-
-
Model concept
-
MNC calculation
Proof of Motivation
According to climate change, the environmental impact would be raised in the global conference. One of the challenges for reducing the negative effect is to capture carbon dioxide (CO2). Many research papers proposed Metal-Organic-Frameworks (MOFs) to solve this challenge. This framework has the ability to adsorb and desorb CO2, depending on the structures of MOFs. However, the researchers found difficulties to develop the MOF structures. Our team also have been being interested in this problem. That's why our team would join in this competition and solving the problem by using Machine learning techniques.
Project definition
The objective of our team is to predict CO2 working capacity, which plays a vital role in capturing CO2. What's more, our team would apply both ML and NN models to build a regression model
Work Flow Chart
0. Research relevant paper
- Scrutinise feature important in CO2 working capacity(Anderson et al., 2018)
- Study Graph Neural Network (GNN) (Zhou et al., 2021)
- Examine zeo ++ framework
1. Data Cleansing
- Delete a null value
- Delete zero value
- Delete extreme outliers
2. Feature Engineering
- Fixed accessible surface area & void volume with zeo++🔥🔥
- Extracted LCD, Di – Largest cavity diameter or the diameter of the largest included sphere
- Extracted PLD, Df – Pore limiting diameter, or the diameter of the largest free sphere
- Engineered some features e.g. void volume, density
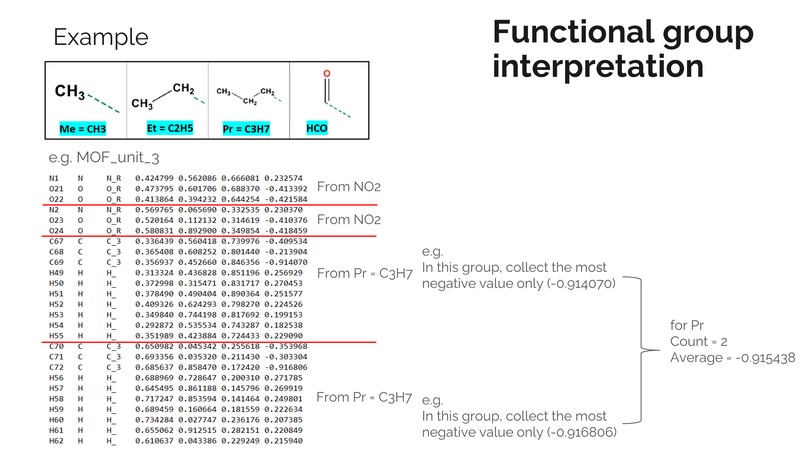
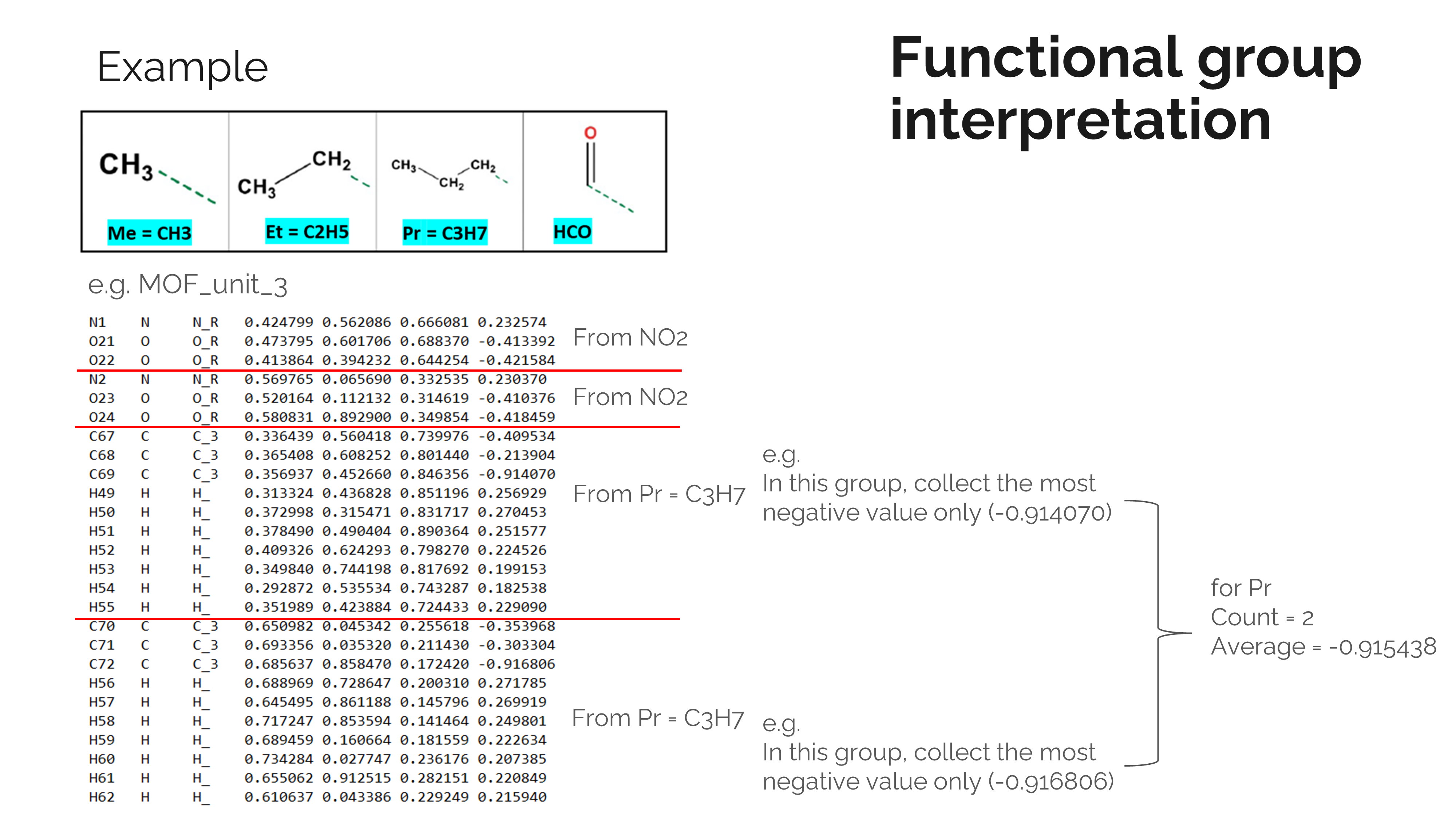
- Extracted charges of metal atom in MOF and most negative charge (MNC) from functional group
- Categorise topology class as a one-hot encoding
- Retrieve coordinated structure of MOF cell e.g. cell length a, cell length b, cell length c, cell angle alpha, cell angle beta, and cell angle gamma
- Classify the Bimodal distribution of CO2 working capacity by determining the threshold as a 25 mL/g (CO2 class label)
3. Building model
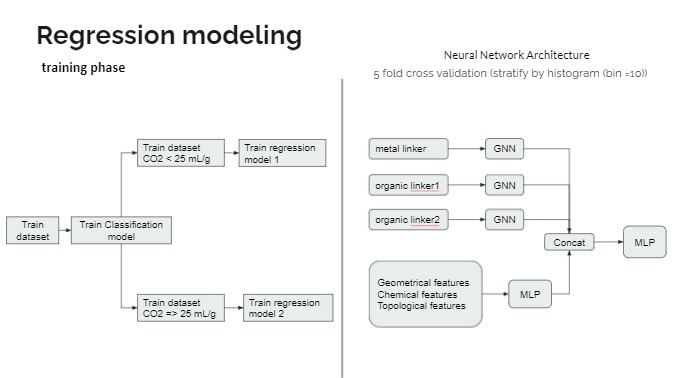
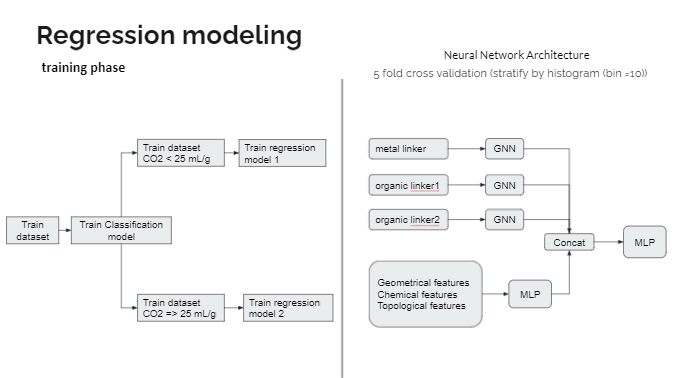
Our hypothesis is from visualizing the distribution of CO2 working capacity and found to be bimodal. One has negative capacity ranged to small values of positive capacity. The other has only positive values. So we think that reflects different kinds of MOF in the dataset. The former with negative and low values of working capacity might be flexible MOF, in which it collapses after a certain pressure is applied to cause negative gas adsorption (NGA) (Krause et al., 2016). The latter is rigid MOF, where more CO2 molecules can be occupied at higher pressures. Therefore, we use two regression models to predict two different kinds of MOF. The training dataset was split into two categories using 25 mL/g as a threshold. Then they were trained to build a classification model(MLP) for use in the test set. And two regression models were built subsequently.
In our team, we experiment with a variety of models both ML and NN based model
- Lightgbm of sci-kit learn
- Catboost of sci-kit learn
- GNN
- MLP of PyTorch with Prelu and relu activation functions*(Best model)*
- Conv1d and hidden layer with a dense layer of Keras with elu and relu activation function
4. Train the model
- Train two regression models, depends on CO2 class label (less than 25 mL/g and over 25 mL/g)
- Use GNN for metal linker and organic linker
- Use ANN for the rest features
- Apply cross-validation with 5 folds
- Ensemble 5 models to predict CO2 working capacity
Project challenges
Uncleaned dataset
Our team spends at least a few weeks scrutinizing all features and characteristics of the chemical properties. We found that in spite of the surface area would be fixed, some features might still be zeros such as volume. Moreover, some values of heat adsorption and selectivity were unexpectedly high. Fortunately, we found some research papers that we should eliminate extreme outliers, affecting the accuracy of the model.
Unknown territories field
Actually, this is the first time for us to join the competition about MOFs which is quite a chemistry. We extremely spent time researching what is MOFs and what kind of properties that relevant to capturing CO2 in any framework. Only 1 person in my team is familiar with the chemistry field. However, we finally achieve to research the properties. The is more devoted to reading a thousand papers, the gain wisdom in your own. 😃😃
The proud accomplishment in this project
Convert a categorical variable of the functional group into numerical data We found that the functional group could have been transformed from categorical variable to numerical data by using NetworkX. We called a subgraph isomorphism problem. We build a subgraph representing the connection of atoms in a specific functional group and screen this subgraph all over MOF to extract MNC values and the number of functional groups on each MOF. MNC is the average most negative charge on each FG. This feature was chosen based on the fact that CO2 molecule has a partial positive carbon atom that is generally attracted to the negative charged site
The score that we achieve We consumed so much time to reduce the LMAE loss from 2.13685 to 1.2196. It is a very challenging task for us to develop the model even we could not have a meeting physically. We are really proud of it.
Learned outcome
💻Hard skills💻
- Revise the knowledge that is relevant to chemical properties when we studied in high school or university
- Explore the new tools such as iRASPA, Zeo++, PyCaret , Openbabel, RDkit, Pywindow
- Learn GNN technique and SMILES representatives
👨💼Soft skills👩💼
- How to successfully communicate and complete competition even never physical meeting
- Working as a team
What's more to tell
If we have other opportunities to work with related topics, we will not hesitate to join the valuable competition as same as this contest. And we would like to say a huge thank you to the moderators and competitors for sharing valuable knowledge. 🙏🙏🙏










Log in or sign up for Devpost to join the conversation.