-
-

Orca Composer Agent
-
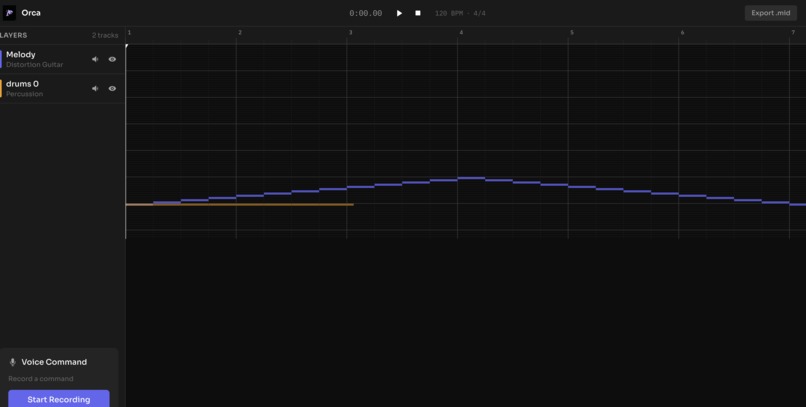
Orca Composer Agent MIDI Editor View
-

help

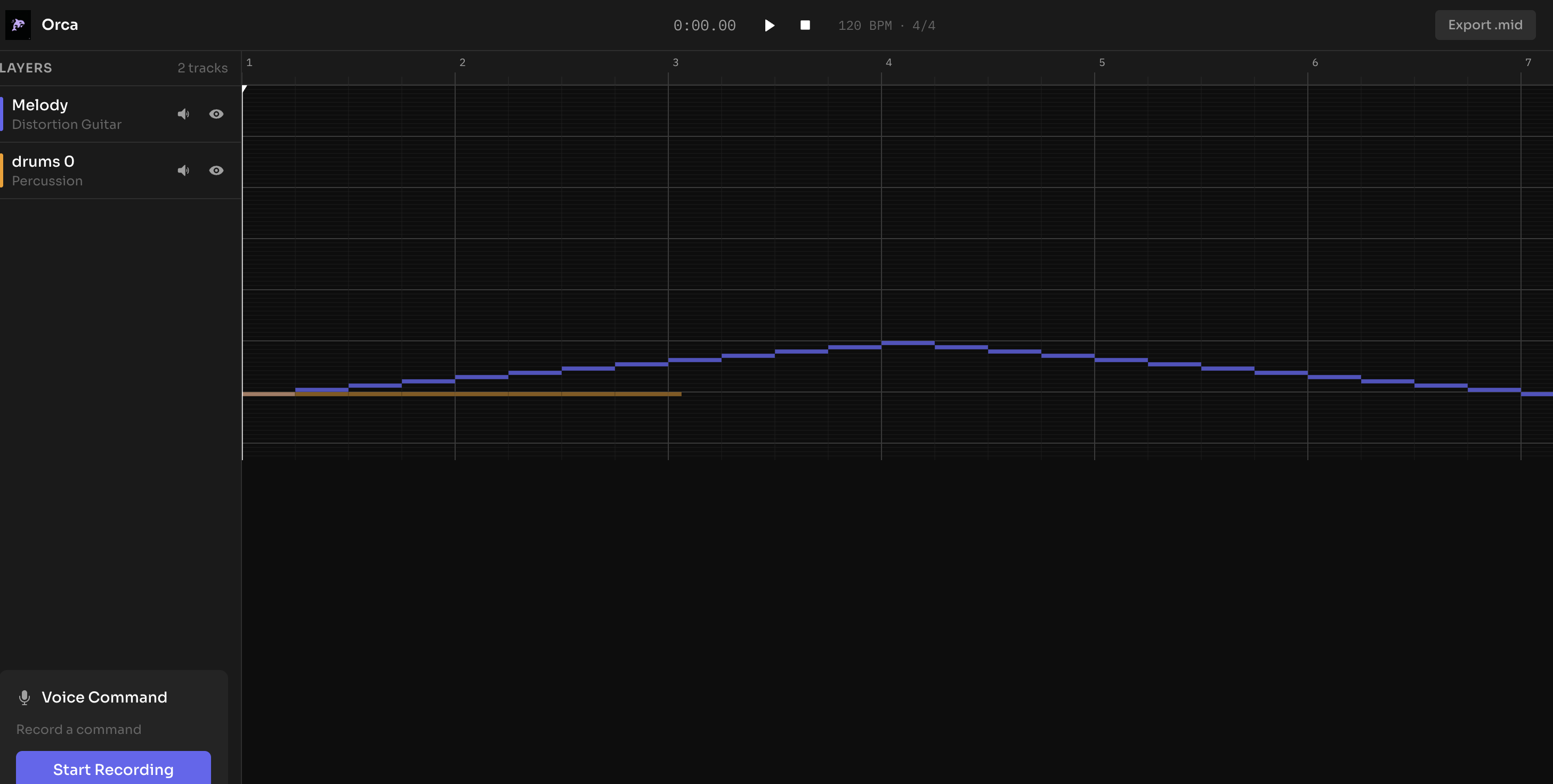

Behind the Scenes of Orca
Inspiration
We're living in the golden age of creation. AI tools are unlocking creative potential like never before, but there's this massive gap: millions of enthusiast musicians and producers have incredible musical ideas stuck in their heads. You know that melody you hum in the shower? That beat you tap on your desk? Most people have no way to actually turn those into real music.
We wanted to fix that. Our goal was simple: give musical enthusiasts the power to bring those fleeting melodies to life. Build something that keeps the artist in control while making the whole experience feel seamless and natural.
What It Does
Orca takes your voice and turns it into actual music. You can hum, sing, or beatbox your ideas, throw in some instructions like "make this a piano" or "add a guitar backtrack" while you're recording, and Orca system handles the rest.
- Record your musical ideas using just your voice (no instruments needed)
- Give instructions naturally, all in one recording
- Get back an adjustable rhythm that actually sounds like what you imagined
Orca figures out which parts are you humming versus talking, transcribes your instructions, and utilizes AI to orchestrate everything together based on what you asked for.
How We Built It
Tech Stack:
- Customer ML model for audio segmentation and classification
- Multi-stage modular audio processing pipeline, capable of handling multimodal audio
- ElevenLabs API for speech-to-text transcription
- Custom audio to MIDI processor and score builder
- Agentic rhythm editor powered by Google Gemini
The Pipeline: We built this thing in stages that the audio flows through:
- Segmentation & Classification - figure out what's speech, humming, singing, or beatboxing
- Transcription - pull out the actual instructions using ElevenLabs
- MIDI conversion - turn the musical parts into MIDI files
- Rhythm editor - Gemini chooses the corresponding tools to use based on your instructions
- Instrument assignment - apply the instruments you asked for to the MIDI tracks
- Score building - put it all together into a user-friendly visual composition
Challenges We Faced
Multimodal Audio to MIDI Was a Disaster
Turns out we suck at singing and humming. The MIDI files from our voices were completely unusable at first. Super uneven timing, random staccato notes everywhere, just a mess.
We had to build a whole preprocessing pipeline to fix it. Quantization algorithms to smooth out the timing, normalize note durations, clean up the pitch detection. It was way more work than we thought.
Real-world audio is messy. What works in a lab falls apart when you're dealing with less-than-ideal conditions.
Backtrack Generation Had Zero Control
We tried using MusicLang's predict function for automatic backtrack generation, and it sounded terrible. The autogenerated stuff clashed with the user melodies and we had no way to fix it.
We ended up scrapping that approach entirely and building our own MIDI merging system that actually respects user instructions. Way more complicated work but the results are actually usable.
Sometimes the faster approach isn't better, its just bad but faster.
Gemini Can't Actually Edit Audio (And It Lies About It)
This was probably our biggest headache. We originally tried to have Gemini directly manipulate audio files based on instructions. Spoiler alert: LLMs can't edit audio. Gemini would just hallucinate that it did things, claim success, and give us back nothing useful.
The fix was switching to an agentic architecture. Instead of prompting Gemini for outputs, we gave it a set of tools it could use:
- Audio segmentation tool
- MIDI parser tool
- Instrument assignment tool
- File reference tool
The instructions are parsed, audio segment references extracted, and the agent chooses its tools and handles the rest, allowing us to control its actions in a more reliable and productive manner.
Parsing Instructions Mixed With Musical Input
Users don't want to record instructions separately. They want to hum a melody and say "make this guitar" in the same take. How can a machine tell the difference between humming and speech?
To solve this, we built a custom audio segmentation model to classify different audio types. Speech goes to ElevenLabs for transcription, musical parts go to MIDI conversion. Then the agent uses context to match instructions to the correct audio files.
Multimodal input is hard. You can't just throw raw audio at an API and cross your fingers.
Our Core Features Were Dealbreakers
This is what made the project way harder than most hackathon stuff. We couldn't cut features. Without proper audio segmentation, the product didn't work. Without agentic tool selection, instructions couldn't be executed. Without MIDI preprocessing, everything sounded horrible.
There was no obvious solution around these problems. We had to address them properly or the whole thing risked falling apart.
Some features aren't optional when you're building something actually new. You can't always prototype incrementally when the core functionality is this interdependent.
What We Learned
Agentic AI beats pure generation for structured tasks. Constraining LLMs with actual tools eliminates most hallucinations and gives you reliable outputs.
Real-world audio is chaos. Preprocessing ended up being like 80% of the work when dealing with rough vocal input.
Good UX means solving hard backend problems. Making something feel "seamless" usually means you're doing incredibly complex stuff behind the scenes.
Multimodal systems are integration nightmares. Every single component (segmentation, transcription, MIDI processing, orchestration) had to work perfectly together or the whole chain breaks.
Sometimes you can't take shortcuts. For truly innovative products, certain features are non-negotiable, even in a hackathon timeline.
What's Next
We're democratizing creativity for the golden age of music. This is just the start.
Next steps:
- Better MIDI quantization for rhythm detection
- Real-time collaborative editing
- Expanded instrument library and mixing capabilities
- Community marketplace for user compositions
Music creation should be accessible to everyone with an idea, regardless of skill level. We're making that happen.




Log in or sign up for Devpost to join the conversation.