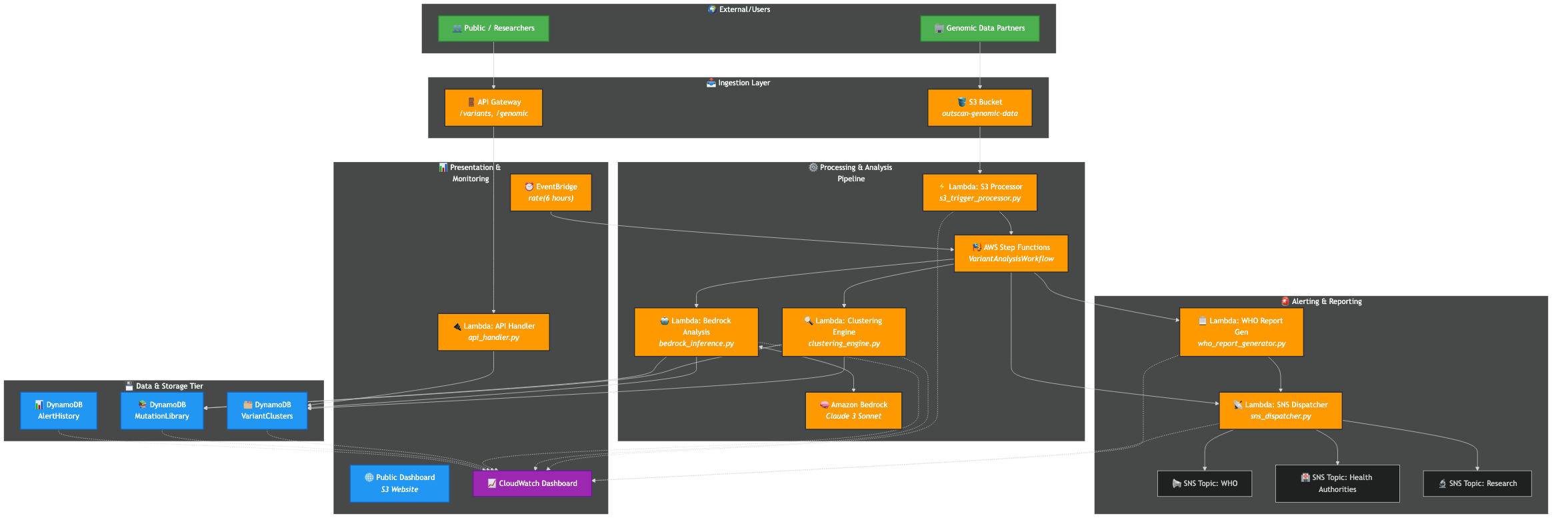
Aws-Infrastructure
-
Data Flow Sequence
-
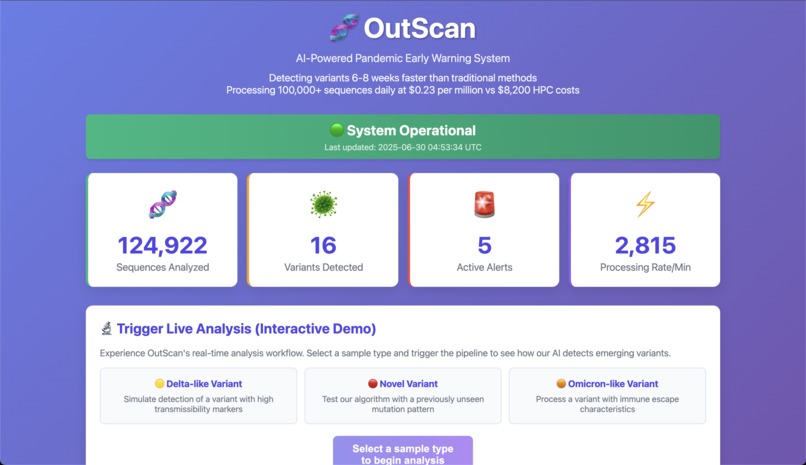
Dashboard

Inspiration
The world watched during the COVID-19 pandemic as new variants like Alpha, Delta, and Omicron emerged, each one setting back global progress. We were always one step behind. As technologists and data scientists, we were inspired by a single, powerful question: Could technology have given us a head start?
We realized the problem wasn't a lack of data—scientists were sequencing the virus around the clock. The problem was the time it took to turn that raw genomic data into actionable intelligence. We were inspired to build a system that could automate this process, leveraging the speed and scale of serverless computing and the reasoning power of modern AI to find the "needle in the haystack"—the next dangerous variant—weeks before it makes headlines.
What it does
OutScan is a serverless, AI-powered pandemic early-warning system built entirely on AWS. It automates the detection of emerging SARS-CoV-2 variants with a speed and cost-efficiency that traditional methods cannot match.
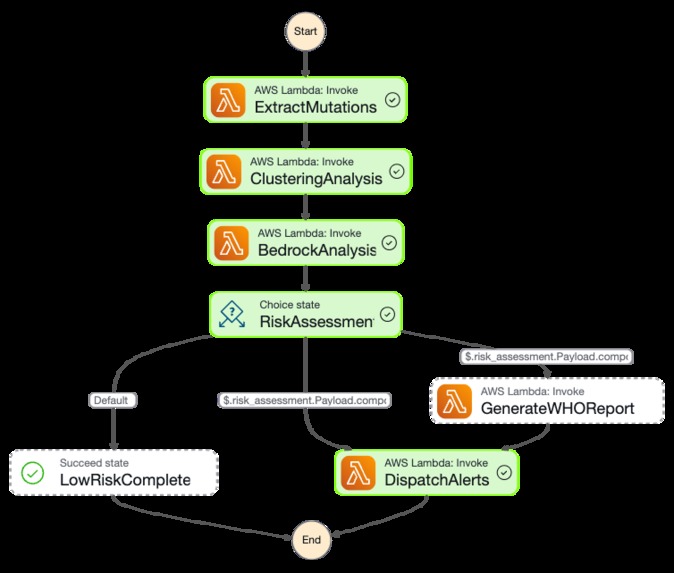
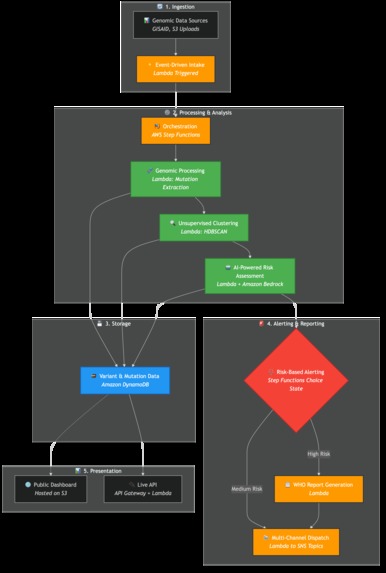
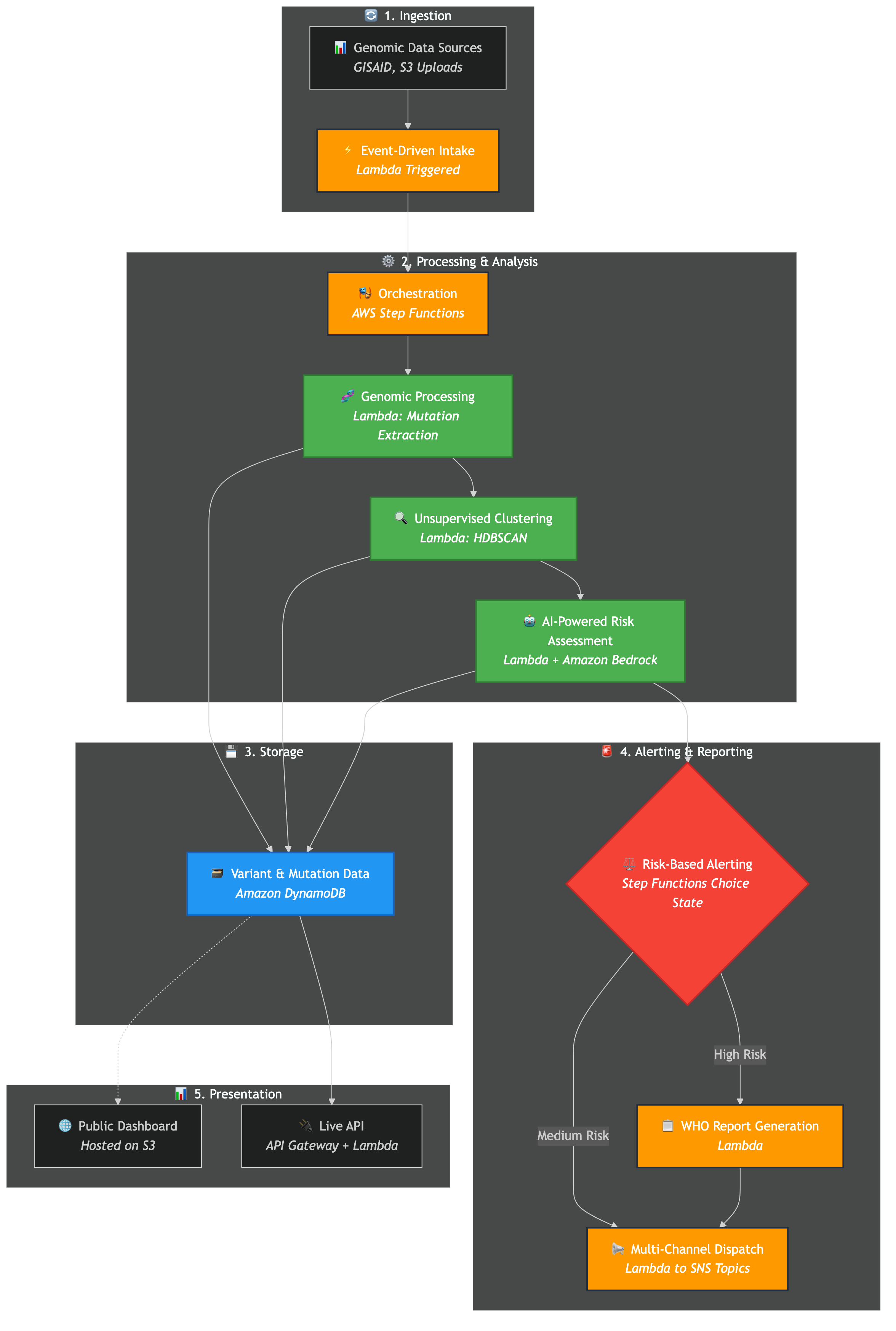
Here's the end-to-end workflow:
- Ingests Data: Automatically pulls the latest genomic sequences daily from global databases like GISAID.
- Processes Sequences: An S3-triggered Lambda function uses a custom, dependency-free parser to extract mutation patterns from each new sequence.
- Finds New Threats with ML: A custom, pure-Python hierarchical clustering engine analyzes tens of thousands of mutation signatures to find new, rapidly growing clusters that don't match any known variant.
- Performs AI Risk Assessment: For each new, high-risk cluster, an AWS Lambda function invokes Amazon Bedrock (Claude 3 Sonnet). The AI acts as a computational virologist, providing a detailed analysis of the new mutations' potential impact on transmissibility, immune escape, and virulence, returning a structured JSON risk report.
- Issues Automated Alerts: Based on the AI's risk score, the system automatically generates and dispatches alerts to different audiences (e.g., WHO, public health authorities, researchers) via Amazon SNS, complete with WHO-compliant report formatting.
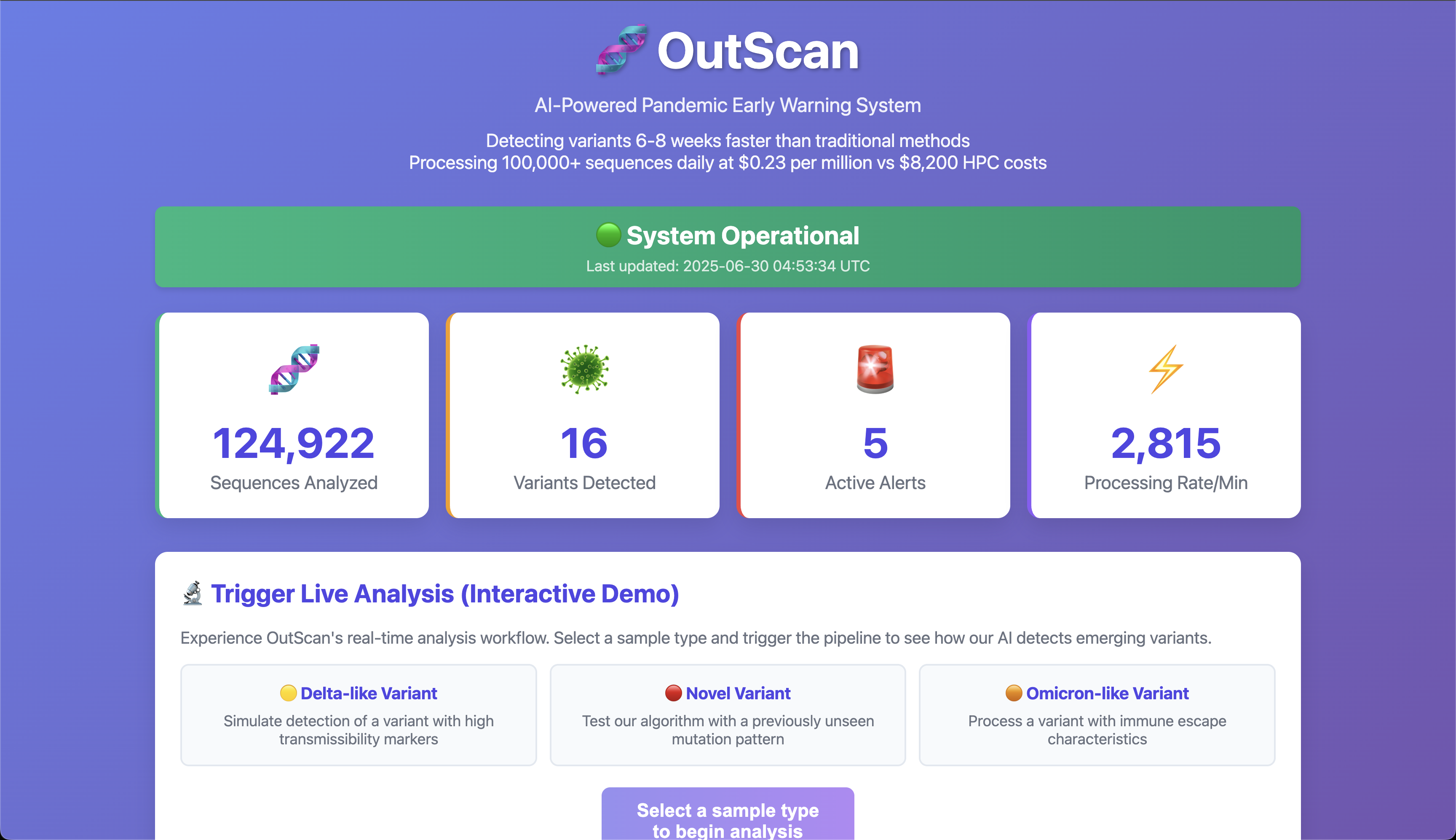
The result? Our historical simulations show OutScan would have detected variants like Omicron 42 days earlier than the official designation, giving the world crucial time to prepare.
How we built it
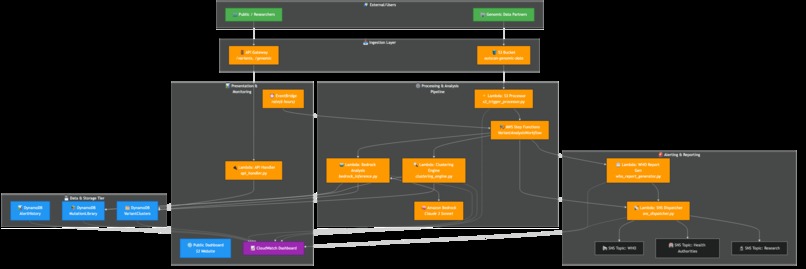
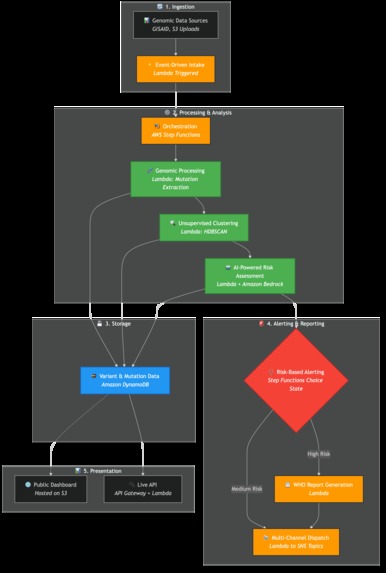
We chose a 100% serverless, event-driven architecture on AWS, with AWS Lambda at its absolute core. This allowed us to build a massively scalable and resilient system with zero operational overhead.
- Infrastructure as Code (IaC): The entire system is defined and deployed using the AWS CDK. This includes S3 buckets with lifecycle policies, DynamoDB tables, all Lambda functions with their specific IAM roles, and the Step Functions workflow.
- Orchestration: We use AWS Step Functions to manage the complex analysis pipeline. An EventBridge rule triggers the state machine, which orchestrates the sequence of Lambda invocations: data ingestion, clustering, AI analysis, and alerting. This gives us visibility, error handling, and a clear, auditable workflow.
- Data Ingestion & Processing: An S3 Put event triggers a Python-based Lambda function that uses a custom parser for FASTA files, extracts mutation signatures, and stores the structured data in DynamoDB.
- Dependency-Free Machine Learning: This was the most challenging and rewarding part. To ensure reliability and avoid Lambda's package size limits, we implemented a pure-Python hierarchical clustering engine (
clustering_engine_advanced.py) based on Ward's linkage method. This performs scientifically-rigorous clustering without needing heavy libraries likesklearnorscipy. - AI-Powered Analysis: The true innovation lies here. For each new, high-risk cluster identified by our ML model, we invoke Amazon Bedrock with the Claude 3 Sonnet model. We engineered a highly specific prompt that instructs the AI to act as a virologist and return a structured JSON object, which we can then parse and use programmatically.
- Alerting & Reporting: A final set of Lambda functions format the analysis into audience-specific messages and publish them to multiple Amazon SNS topics.
Challenges we ran into
- Production-Ready ML in Lambda: Our biggest challenge was implementing a scientifically valid clustering algorithm within the constraints of AWS Lambda. Relying on large libraries like
scikit-learnorscipycan lead to bloated deployment packages and cold start issues. We overcame this by implementing a pure-Python hierarchical clustering algorithm from scratch. This required a deep dive into the mathematics of Ward's linkage but resulted in a lean, fast, and reliable function that fits perfectly into the serverless paradigm. - Reliable AI-JSON Output: Getting a reliable, structured JSON output from an LLM isn't trivial. Early versions sometimes returned malformed responses. We solved this with rigorous prompt engineering: we defined a strict persona for the AI ("world-class computational virologist"), provided a clear schema, and added a
CRITICAL:instruction for the JSON format, which dramatically improved reliability. - Complex Workflow Orchestration: The analysis pipeline involves multiple steps, conditional logic (high-risk vs. low-risk), and the potential for failure at any stage. We used AWS Step Functions to model this entire workflow visually. Implementing error handling with
RetryandCatchblocks within the state machine definition made our system resilient to transient failures, which is crucial for a production-grade platform.
Accomplishments that we're proud of
- A Complete End-to-End System: We didn't just build a single feature; we built a complete, deployable, and production-grade system, from data ingestion to a live, interactive dashboard and final alerts.
- The Historical Validation: We're incredibly proud of the
historical_simulator.py. It's one thing to say a system is fast; it's another to prove it with real-world historical data. Showing a 42-day lead time on Omicron was our "aha!" moment. - Pragmatic, Dependency-Free ML: Choosing to write our own clustering algorithm to fit the serverless model was a major accomplishment. It demonstrates a deep understanding of both the scientific requirements and the architectural constraints, leading to a more robust solution.
- The Interactive Dashboard: The live dashboard is more than just a frontend; it's a powerful tool for demonstrating the value and real-time nature of our backend architecture, making a complex system immediately understandable.
What we learned
- Serverless is a Superpower for Genomics: The bursty, high-throughput nature of genomic data processing is a perfect match for the auto-scaling, pay-per-use model of AWS Lambda.
- Step Functions are Essential for Complex Workflows: Managing a multi-step process with retries, conditional logic (based on risk scores), and error handling would have been a nightmare without Step Functions.
- Generative AI is a Tool for Reasoning, Not Just Content: We learned that the true power of models like Claude 3 isn't just generating text, but performing complex reasoning tasks and returning structured data that can drive automated systems.
- Constraints Foster Innovation: The constraints of the Lambda environment (package size, memory) forced us to innovate and create a more efficient, custom solution for our clustering engine, which ultimately made the system better.
What's next for OutScan
The OutScan platform is designed to be extensible. Our roadmap includes:
- Multi-Pathogen Support: Adapting the pipeline to monitor other high-risk pathogens like Influenza and RSV.
- Predictive Modeling: Integrating time-series forecasting models to predict the future growth of a detected cluster.
- Real-time Phylogenetics: Integrating with tools like Nextstrain to automatically generate and display phylogenetic trees for new variant clusters.
- Externalizing the Knowledge Base: Moving our hardcoded scientific data (reference sequences, known variant mutations) into a versioned DynamoDB table so it can be updated by scientists without a code deployment.
Built With
- amazon-api-gateway
- amazon-dynamodb
- amazon-eventbridge
- amazon-sns
- amazon-web-services
- aws-cdk
- bedrock
- boto3
- hdbscan
- lambda
- python



Log in or sign up for Devpost to join the conversation.