-
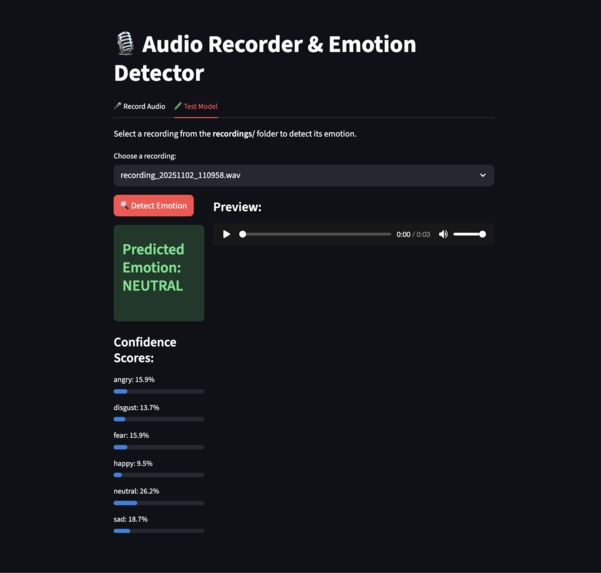
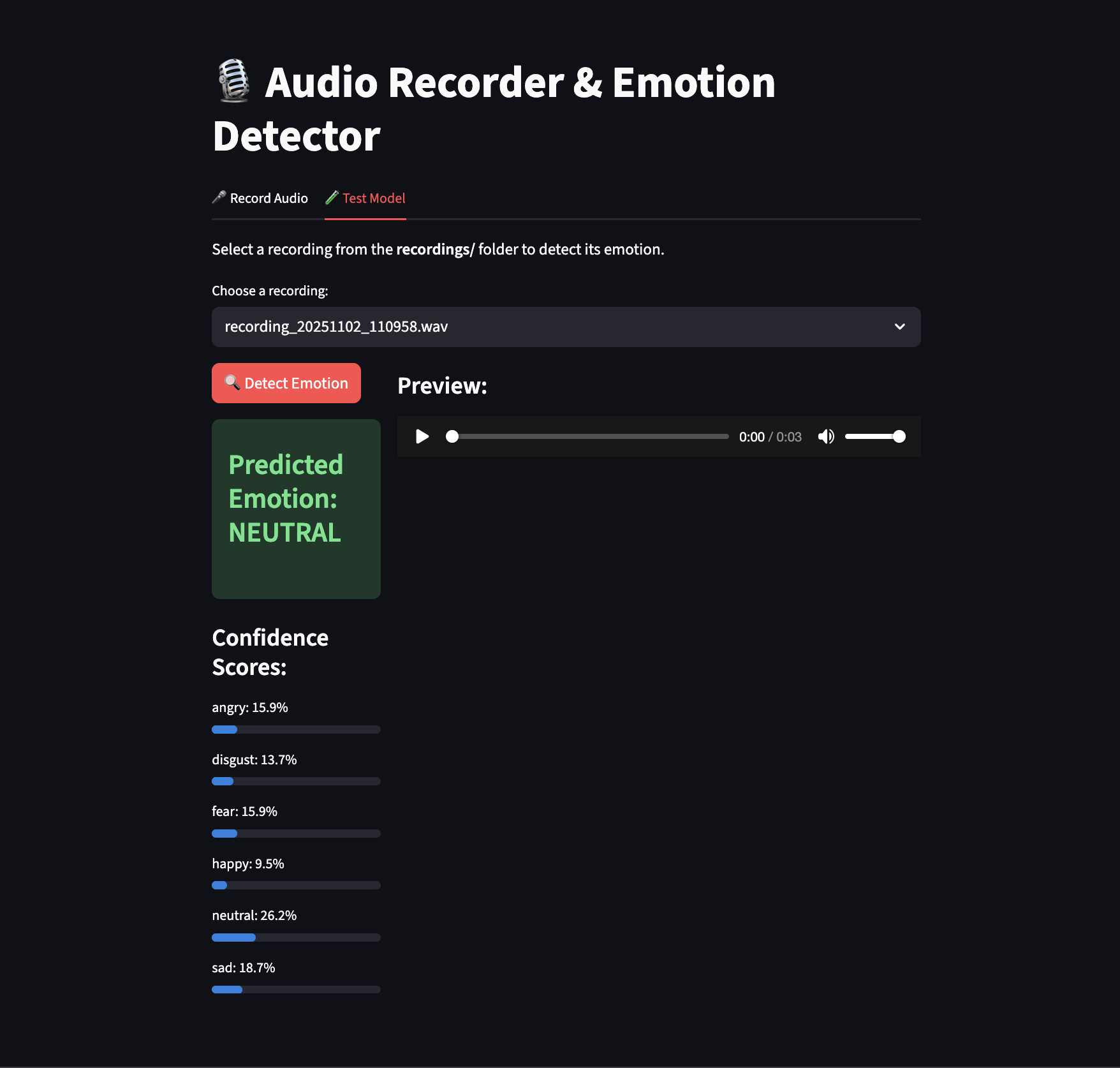
Demo
Inspiration
We wanted to challenge ourselves with a task that is not natural for machine learning. We were convinced that, using a rich set of audio features, we could train a deep learning model capable of detecting emotions from speech alone.
What it does
EmotionNet reads from a live audio feed, performs Fourier transform analysis, and applies convolutions over the time-frequency spectrogram. Using a short-term long-term memory (LSTM) module, it can convert input audio into a 6-class emotion prediction.
How we built it
We combined various datasets, including RAVDESS (Ryerson Audio-Visual Database of Emotional Speech and Song), CREMA-D, TESS (Toronto Emotional Speech Set), and SAVEE (Surrey Audio-Visual Expressed Emotion).
These datasets contain audio recordings of speakers pronouncing a variety of words and sentences in six different tones: ["angry", "disgust", "fear", "happy", "neutral", "sad"].
We experimented with several architectures, including:
A four-layer CNN with ReLU activation between each layer and a fully connected layer.
An MLP-LSTM model with two linear layers, an attention module, and a fully connected layer.
Both models achieved a maximum validation accuracy of around 57% with a batch size of 32. We chose the CNN-based model for our demo because of its practical implementation.
A final web interface was created using Streamlit to demonstrate the capabilities of our model. An audio recording function was implemented so users could run their own audio inputs through the network.
Challenges we ran into
Our biggest bottleneck was optimizing the model’s memory usage, as we ran out of GPU memory during training. To address this, we reduced the dimensionality of data through the convolutional layers, compared the total number of parameters in our models, and ensured GPU memory was freed automatically.
Another challenge was fast convergence during training. After a certain number of epochs, the accuracy plateaued.
We tried different strategies to reduce gradient vanishing, such as:
Performing data augmentation on the spectrograms
Normalizing the power in the spectrograms
Accomplishments we're proud of
We fine-tuned many hyperparameters to optimize our model architecture, including the CNN itself, which was dynamically programmed in terms of number of layers and input/output channel dimensions.
We successfully merged the four datasets into a single one, which helped generalize our model.
What we learned
We learned how to use Streamlit and deepened our understanding of PyTorch.
What's next for EmotionNet
We plan to add modularity by implementing a network capable of analyzing visual emotions alongside speech.





Log in or sign up for Devpost to join the conversation.