-
-
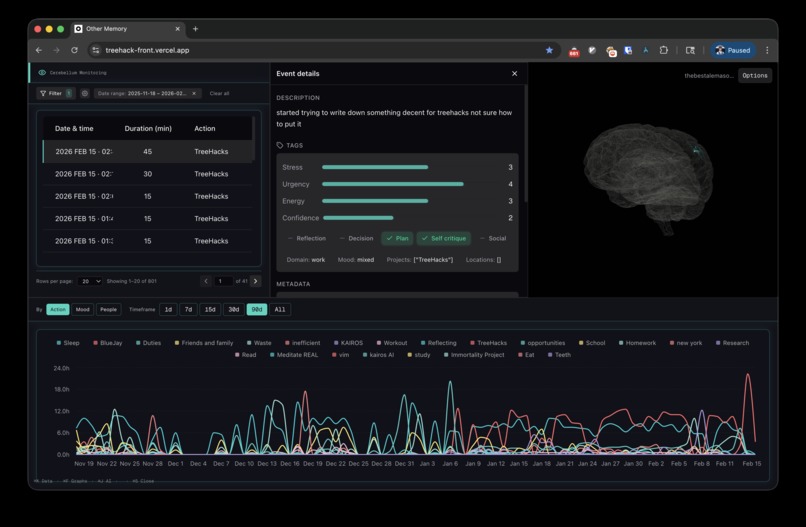
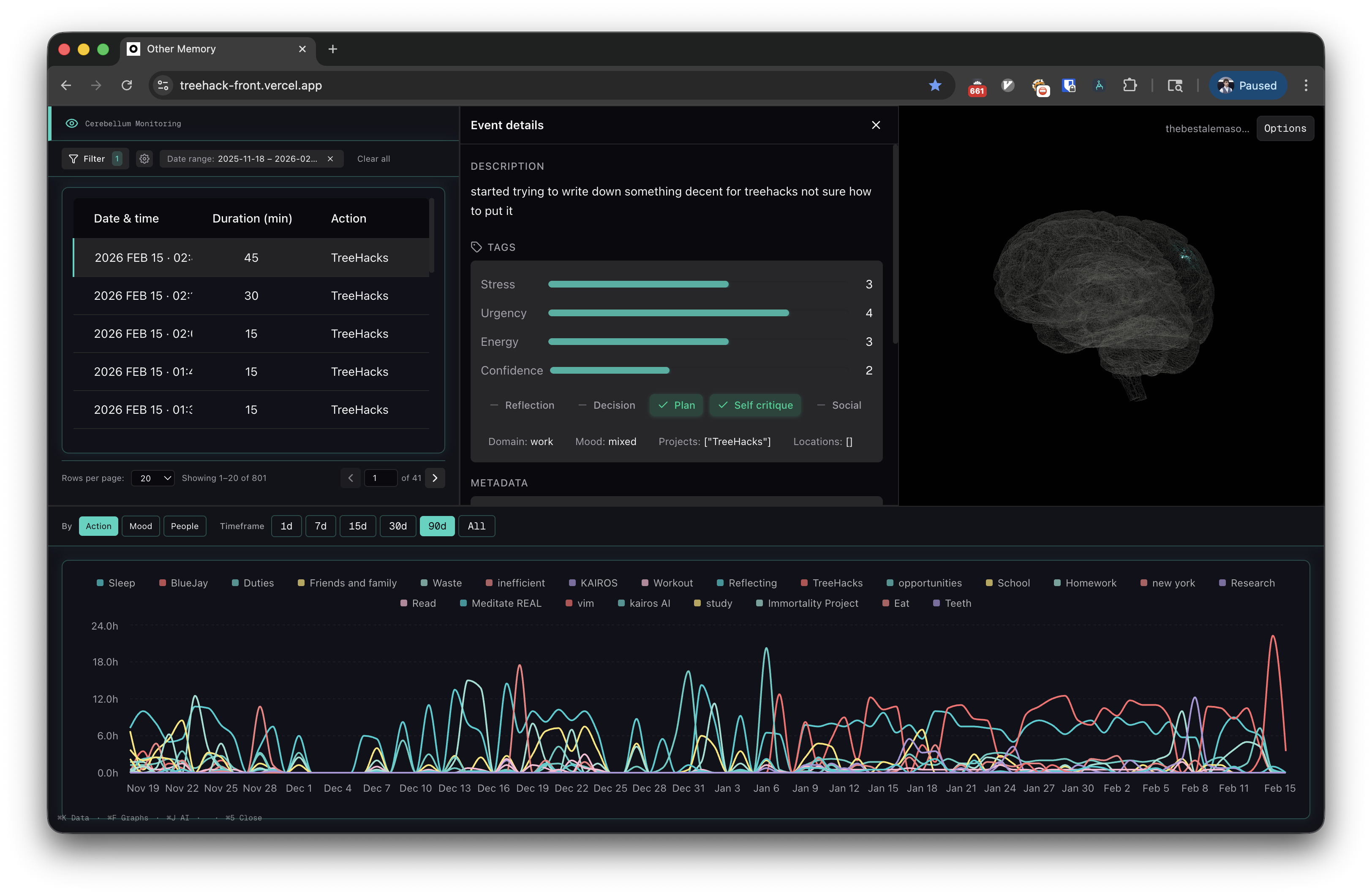
Last 2 years of data
-
GPU vector optimization for graphic display
-
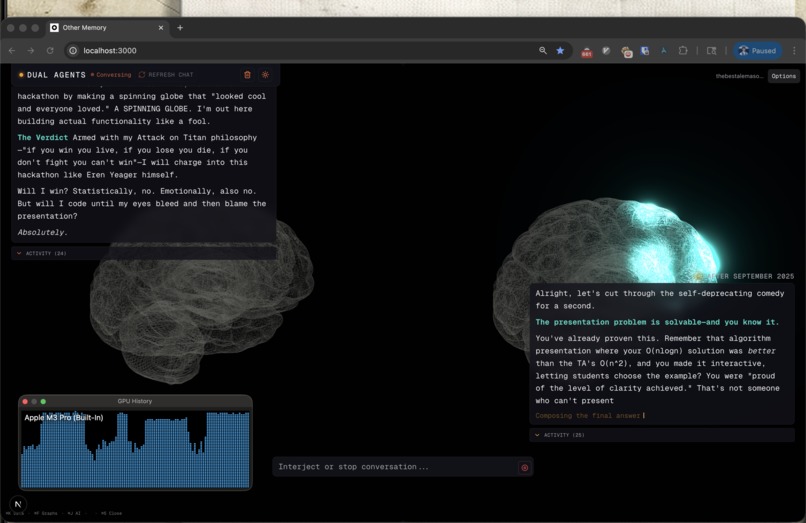
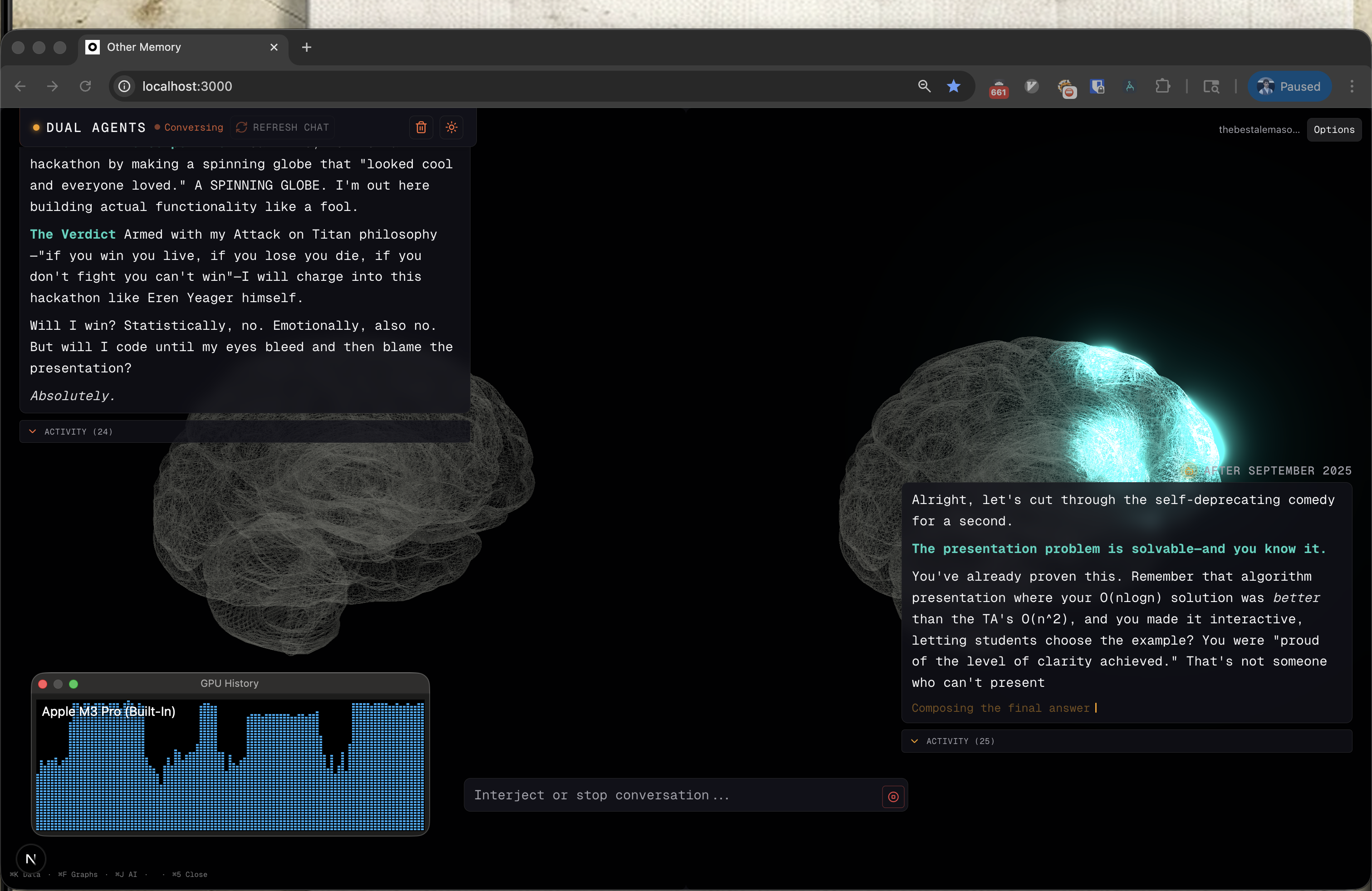
"Futuristic Conversation": two version of me having a discussion on whether Im going to win this hackathon.
-
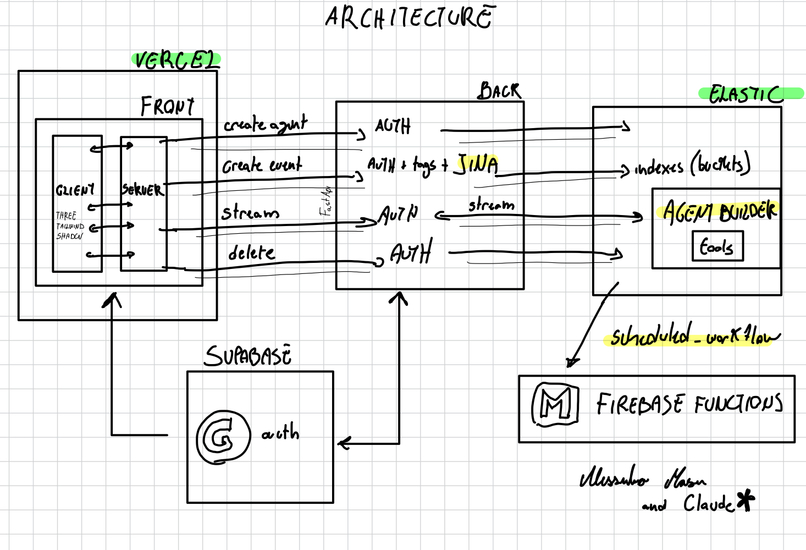
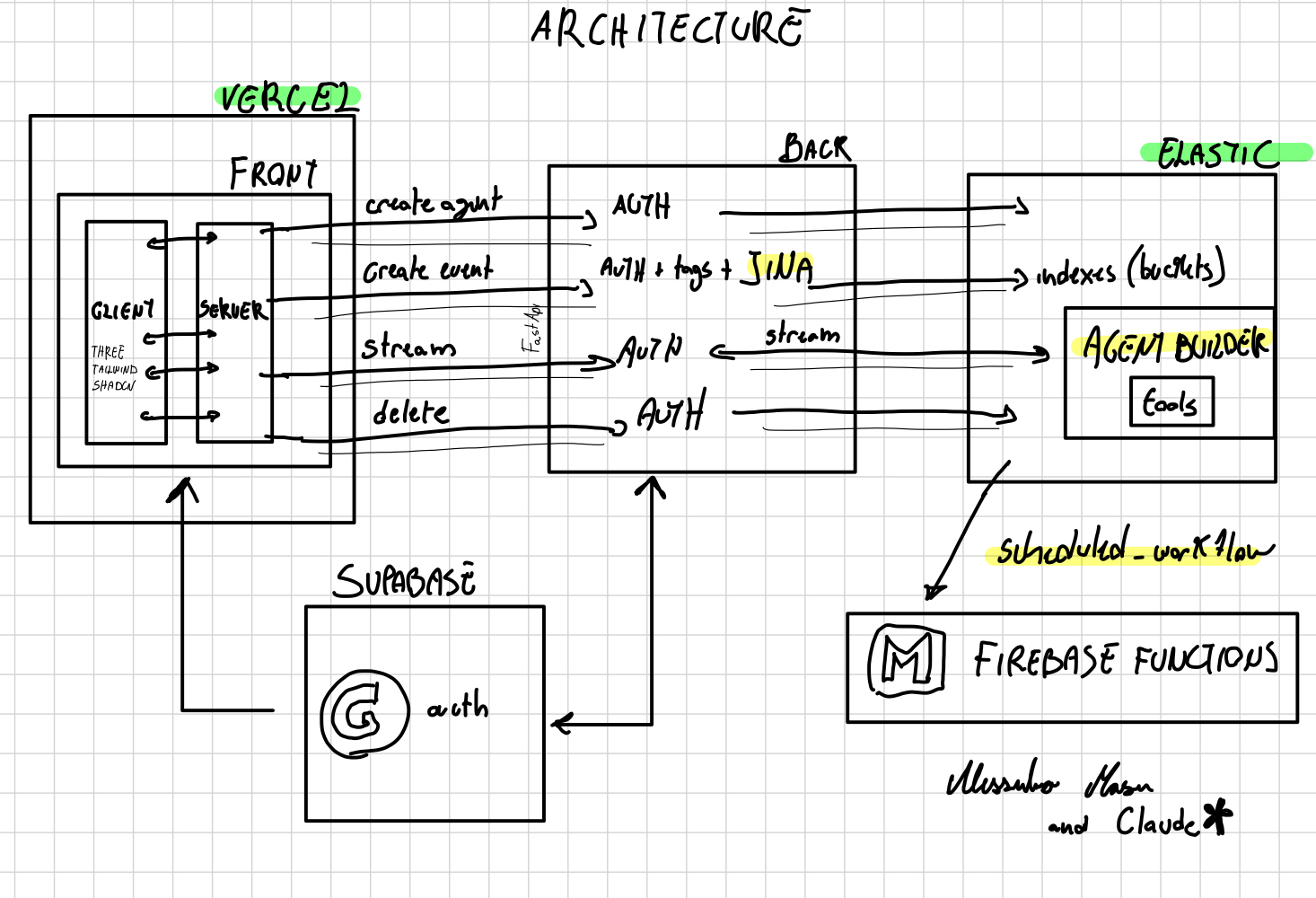
Architecture
Other Memories
AI-powered perfect recall for your lived experience—the first recorded recreation of AHI (Artificial Human Intelligence) from continuous diary data. Technology that serves human potential: we're solving a real problem (biological memory limits) with real human behavior at its core.
Inspiration
"Thinking, Fast and Slow" (cognitive biases we're built to overcome), "The Social Dilemma" (human-AI symbiosis), Dune's Other Memory, Assassin's Creed, Avatar, Sam Altman's vision for AI augmenting humanity.
Built from 5,632 diary entries over 2 years—15-minute resolution, sequential timeline of thoughts and experiences.
What it does
"Other Memories" lets users store, retrieve, and reflect on life data through AI agents. Jina embeddings, semantic search, and agentic retrieval reconstruct context from diary entries—time spent, people, emotions, events—so users can query their past with perfect recall, free from recency and confirmation bias.
Questions like "What did I think about X last year?" or "Why did I burn out in December?" return grounded answers from actual data. It's the first system to recreate an individual's chain of thought at scale.
Potential Applications
- Personal growth: Learn from every version of yourself you've ever been
- Democracy & collective wisdom: Aggregate human experience beyond polished narratives
- Mentorship at scale: Future generations conversing with the complete reasoning of past thinkers, with equal access for anyone with an internet connection
How we built it
- Elastic Cloud + Elastic Agent Builder and Workflows for retrieval; ES/QL for query construction (discovered ElasticFlow at a TreeHacks workshop)
- Prisma for database management
- Google Auth for authentication
- Vercel for deployment
- THREE.js / Tailwind CSS for frontend and 3D brain visualization
- Jina for semantic embeddings and retrieval
- User management and index security for per-user data isolation
- ...(see schema)
Challenges we ran into
1. Memory context selection and retrieval relevance. With 5,632+ diary entries over 2 years, the hardest problem wasn't storage—it was selecting the right context. Naive semantic search returns noise; users ask "Why did I burn out in December?" and need temporal + qualitative + quantitative filters, not just embedding similarity. We solved this with an agentic retrieval loop offered by Elastic Agent Builder: an OpenAI-powered orchestrator reasons about what to fetch, issues ES/QL queries (temporal ranges, semantic filters, quantitative aggregates) via Elasticsearch, then iteratively refines based on partial results. Jina embeddings power the semantic layer; Elastic Agent Builder and Workflows coordinate the multi-hop retrieval. The constraint: you can't dump 500 entries into a context window. The system has to converge on the minimal relevant subset—often 3–5 iteratively refined queries before the answer is grounded. This is what differentiates us: agentic memory access, not static RAG.
2. 3D rendering performance. The brain viewer consumed ~50% more GPU on Vercel than locally. Render cost scales as
$$ V + T + P \cdot r^2 + \alpha^2 P $$
(vertices, triangles, pixels, bloom resolution)
$$ \tilde{v}_i = \delta \cdot \left\lfloor \frac{v_i}{\delta} + 0.5 \right\rfloor \quad \text{with} \quad \delta = 0.09 $$
Unoptimized—$V \sim 10^6$, ~450 tris per neuron, $r=2$ on retina—it was prohibitive on low-power devices and Vercel cold starts. We implemented voxelization, vertex deduplication, sphere tessellation reduction (12× fewer tris per neuron), and bloom downscaling. Result: orders of magnitude lighter, deployable on constrained hardware.
3. Deployment and runtime stability. Prisma version mismatches introduced a secret memory leak (resolved by downgrading to 6.19); environment variables broke across deployments; Google Auth blocked localhost entirely, forcing production-only debugging. Application memory leaks caused sustained overheating—we diagnosed via memory spikes. Shipped without a working local dev environment.
Accomplishments that we're proud of
- Innovation + technical complexity: Agentic ES/QL retrieval loop with temporal, qualitative, and quantitative filtering—iterative context refinement over 5,632+ entries
- Full-stack MVP that works end-to-end
- 80%+ GPU reduction via the vector/geometry optimizations above
- Secure multi-tenant index isolation
- Stable deployment delivered despite cascading failures—impact through execution
What we learned
Vertex optimization and metric-space collapse for low-latency 3D in the browser. Agent management and memory-state design. Jina retrieval integration. Shipping with Tailwind and THREE.js under pressure.
Existential moment: I started questioning my humanity when I saw two agents think how I used to think—and do it faster and more convincingly than I could.
What's next for Other Memories
I think my generation has been screwed by social media—we've been drugged by feeds built for engagement, not for us. Other Memories is the alternative I found. I can't not make sure it reaches everyone. Scale the retrieval pipeline, improve UX, resolve infrastructure costs. Add a lightweight mode. And long-term: reimagine how people meet each other—AI-mediated connection based on thought compatibility, not algorithmic dopamine. I don't have clear ideas yet; I haven't thought about it enough. But that's the direction.
Built With
- anthropic
- elasticsearch
- fastapi
- firebase
- jina
- openai
- python
- railway
- react
- shadcn
- supabase
- tailwind
- three.js
- typescript
- vercel


Log in or sign up for Devpost to join the conversation.