-
-

Otter — Governed Change Control for LLM Runtimes. 10 agents + 3 deterministic gates on UiPath Maestro. LLM proposes, rules decide.
-
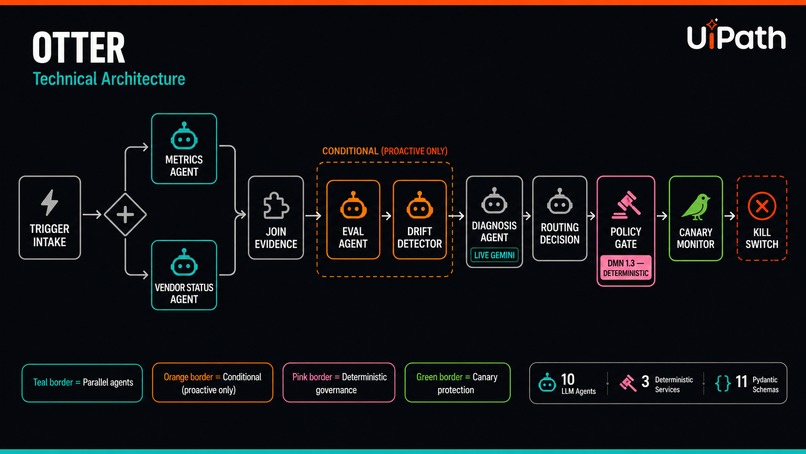
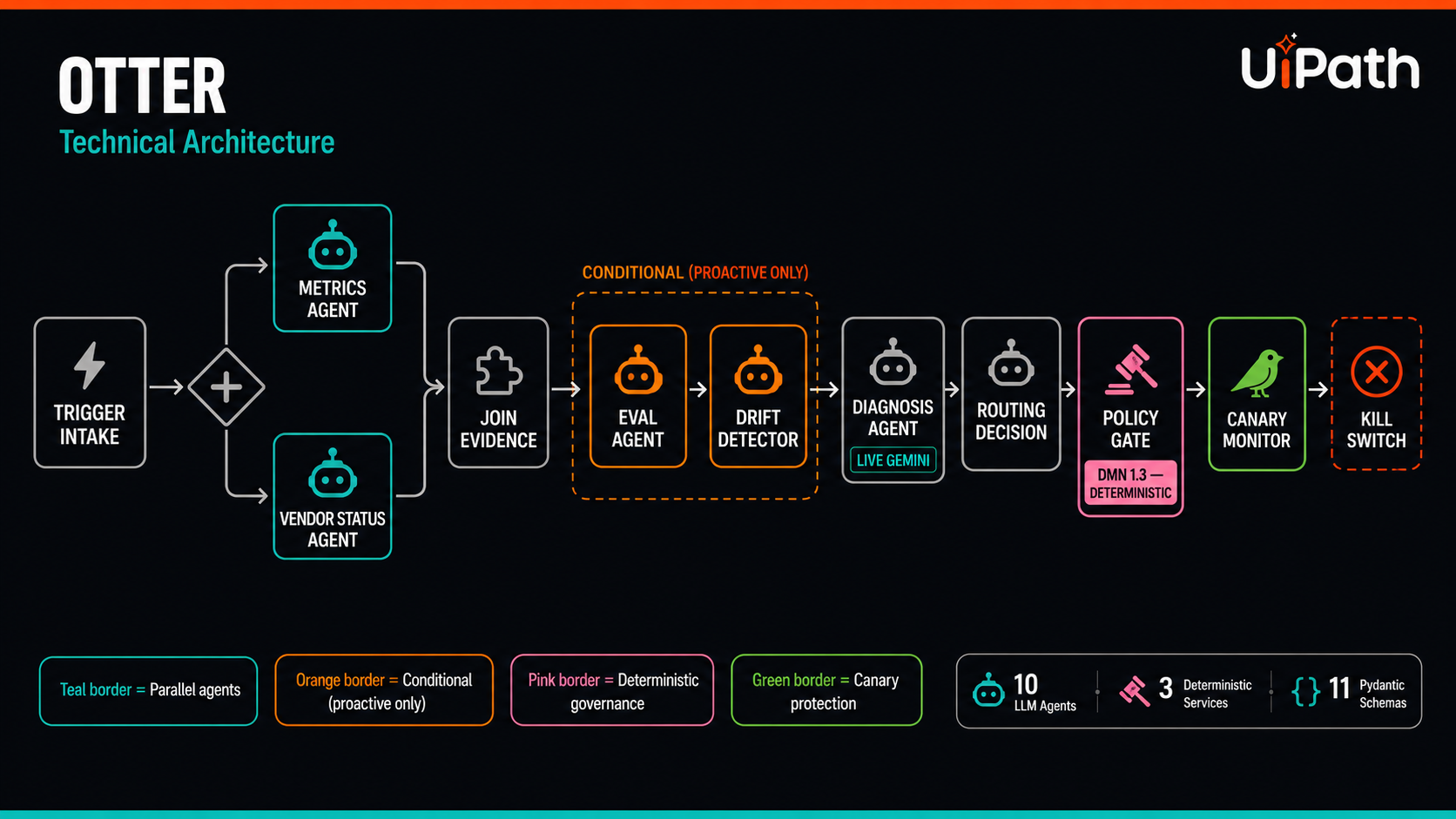
10-node BPMN pipeline: parallel evidence, Gemini diagnosis, DMN PolicyGate, canary kill-switch. 11 Pydantic schemas enforce typed contracts.
-
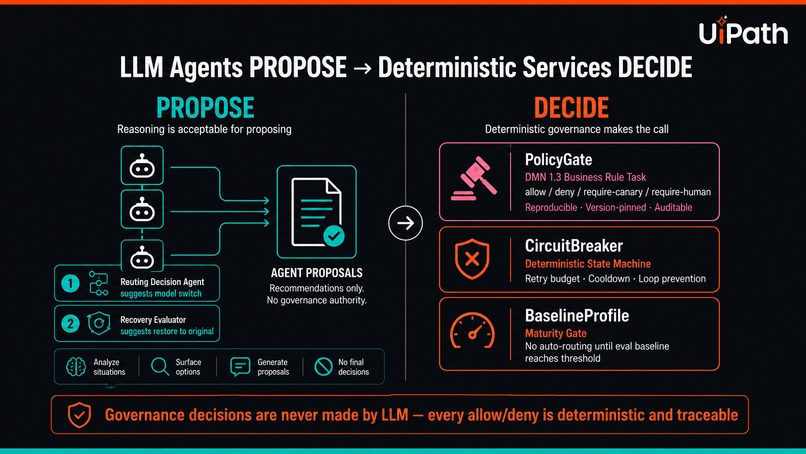
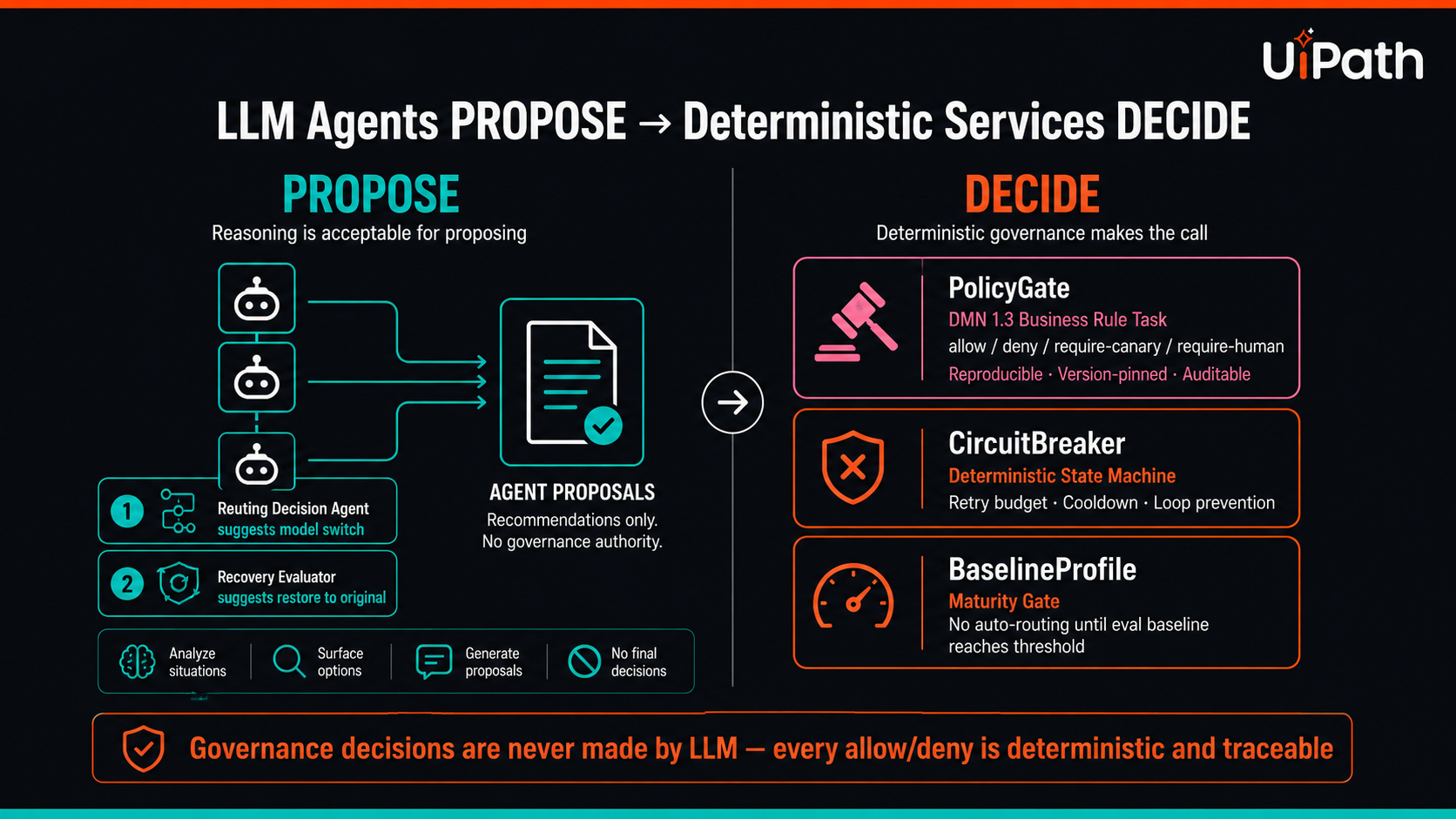
LLM agents propose, deterministic services decide. PolicyGate, CircuitBreaker, BaselineProfile — every allow/deny is reproducible.

Inspiration
When a production LLM provider degrades, teams scramble to switch models manually — no evidence trail, no approval gate, no rollback plan. We wanted a workflow that makes model routing a governed, auditable process instead of an ad-hoc decision.
What it does
Otter is a 10-node BPMN pipeline built with LangGraph and deployed on UiPath Maestro. Given an incident trigger (reactive degradation or proactive drift detection), it runs:
- Parallel evidence gathering — metrics agent and vendor status agent fan out simultaneously
- Conditional evaluation — eval and drift detection only fire when the trigger is proactive
- Diagnosis — Gemini-powered root cause analysis with severity classification
- Routing proposal — candidate model ranking with quality/cost tradeoffs
- Policy gate — deterministic DMN 1.3 business rule: auto-approve if confidence > 0.6 and severity != CRITICAL, else require human approval via Action Center
- Canary monitor — kill-switch that rolls back the route if metrics regress during the guard window
Every node exchanges typed Pydantic v2 contracts with extra='forbid' — the graph rejects malformed payloads at runtime. The key architectural decision: LLM agents propose routes, but deterministic services (PolicyGate, CircuitBreaker, BaselineProfile) make the final allow/deny. Governance decisions are reproducible, version-pinned, and auditable.
Business Impact
Who needs this: Any organization running LLM-powered agents in production — from startups with a single GPT integration to enterprises managing dozens of model endpoints across teams.
The cost of not having it: A single undetected model regression can mean hours of degraded user experience before someone notices, files a ticket, and an engineer manually investigates. For customer-facing AI (support bots, content generation, coding assistants), that's direct revenue and trust loss.
How Otter saves money:
- Reactive: Cuts mean-time-to-recovery from hours (manual detection + manual failover) to seconds (automatic detection + governed re-route)
- Proactive: Catches silent quality drift before users complain — the incident that never happened is the cheapest one
- Audit: Compliance teams get a typed, versioned decision trail instead of Slack threads and post-mortem guesswork
Go-to-market: Open-source core (Apache 2.0) + managed SaaS for teams that want hosted monitoring, dashboard, and alert integrations. Per-model-monitored pricing aligned with usage.
How we built it
- LangGraph for the BPMN topology — parallel gateways, conditional branches, call activities
- Gemini Flash via Google AI Studio API for diagnosis agent reasoning with structured output
- UiPath Maestro as the deployment runtime — packed as
.nupkg, invoked via Orchestrator - 11 Pydantic v2 schemas (
schemas.py) defining every inter-node contract - Fixture mode for deterministic testing — every model-calling node has a fixture branch that bypasses LLM calls
- Claude Code (Claude Agent SDK) as the primary coding agent, with Codex for QA review
Challenges we ran into
- UiPath SDK schema alignment —
uipath.jsonagent registration format changed between SDK versions;bindings.jsonresources array had to match exactly or pack would silently fail - Cloud runtime doesn't Pydantic-marshal —
trigger_intakereceived raw dicts from UiPath Cloud instead of Pydantic objects; added explicit coercion - Version caching — UiPath Cloud caches schema by version number; same-version republish doesn't re-parse, requiring version bumps to escape cache
What we learned
- BPMN topology enforces governance better than prompts — the graph structure itself prevents shortcuts
- Typed contracts between nodes catch integration bugs at deploy time, not at incident time
- Fixture mode isn't just for testing — it's the reliable demo path when LLM providers are flaky
- The separation of "LLM proposes" vs "deterministic rules decide" is what makes the system auditable — conflating the two would undermine the governance story
What's next
- Wire remaining stub nodes to live Gemini calls (diagnosis is live, 6 others use fixtures with typed contracts ready)
- Implement canary threshold logic with real metric comparison
- Add notification agent for Slack/PagerDuty integration
- Multi-tenant support with per-tenant policy rules
- Hook into UiPath Action Center for human-in-the-loop approval on CRITICAL severity incidents

Log in or sign up for Devpost to join the conversation.