-
-
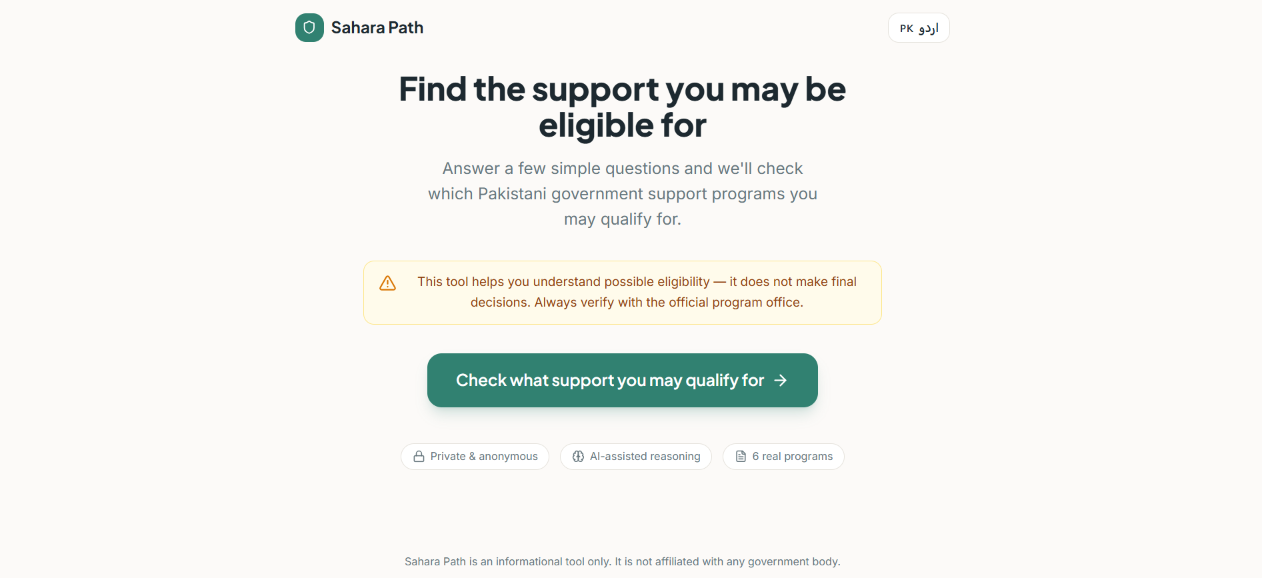
frontend interface in English
-
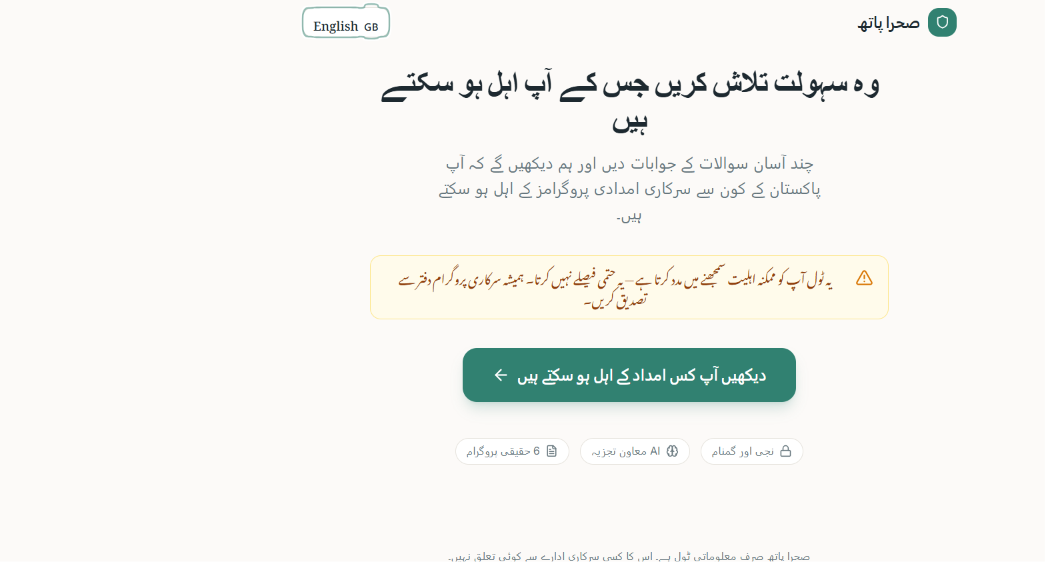
Frontend interface in Urdu
-
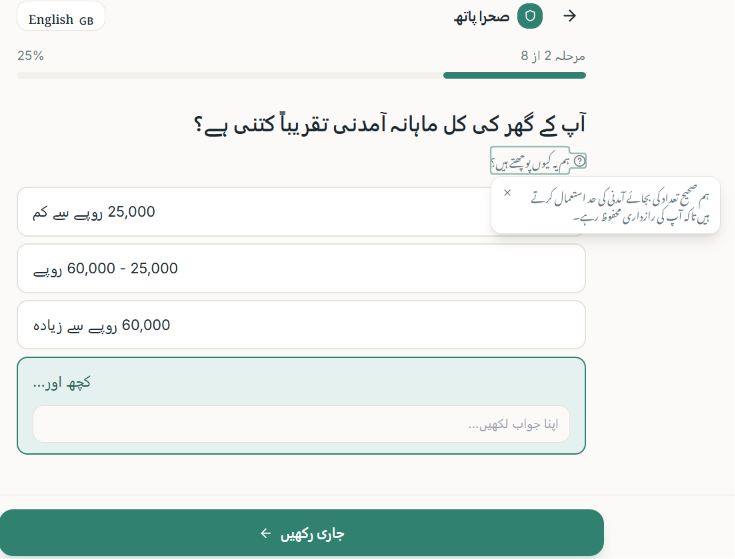
Eligibilty Check
-

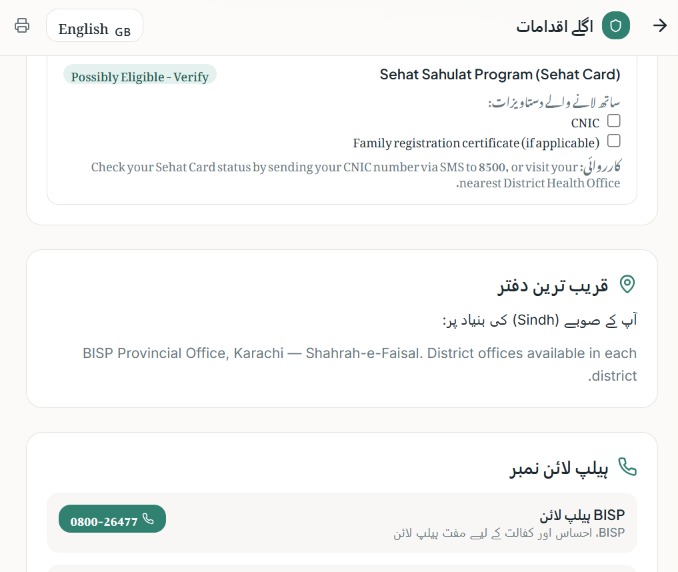
Results with cautions
-

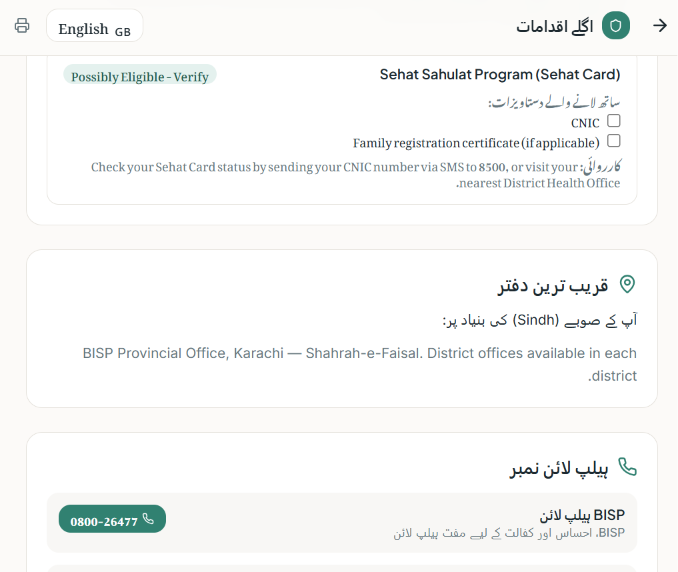
Searching Helplines and offices
-
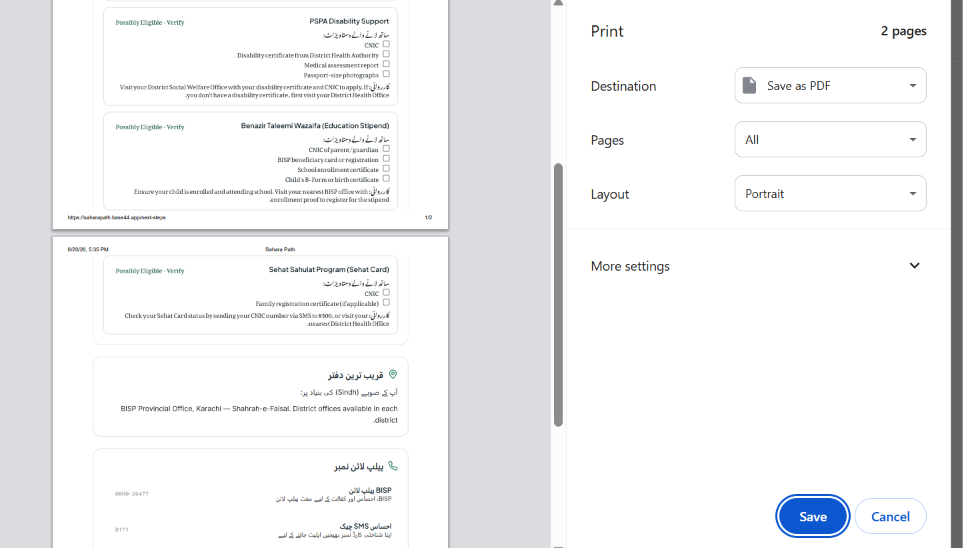
Printable results according to the checklist
-


Inspiration Millions of Pakistani families are eligible for support through programs like BISP, Ehsaas Kafaalat, the Sehat Sahulat health card, and others — but most never find out. Eligibility rules are scattered across different offices, paperwork is confusing, and people under financial stress rarely have the time, literacy, or confidence to dig through bureaucratic criteria just to learn whether help exists for them. We wanted to build something that does that work for them: ask a few plain-language questions, and turn confusing eligibility criteria into a clear, honest answer about what to check next — without ever pretending to be the final word.
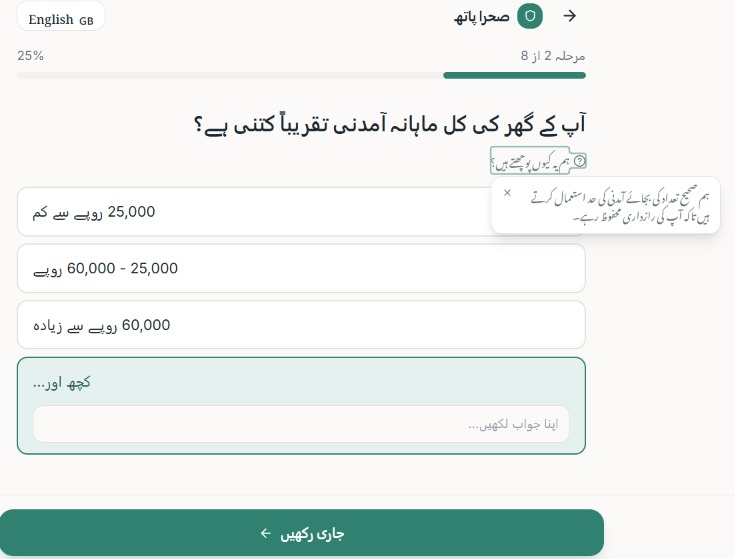
What it does Sahara Path is an AI-powered Benefits Navigator. A user answers a short, conversational 8-question intake (province, household income band, employment status, dependents, disability status, widow/single-parent status, school enrollment, and existing NSER/BISP registration) — one question per screen, with a "why we ask this" hint on each for transparency. Behind the scenes, a deterministic rules engine checks those answers against structured eligibility criteria for real Pakistani programs (BISP, Ehsaas Kafaalat, Sehat Sahulat, Benazir Taleemi Wazaifa, Zakat-based emergency assistance, and PSPA disability support). The result is shown as one of four honest verdict labels — Likely Eligible, Possibly Eligible – Verify, Likely Not Eligible, or Insufficient Information — never "approved" or "qualified." Each result card includes a plain-language AI explanation, a confidence indicator, a "Why am I seeing this?" breakdown of matched criteria, a required-documents checklist, and a concrete next step with an official source link. A persistent banner reminds users throughout that these are possibilities to explore, not guarantees. The whole flow works anonymously, and is now available in both English and Urdu.
How we built it We built Sahara Path on Base44, using its built-in NoSQL database for three core tables — Programs, IntakeSessions, and EligibilityResults — and its built-in auth for the optional "save my results" feature. The core of the project is a two-layer AI architecture, kept deliberately separate so the reasoning stays auditable:
- Layer 1 — Rules Engine: deterministic conditional logic that checks a user's intake answers against each program's structured
eligibility_rulesJSON. No LLM involved, no hallucination risk — this layer alone decides the verdict. - Layer 2 — LLM Explanation Layer: we pass that already-decided verdict, the user's specific answers, and the program description to Claude with a system prompt that explicitly forbids it from overriding the verdict or claiming false certainty. Its only job is a warm, 2–3 sentence plain-language explanation using uncertainty language ("may qualify," "worth verifying") and honest flags for missing information.
Because we had a limited number of Base44 message credits, we treated the build as close to one-shot: we wrote the entire data model, app flow, and AI architecture into a single detailed build prompt before touching Base44, then spent our remaining credits on targeted fixes rather than open-ended iteration.
Challenges we ran into The biggest constraint was credits, not code — with a capped number of Base44 messages, every prompt had to count, so most of the real engineering happened upfront in planning rather than in back-and-forth debugging. Even so, a few bugs surfaced once the app came together: mismatches between the rule engine's verdict and the badge label the UI rendered, and a couple of edge cases where "Not sure" answers weren't lowering the confidence indicator the way they should. We used our remaining credits carefully to track those down rather than rebuilding. We also added Urdu language support after the initial build, which meant going back through every intake question, hint, verdict label, and explanation string to localize it without breaking the strict verdict-label rules the rules engine depends on.
Accomplishments that we're proud of We're proud that the rules engine and the LLM explanation layer stayed cleanly separated end to end — the AI never decides eligibility, it only explains a decision that was already made deterministically. That separation was the single most important design choice for making the tool auditable and trustworthy rather than just another chatbot guessing at benefits. We're also proud of shipping bilingual (English/Urdu) support, since the people this tool is meant to help are often more comfortable in Urdu, and of landing a calm, mobile-first, low-anxiety design for users who are likely under real financial stress.
What we learned We learned how much time is saved by front-loading the planning — writing out the data model, app flow, and exact AI system prompt before spending a single build credit meant far fewer wasted iterations. We also learned, concretely, why separating deterministic logic from LLM reasoning matters: it made every bug easier to isolate (rule engine or explanation layer?) and gave us a much stronger responsible-AI story than disclaimers bolted on after the fact. Localizing into Urdu late in the build also taught us that even small UI copy, like "why we ask this" tooltips, needs to be designed for translation from day one.
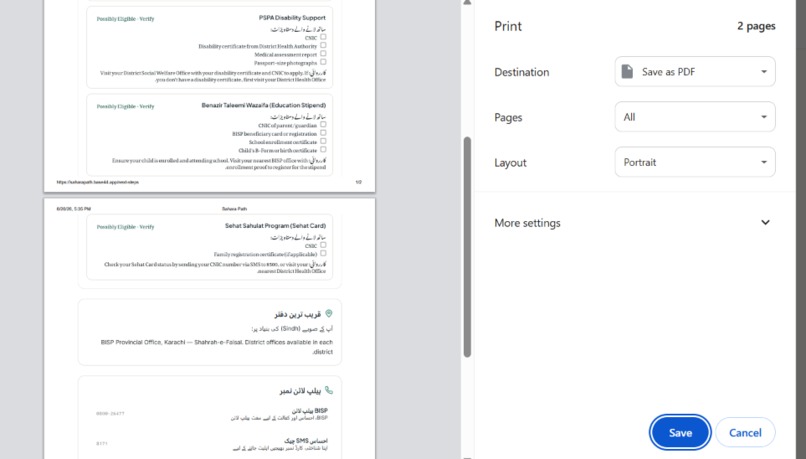
What's next for Sahara Path Next, we'd like to expand the seeded program list beyond the initial 6–8 to cover more provincial and Zakat-administered schemes, connect to a real office-locator API instead of the static guidance pattern we used for the MVP, and add a save/export-as-PDF checklist so users can carry a physical printout into an office, important for users without continuous internet access. We'd also like to add more regional languages beyond Urdu and English, and explore voice input for users with lower literacy.
Built With
- anthropic-api
- base44
- claude
- javascript
- llm
- nosql
- react
- tailwindcss
- vite

Log in or sign up for Devpost to join the conversation.