-
-
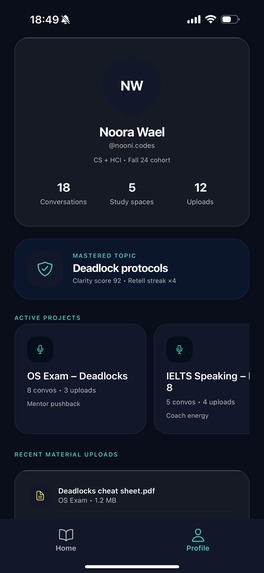
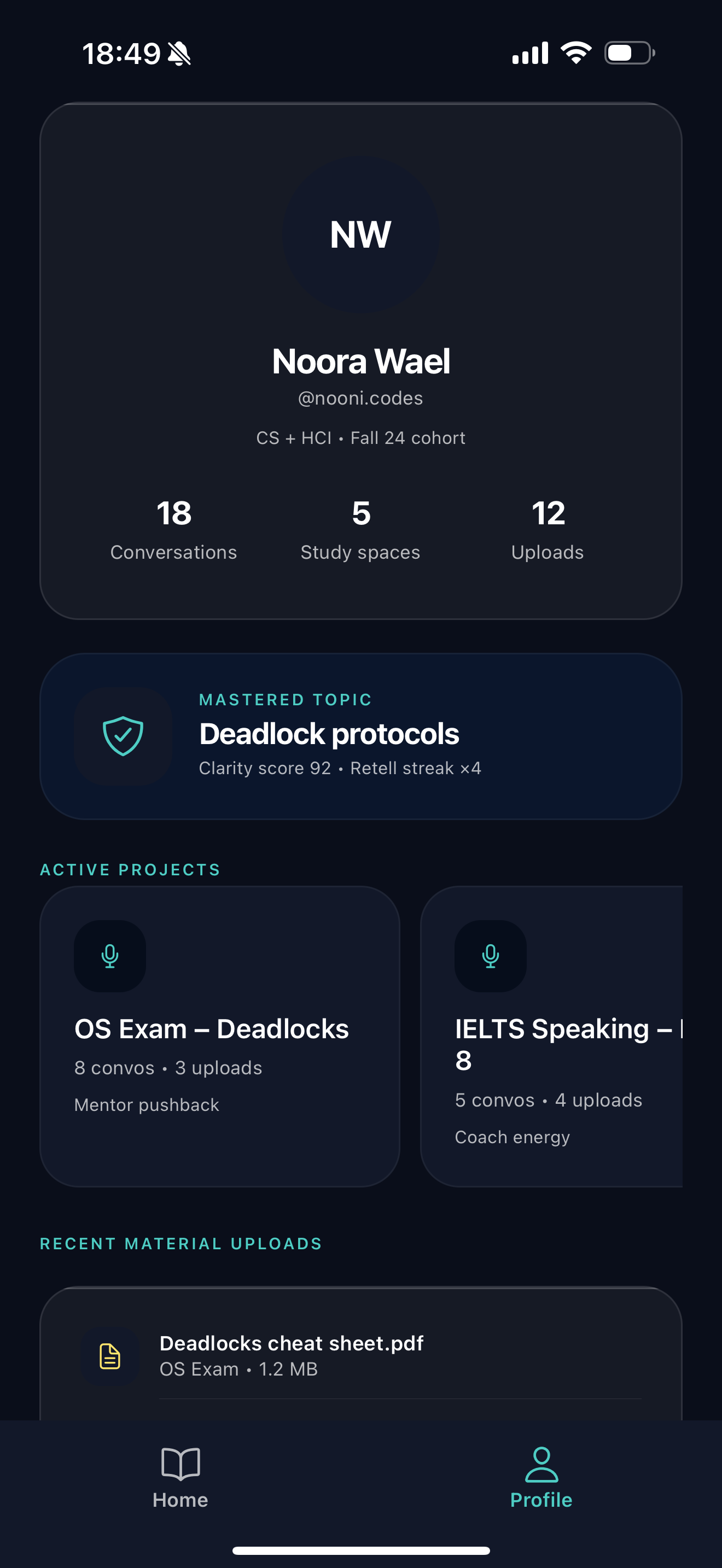
profile page
-
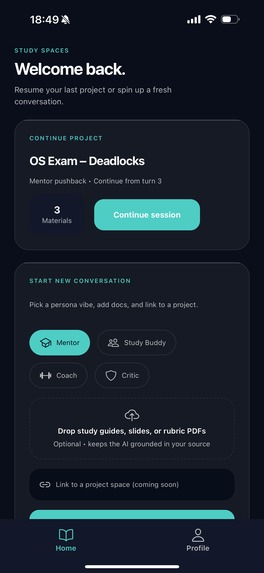
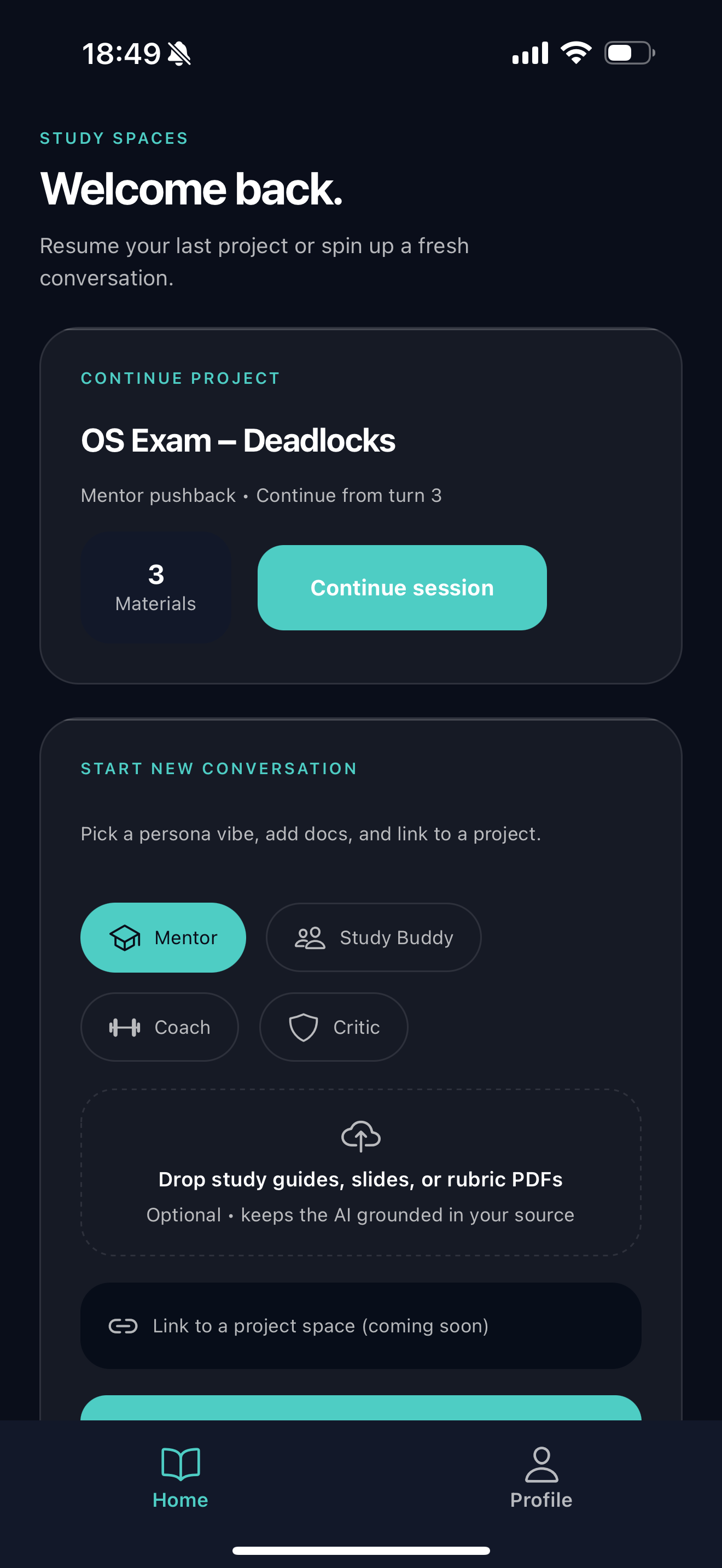
home page
-
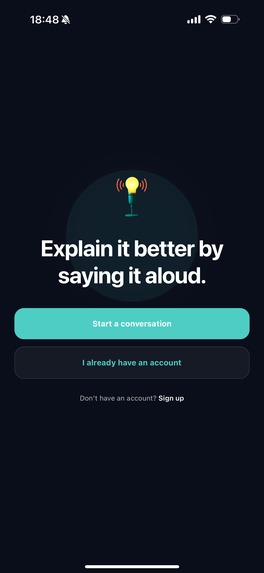
entry page
Inspiration
We've all been there: staring at notes the night before an exam, re-reading the same paragraph five times, wondering "do I actually understand this?" Traditional studying is passive, you highlight, make flashcards, but never really know if you get it until the test reveals the gaps.
What if studying felt more like teaching a friend? What if you could explain concepts out loud and instantly know where your explanation is strong, vague, or just plain wrong?
As Richard Feynman said: "If you can't explain it simply, you don't understand it well enough." That's why we built Outloud, to turn explaining into the most effective (and fun) way to study.
What it does
Outloud is a voice-first study companion that makes learning active and conversational:
- Pick a topic - Choose from OS deadlocks to IELTS speaking to startup pitches
- Choose your AI persona - Mentor (patient guide), Critic (tough examiner), Buddy (learning peer), or Coach (energetic motivator)
- Explain out loud - Record yourself explaining the concept in your own words (3 turns max - for demo period)
- Get AI feedback - Each persona responds in their unique style with follow-up questions, pushing you to think deeper
- See your breakdown - After 3 turns, get evaluated on four dimensions:
- Coverage - Did you hit the key concepts?
- Clarity - Was your explanation structured and precise?
- Correctness - Were your facts accurate?
- Causality - Did you explain why, not just what?
The killer feature: A visual heatmap that color-codes every segment of your explanation:
- 🟢 Strong - Accurate, clear, demonstrates understanding
- 🟡 Vague - Hand-wavy, incomplete, filler words ("like", "kind of", "stuff")
- 🔴 Misconception - Factually wrong, contradicts the material
No more wondering "did I explain that well?" The heatmap shows you exactly where you were fuzzy, with specific notes on each segment.
How we built it
Mobile App: React Native + Expo
- Neumorphic UI with glassmorphism and dark mode
- Audio recording using
expo-audiohooks - Real-time playback of AI voice responses
Backend API: Node.js + Express + TypeScript
- RESTful API with JWT authentication
- Conversation management with 3-turn limit
- File upload handling with Multer
- Supabase integration for database and storage
Speech-to-Text: Python + FastAPI + Faster Whisper
- High-quality transcription with word-level timestamps
- Microservice architecture for scalability
AI Layer: OpenAI GPT-4o-mini
- Four persona-specific system prompts with unique teaching styles
- Context-aware responses using conversation history + study material
- Evaluation algorithm that analyzes full transcript across 4 dimensions
- Heatmap generation with segment-level verdicts and explanatory notes
Text-to-Speech: OpenAI TTS
- Persona-matched voices (Onyx for Mentor, Fable for Critic, Nova for Buddy, Echo for Coach)
- Natural-sounding responses that play immediately
Database: Supabase (PostgreSQL)
- Users, conversations, messages, evaluations tables
- Storage buckets for user audio and AI-generated TTS files
Data Flow:
User speaks → Mobile records → Upload to Supabase Storage
→ Python STT transcribes → GPT-4 generates response with study material context
→ OpenAI TTS creates voice → Save both messages
→ Play AI audio → After 3 turns → GPT-4 evaluates entire transcript
→ Generate scores + heatmap → Display results
Challenges we ran into
Audio Engineering: Getting recording and playback to work seamlessly across iOS/Android was harder than expected. Permissions, audio session conflicts, and file format compatibility all caused headaches. We solved this using expo-audio's new hooks API and careful audio mode management.
Evaluation Algorithm Design: How do you fairly score someone's explanation? Early versions were too harsh (marking trivial mistakes as "misconceptions") or too lenient (giving high scores to vague rambling). We iterated on GPT-4 prompts with specific rubrics, examples, and the instruction to focus on understanding rather than perfection.
Heatmap UX: Visualizing feedback without overwhelming users was tricky. Our first version color-coded every sentence (too granular), then every word (too messy). The final segment-based approach with expandable notes struck the right balance clean, scannable, informative.
Real-time Feel: Voice conversations should feel synchronous, but we had 8-15 seconds of async processing (transcription + AI + TTS). We solved this with loading states, optimistic UI updates, and immediately playing AI audio upon response to maintain conversational flow. It still feels slow sometimes but I am continuously working on it
Accomplishments that we're proud of
Four Distinct AI Personas - Each has a unique voice, teaching style, and personality. Mentor uses Socratic questioning. Critic challenges every claim. Buddy learns alongside you. Coach celebrates your wins. It genuinely feels like talking to different people.
Intelligent Heatmap - Doesn't just say "good" or "bad"—it pinpoints exactly which phrases were strong ("correctly identified all four conditions"), vague ("used 'kind of' without explaining"), or wrong ("confused hold-and-wait with no preemption"), with contextual notes explaining why.
Seamless Voice UX - The full loop (record → transcribe → AI responds → hear AI speak) feels natural and conversational, not clunky. Users forget they're talking to an app.
Beautiful Design - Neumorphic UI with smooth animations and thoughtful microinteractions. Studying shouldn't look boring—our interface feels premium and engaging.
Full-Stack TypeScript - End-to-end type safety from mobile → API → database schemas means fewer bugs and better developer experience.
What we learned
Voice interfaces force clarity - When you have to speak your thoughts, you can't hide behind vague hand-waving like you can in writing. It forces you to actually understand what you're saying.
AI persona design is an art - The difference between "helpful" and "annoying" is incredibly subtle. Tone, question pacing, and encouragement balance matter more than we expected.
Visual feedback beats numeric scores - Users care way more about "you said 'stuff' too much here" than "your clarity score is 75/100."
Different learners need different vibes - Some people want tough love (Critic), others want a supportive peer (Buddy). One-size-fits-all doesn't work for learning.
Audio engineering is way harder than we thought - Permissions, audio formats, session management, playback timing there's so much complexity hidden under "record audio" and "play audio."
What's next for Outloud
Short-term:
- Custom topics (upload your own PDFs, slides, notes)
- Retell feature (re-explain after seeing your heatmap)
- More demo topics across subjects (CS, biology, business, languages)
Medium-term:
- Progress tracking (see scores over time, identify patterns)
- Study groups (explain to real peers, not just AI)
- Spaced repetition (smart reminders to practice before you forget)
- Multi-language support (practice explaining in Spanish, Arabic, Mandarin)
Long-term:
- Classroom mode (teachers assign topics, monitor student progress)
- Expert review (human tutors annotate AI-generated heatmaps)
- Voice analytics (track pace, filler words, clarity improvements over time)
- Public topic library (community-created study materials)
Learning should be active, not passive. Outloud makes explaining easy, fun, and insightful. Because understanding isn't about memorizing facts it's about being able to explain, defend, and teach what you've learned.
Let's make studying feel less like work and more like leveling up. 🚀
---
Built With
- express.js
- node.js
- openai
- python
- react-native
- supabase
- typescript
- whisper

Log in or sign up for Devpost to join the conversation.