About the Project
Inspiration
Cold outreach is broken. Sales teams spend hours manually searching Google Maps, copying business names into spreadsheets, visiting websites one by one, and writing the same research notes over and over. We wanted to ask a simple question: what if you could type a plain English brief like "independent coffee roasters in Portland, OR" and get a fully enriched lead list in under a minute?
That question became Outreach OS.
How We Built It
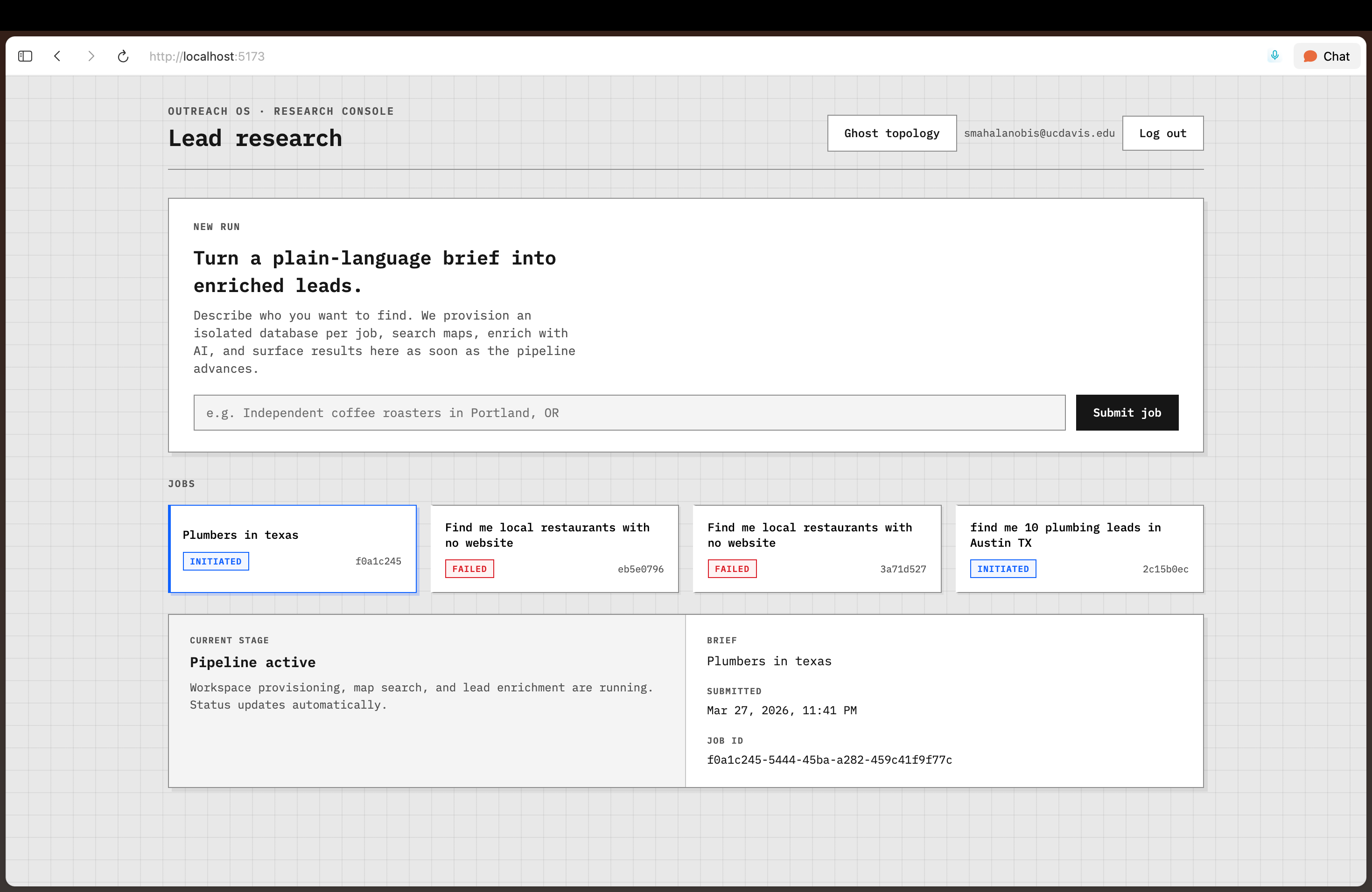
The system is a multi-layer pipeline. A user submits a query through the React frontend, which hits a FastAPI backend. The backend provisions a fresh, isolated Postgres database for that job using Ghost's MCP server, then hands off to a research agent.
The agent runs three sequential phases:
- Search -- HasData's Google Maps scrape API returns businesses matching the query, including name, phone, address, website, and rating.
- Enrich -- For each lead, the agent scrapes the business website with BeautifulSoup and passes the content to GPT-4o-mini, which generates a 2 to 3 sentence research summary highlighting services, business signals, and potential pain points. Email addresses are extracted via regex.
- Write -- Enriched leads are persisted to the per-job Ghost database via asyncpg.
The frontend polls for status updates and surfaces leads in a clean table the moment the pipeline completes. Each job gets its own isolated database, and completed jobs can be forked -- Ghost snapshots the database instantly so you can re-run research on a fresh copy without touching the original.
The per-lead cost follows a simple model. If $n$ leads are processed, with an average enrichment cost of $c_e$ per lead and a search cost amortized across the batch as $c_s$, the total cost is approximately:
$$C(n) = n \cdot c_e + c_s$$
At current pricing, $c_e \approx \$0.001$ (OpenAI) and $c_s \approx \$0.002 \cdot n$ (HasData), giving roughly $C(10) \approx \$0.03$ per run.
What We Learned
Database-per-job isolation is a genuinely powerful pattern. Ghost made it trivial to spin up a fresh Postgres instance per query and fork it later, which gave us clean data boundaries without any multi-tenant complexity. We also learned that website scraping is the dominant source of latency -- the $O(n)$ sequential enrichment loop is the obvious next optimization target, since parallelizing it would bring 10-lead runs from ~45 seconds down to ~10 seconds.
Challenges
The biggest challenge was wiring the Ghost MCP server into an async FastAPI process correctly. MCP stdio sessions are stateful and cannot be shared across concurrent requests, so we had to serialize all Ghost calls behind an asyncio lock. Getting the fork workflow right -- provisioning, schema migration, research re-run, and status tracking -- required careful coordination across the orchestrator, the Ghost MCP client, and the master database.
Auth0 JWT validation in an async context and keeping the frontend polling loop snappy without hammering the API were smaller but real friction points.
Built With
- anthropic-mcp-python-sdk
- asyncpg
- auth0
- auth0-react-sdk
- beautifulsoup4
- docker
- fastapi
- ghost
- ghost-database-provisioning
- ghost-mcp-server
- hasdata-google-maps-search-api
- httpx
- jwt
- mcp-server
- openai-gpt-4o-mini
- postgresql
- pydantic
- python-3.11
- python-dotenv
- python-jose
- react-19
- react-router
- rs256
- truefoundry
- uvicorn
- vite

Log in or sign up for Devpost to join the conversation.