-
-
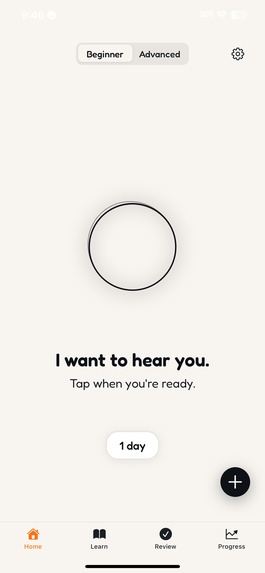
Tap the orb to start a real-time voice conversation with Orphi, your AI language buddy powered by Gemini Live
-
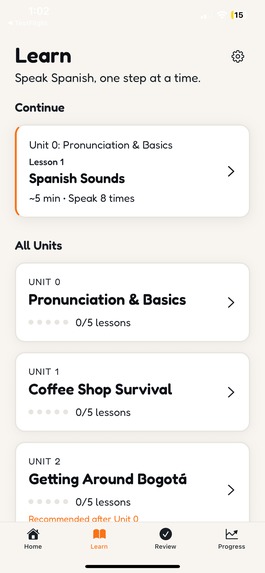
Structured curriculum with voice-first lessons — every unit is designed around real-world scenarios like ordering coffee
-

Hold to speak and Gemini evaluates your pronunciation in real time — learn words like "amigo" by actually saying them
-
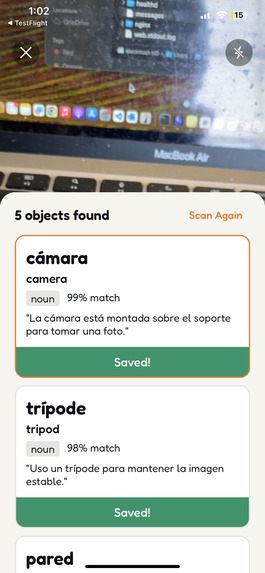
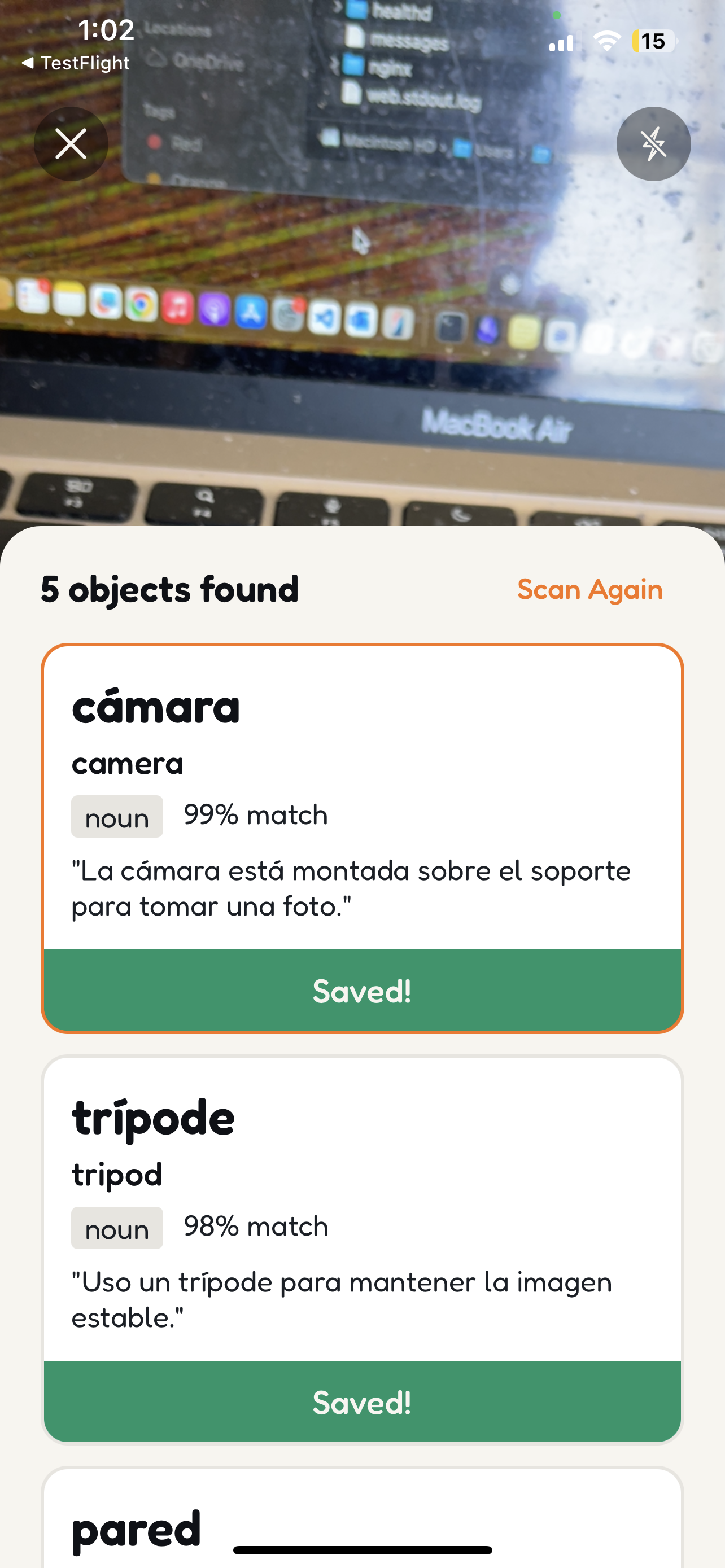
Save scanned vocabulary to your personal collection — each word gets a generated illustration and spaced repetition
-
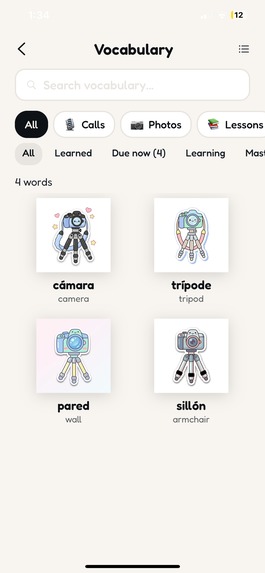
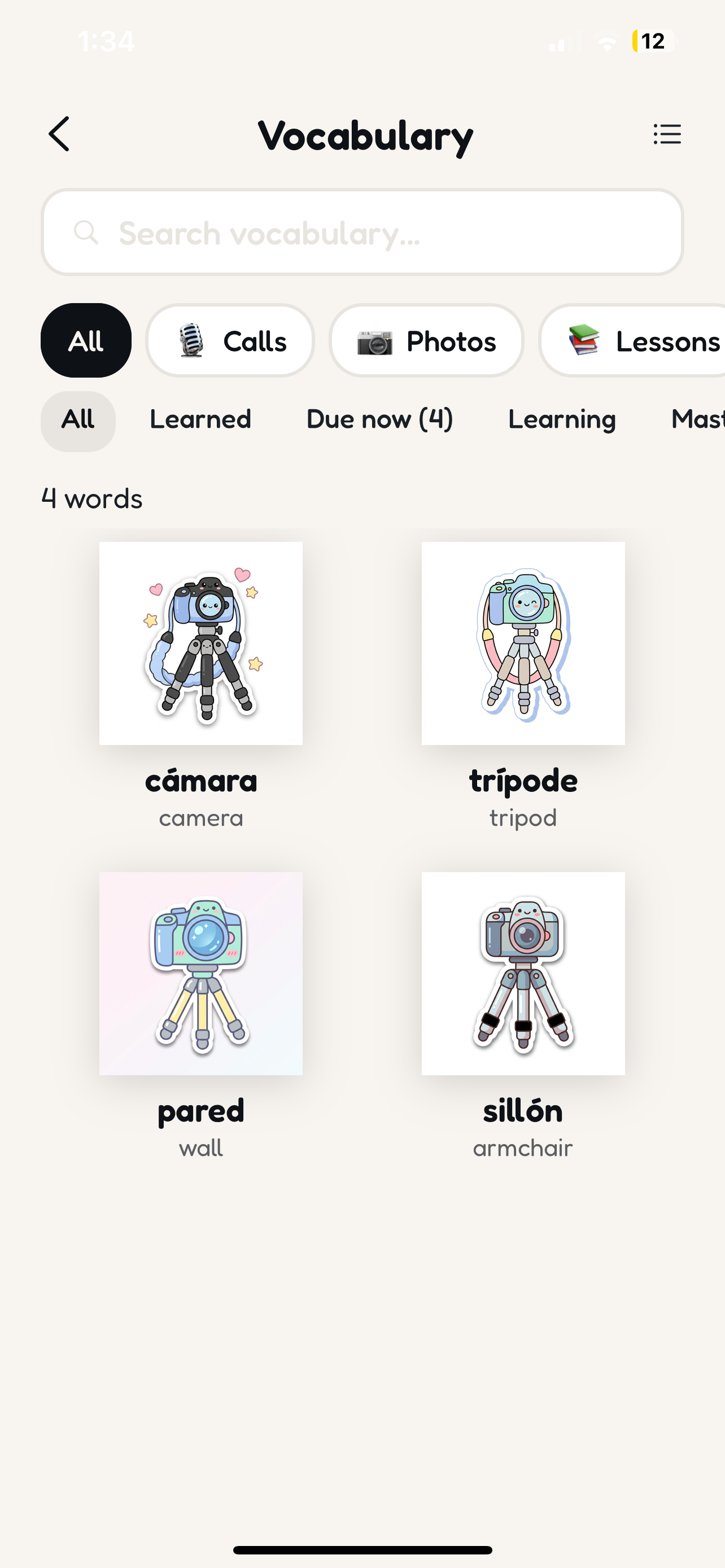
Your visual vocabulary bank — words collected from camera scans, voice calls, and lessons
-
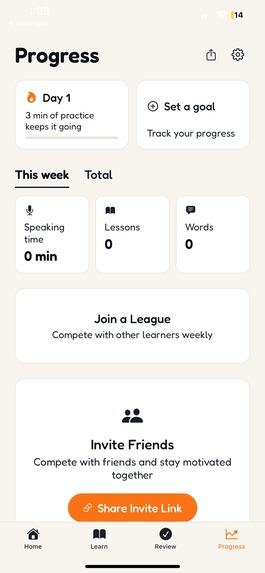
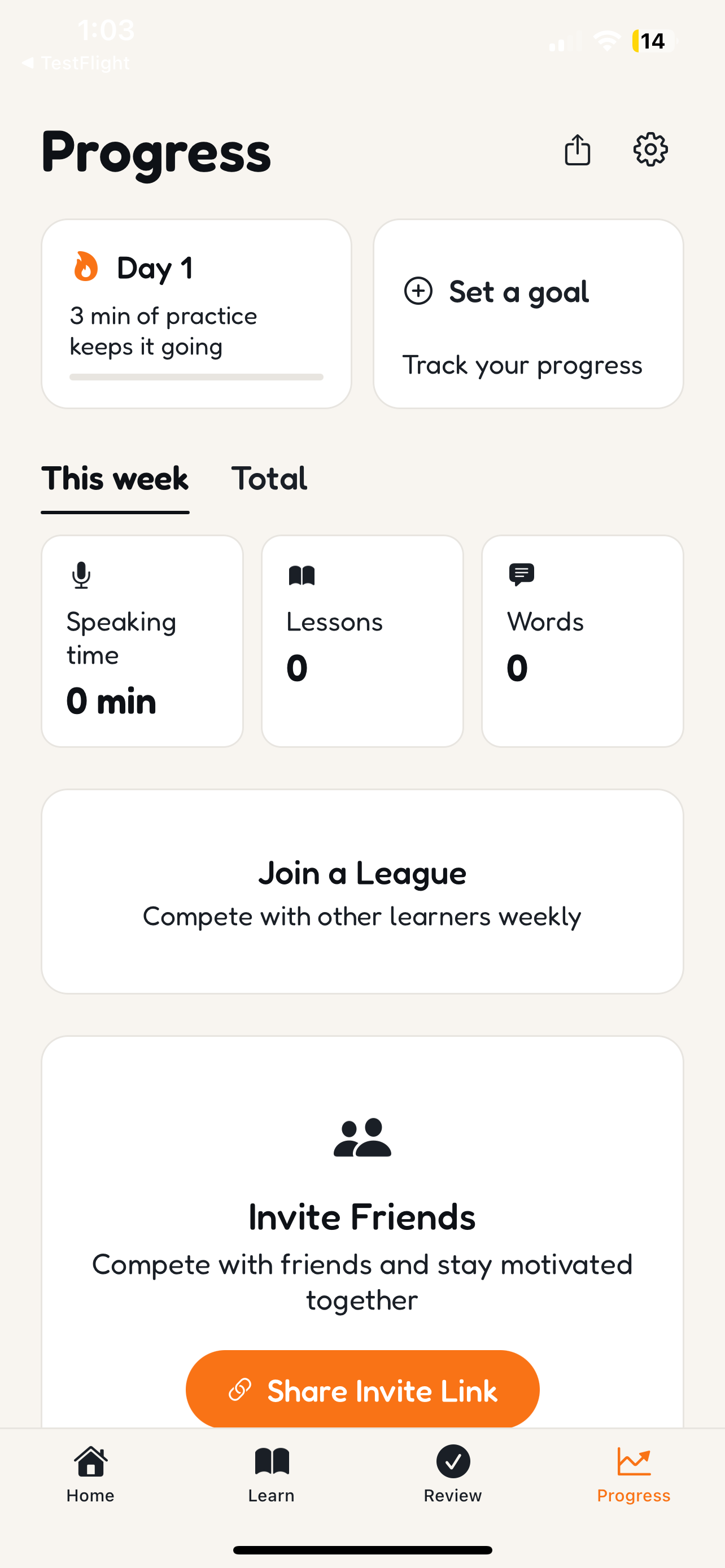
Track streaks, speaking time, and vocabulary growth — compete with friends through leagues and shared invite links
-
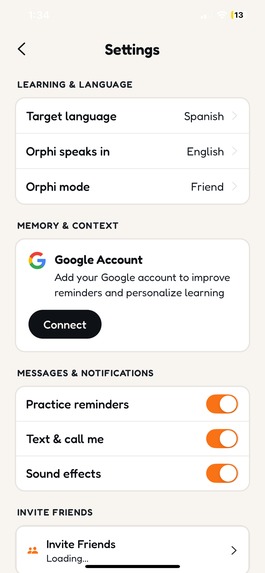
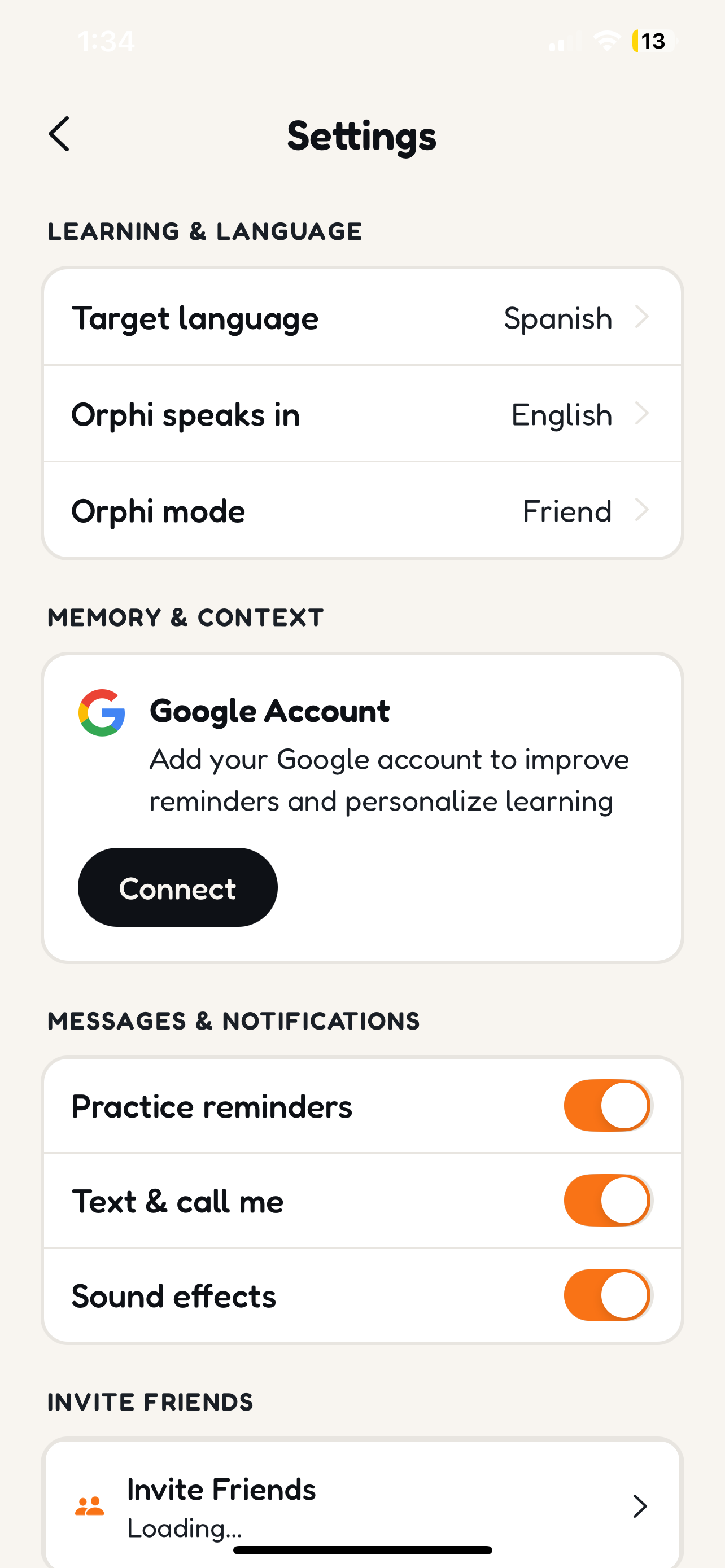
Customize your experience: switch languages, connect Google Calendar, toggle between Friend and Tutor correction modes
-

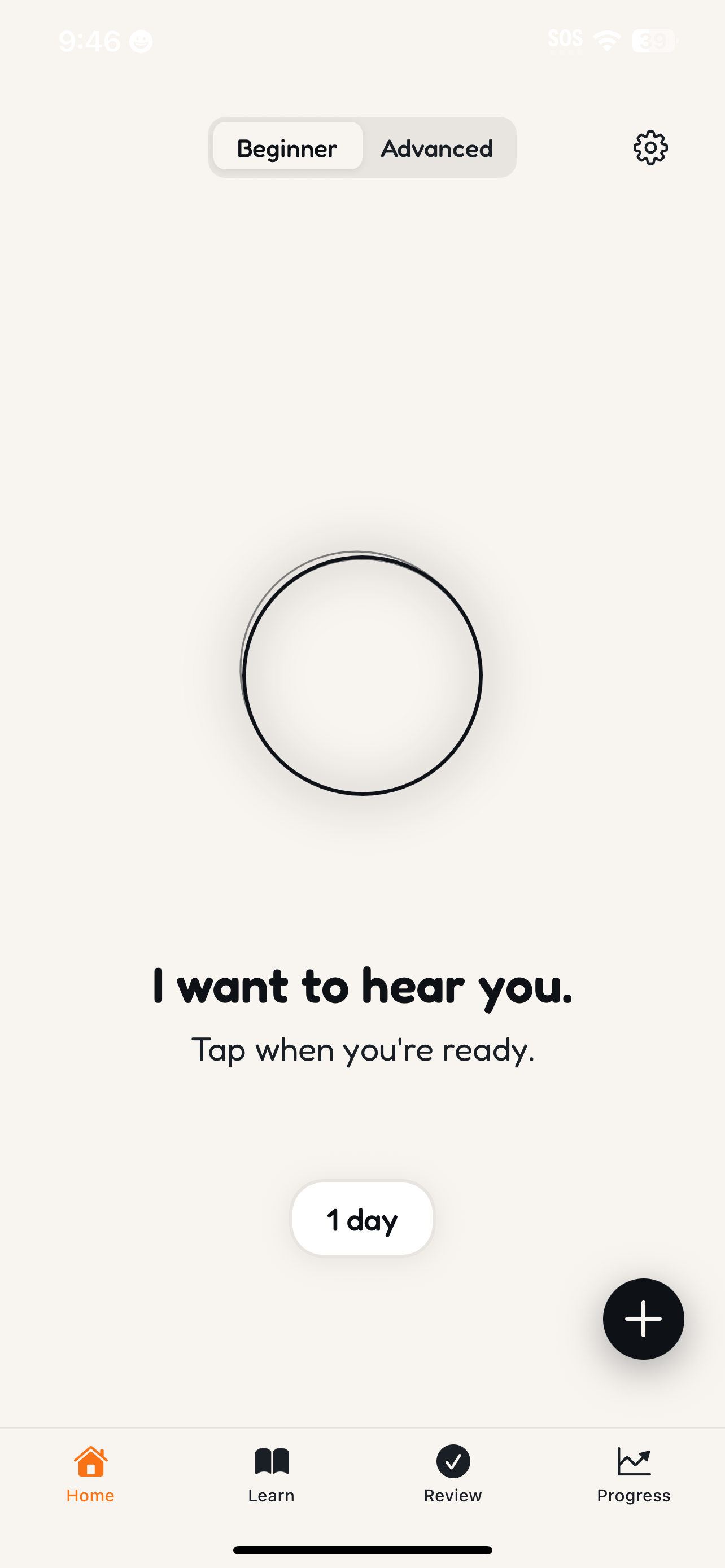
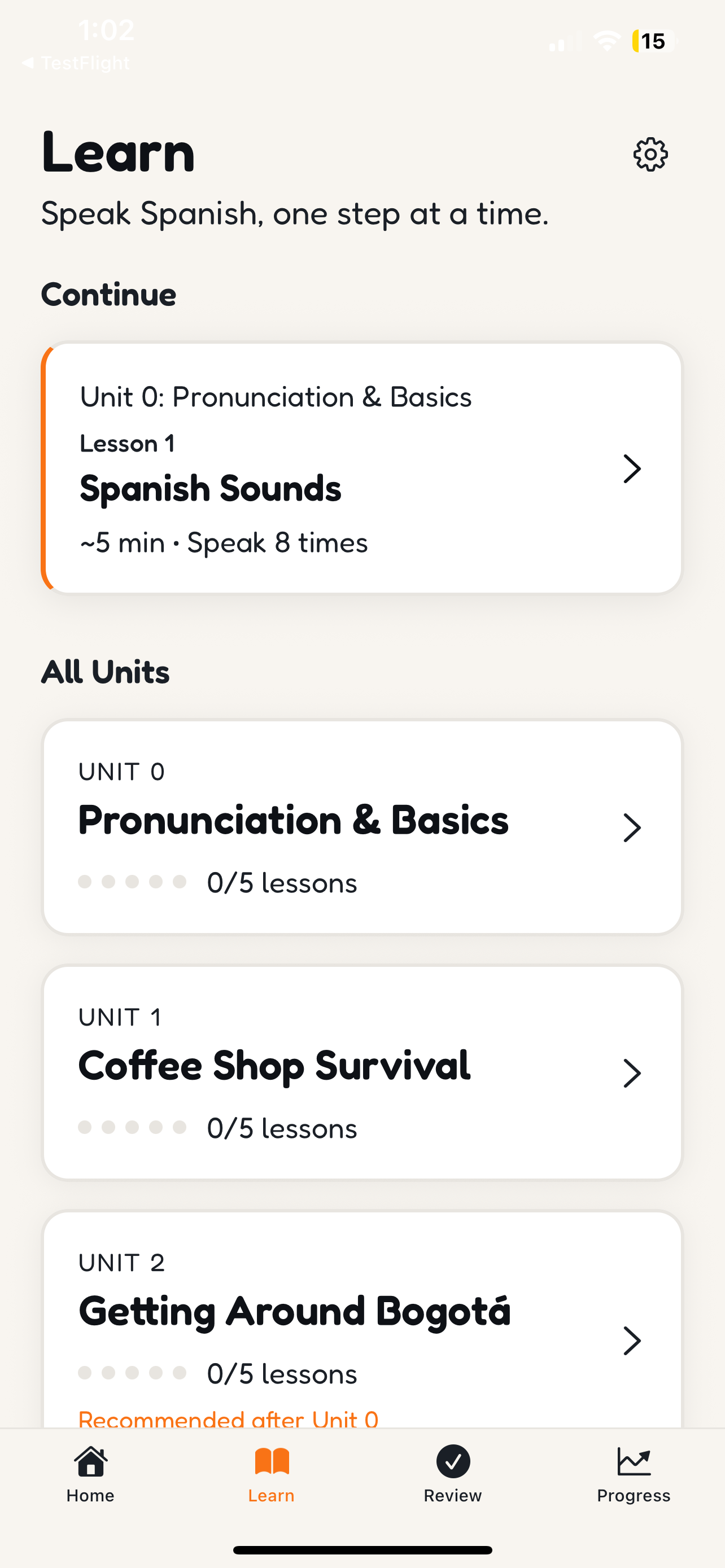


Inspiration
2 years ago, I started studying Chinese at Dartmouth. Spent hours drilling characters, perfecting tones, memorizing grammar patterns in my dorm room but when I tried to actually speak I froze. And I am sure you also know this friend that has a 2 year duoliguo streak but doesn't speak the language. That was me. When I tried to speak Chinese with friends, I realized that I just couldn't and that there was a fundamental difference between grammar and actually speaking.
I wanted to fix that and practice how to "speak" the language I was learning. However, there was no one to practice with. Classmates were busy. Speaking with Native Chinese speakers felt intimidating. Every language app on the market made me tap flashcards and read dialogues. Not one of them let me actually talk.
Then I studied abroad in Beijing. Everything changed — not because the grammar suddenly clicked, but because I finally had people to talk to every single day. Ordering street food. Making friends at basketball courts. Getting lost and asking for directions. My speaking exploded in weeks.
Even while studying Chinese at Dartmouth, I kept thinking: what if I had an AI friend to practice with? Someone always available, endlessly patient, who adapts to my level and never judges? When I came back from Beijing, those thoughts got louder. I didn't want to lose my Chinese. I didn't want to lose that immersion feel, that practice space I'd finally found.
Then voice AI reached a point where it was actually possible. And Gemini broke all expectations in making it happen. Real-time voice with native audio processing, multimodal intelligence, the ability to switch languages mid-conversation — and affordable enough to actually scale.
And that's how Orphi was born.
## What it does
Orphi is an AI language learning companion that feels like texting and calling a friend — not studying.
Voice calls powered by Gemini Live — talk to Orphi like you'd call a friend. Real-time voice conversations with under 100ms latency. Orphi switches between languages mid-sentence because Gemini's native audio model handles multilingual natively.
Photo vocabulary — see something cool? Snap a photo. Gemini 3 Flash vision identifies objects and generates vocabulary in your target language with pronunciation guides and example sentences. Then Gemini 3 Pro Image transforms it into a kawaii sticker for your flashcard deck.
Text conversations that work on ANY phone — text Orphi via the app or just SMS. No smartphone required. Orphi corrects your mistakes gently, embedded in natural conversation. No red "WRONG" banners — just a friend who helps you improve.
Long-term memory — Orphi remembers you. Powered by Supermemory's knowledge graph wrapped around Gemini 3 Flash, Orphi knows your study abroad plans, your cooking hobby, your struggle with French subjunctive — and brings it up naturally.
Smart learning system — FSRS spaced repetition for vocabulary. Streak system. Boss fights (roleplay scenarios). echoScore tracks your progress from beginner to fluent.
5 languages supported: Mandarin, Spanish, French, Italian, English — and growing.
## How we built it
Backend: Node.js + Express + TypeScript with Mastra.ai as our agent framework for tool orchestration. The Orphi agent uses Gemini 3 Flash Preview as its brain — deciding when to invoke tools like memory search, vocabulary tracking, corrections, and web search.
Voice: LiveKit Agents + Gemini 2.5 Flash Native Audio for real-time voice conversations. The voice agent pre-fetches user context (memory, learning state) before the call starts so there's zero delay. Post-call analysis extracts learning insights from transcripts.
Memory: Supermemory.ai provides a knowledge graph that wraps around Gemini 3 Flash. Conversations are stored semantically, so Orphi retrieves relevant memories naturally — not through keyword matching.
Photo pipeline: User snaps a photo → Gemini 3 Flash Preview (vision) detects objects and generates vocabulary → Gemini 3 Pro Image Preview transforms the photo into a kawaii sticker flashcard. Users get vocabulary instantly, styled image appears seconds later.
Database: Convex for real-time data (users, vocabulary with FSRS spaced repetition, streaks). Supermemory for conversations and learning context.
Mobile: Expo React Native with LiveKit React Native SDK for voice. Clerk for authentication.
SMS: Linq for iMessage/RCS/SMS with auto-fallback — making Orphi accessible on any phone.
4 Gemini models working together:
- Gemini 3 Flash Preview — conversations, vision, extraction, transcription, curriculum
- Gemini 3 Pro Image Preview — kawaii sticker image generation
- Gemini 2.5 Flash Native Audio — real-time voice (no Gemini 3 alternative exists yet)
- Gemini 2.5 Flash TTS — multilingual text-to-speech (no Gemini 3 alternative exists yet)
## Challenges we ran into
Real-time voice latency — We optimized by using Gemini Live's native audio processing (no STT/TTS pipeline overhead), and running LiveKit workers in the same AWS region. Result: under 100ms perceived latency.
SMS character limits — LLMs generate long responses. We built a message chunker that splits at sentence boundaries, targets 120-char chunks, and maintains conversational flow across multiple texts.
Long-term memory across sessions — Gemini's context window is large, but we needed memory that persists across conversations. We wrapped Gemini 3 Flash with Supermemory's knowledge graph — semantic search retrieves relevant past conversations, and the agent decides which memories to include without exceeding context limits.
Multimodal coordination — photo vocabulary involves multiple models: vision for object detection, then image generation for styling, then text for vocabulary. We handled the async processing with a cron job pattern using Convex so users get vocabulary instantly while the styled image appears 10-30 seconds later.
Language-agnostic design — supporting 5 languages with different scripts (Latin, Hanzi, etc.). Gemini 3 Flash handles multilingual naturally, but pronunciation guides (pinyin for Chinese, IPA for others) and target language ratios needed to adapt per language and per user level.
## Accomplishments that we're proud of ** IT'S LIVE ON TESTFLIGHT!!!**
Orphi genuinely feels like talking to a friend, not a chatbot. The combination of Gemini 3 Flash's conversational intelligence with Supermemory's long-term knowledge graph means Orphi remembers your life, adapts to your level, and makes learning personal — not generic.
Under 100ms voice latency. Real-time voice conversations powered by Gemini Live that feel like talking to a native speaker. Users can interrupt mid-sentence and Orphi adapts naturally. This is what makes immersive practice possible.
Works on any phone via SMS. Not everyone has a smartphone. Orphi's intelligence works through text messages — same Gemini-powered conversations, no app store required.
4 Gemini models orchestrated seamlessly. Gemini 3 Flash for intelligence, Gemini 3 Pro Image for creativity, Gemini 2.5 Native Audio for voice, Gemini 2.5 Flash TTS for speech — all coordinated through Mastra's agent framework to create one fluid experience.
Production-ready, not a hackathon demo. Real database, real auth, real infrastructure. LiveKit for voice, Convex for real-time data, Clerk for authentication, FSRS for spaced repetition. This is a real product, not a proof of concept.
Photo-to-sticker vocabulary pipeline. Snap a photo of anything → get instant vocabulary → see it transform into a kawaii sticker flashcard. Learning from the real world, not a textbook.
## What we learned
Gemini 3 Flash makes conversations feel real, not robotic. Switching to Gemini 3 Flash Preview cut response times significantly. For a conversational app, that's the difference between feeling like a chatbot and feeling like a real person. When Orphi responds in under a second with contextual, natural language — users forget they're talking to AI.
Gemini Live solved the "speech is ignored" problem. Before Gemini Live, building voice AI meant stitching together speech-to-text, LLM processing, and text-to-speech. The latency killed any sense of natural conversation. Gemini's native audio model processes voice directly with under 100ms response time — users can interrupt, Orphi responds naturally. This is what enables immersive learning.
Memory + Gemini = a friend who knows you. We wrapped Gemini 3 with Supermemory's knowledge graph. Orphi remembers your study abroad plans, your last grammar mistake, your interest in cooking — and brings it up naturally weeks later. This isn't just an LLM responding to prompts. It's an AI friend who knows you.
Voice onboarding replaced boring forms. Traditional apps ask you to fill out surveys. We built a 3-minute natural conversation powered by Gemini Live. Orphi asks questions, listens, adapts — then Gemini 3 Flash extracts a structured profile from the transcript. Way more engaging, way richer data.
SMS accessibility matters more than we thought. Everyone expected a mobile app. But building SMS support means billions of people who have phones but not smartphones can still learn. Gemini works the same whether you're texting from an iPhone or a basic phone.
## What's next for Orphi: Your Personal language tutor
More languages — the architecture is language-agnostic. Adding a new language is configuration, not code. We're targeting 15+ languages by end of year.
Android release — currently iOS only via TestFlight. Android is next.
Group practice rooms — voice rooms where multiple learners practice together with Orphi moderating, powered by LiveKit's multi-participant support.
Language certification prep — DELF, HSK, JLPT practice modes with Gemini generating exam-style questions tailored to your level.
Deeper Gemini 3 integration — as Gemini 3 Live audio and TTS models become available, we'll migrate our remaining 2.5 models to fully run on Gemini 3 across every layer.
Built With
- amazon-web-services
- clerk
- convex
- expo.dev
- express.js
- gemini-2.5-flash-native-audio
- gemini-2.5-flash-tts
- gemini-3-flash-preview
- gemini-3-pro-image-preview
- google-ai-sdk
- linq
- livekit
- mastra.ai
- node.js
- openrouter
- python
- react-native
- supermemory.ai
- twilio
- typescript

Log in or sign up for Devpost to join the conversation.