

Inspiration
I’ve heard from many students on campus that parking has become a constant source of stress, with high permit prices and strict enforcement making it easy to get ticketed.
For students already juggling classes, work, and other responsibilities, worrying about where to park or whether they might get fined adds unnecessary pressure.
Hearing these concerns made me want to create something that could help ease that burden - an approach that makes parking a little less stressful and a little more manageable for students.
What it does
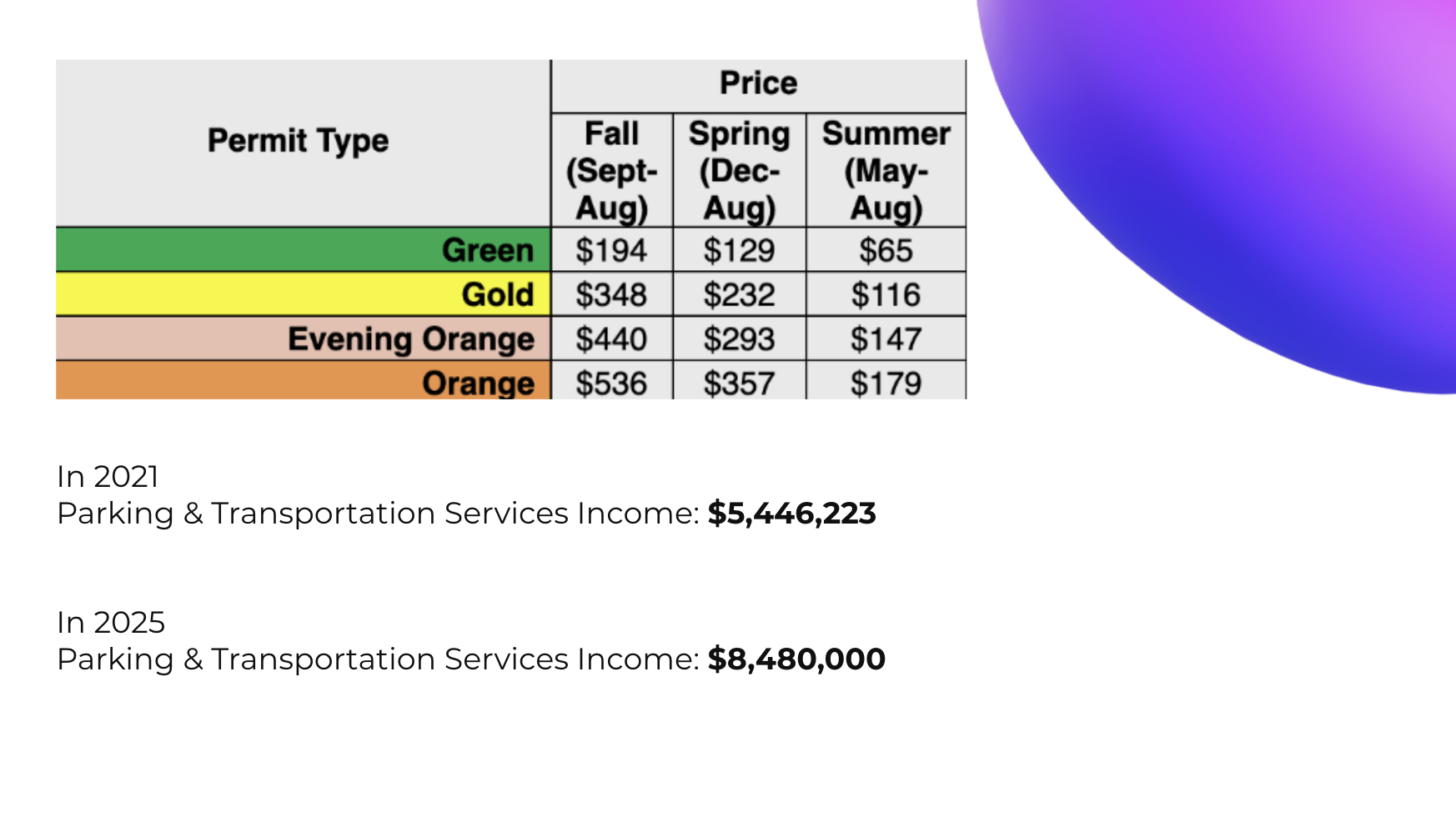
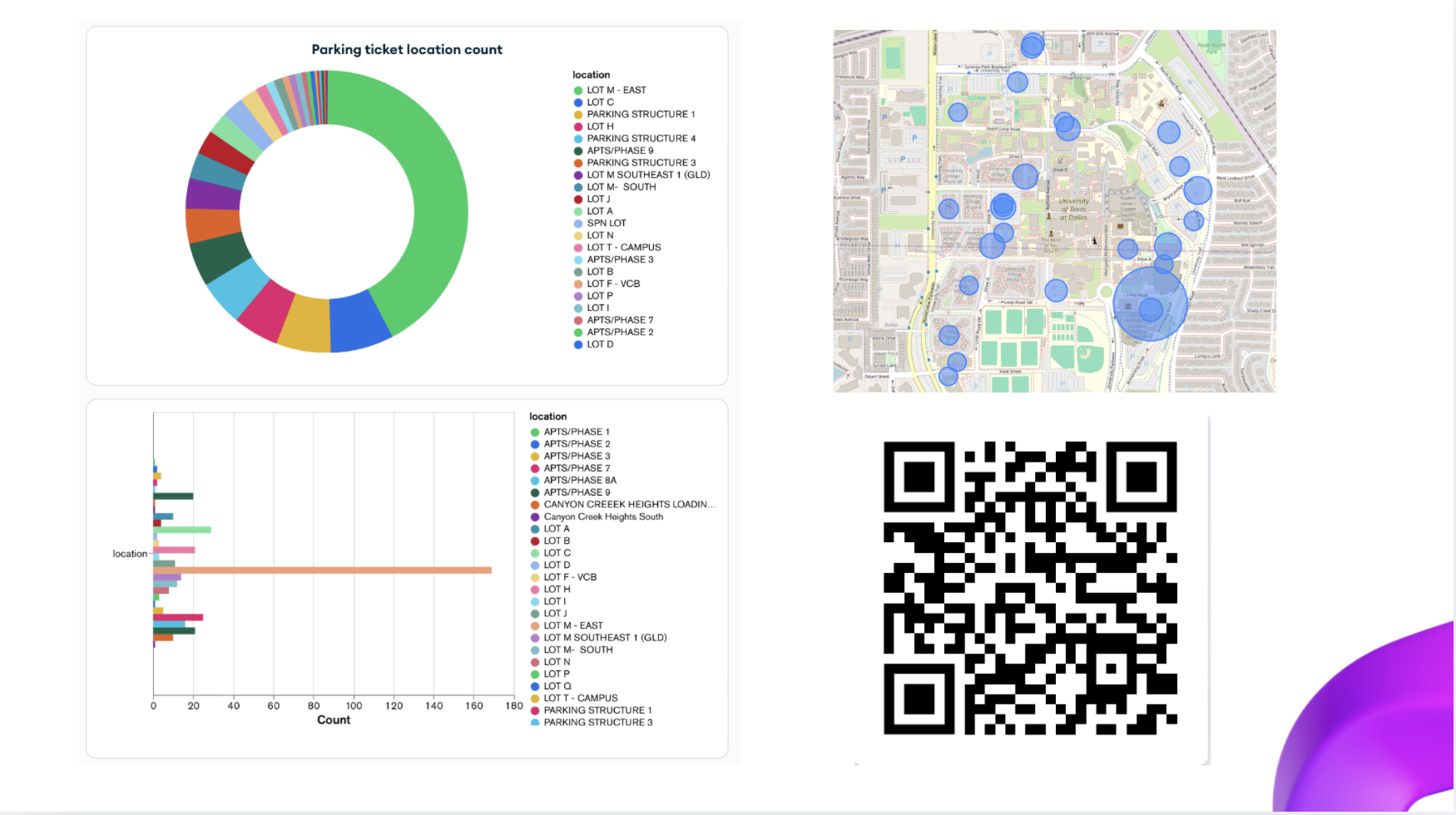
Use past UT Dallas unpaid parking ticket data to generate actionable insights through interactive dashboards and predictive analysis, allowing users to explore trends and identify when and where parking enforcement is most likely to occur.
How we built it
We first needed to collect the parking citation data since it wasn’t publicly available as a dataset. While exploring the UT Dallas parking portal, we noticed that citation numbers increase sequentially as new tickets are issued.
Using this pattern, we built a scraper with Playwright, a browser automation library, and implemented a binary search strategy to efficiently locate valid citation numbers and retrieve their records instead of brute-forcing the entire range.
During early development, the scraped data was stored locally in PocketBase. As the dataset grew and we wanted better tools for exploration and visualization, we migrated the data to MongoDB and used MongoDB Charts to analyze patterns in the dataset.
You can view the dashboard here: https://charts.mongodb.com/charts-orbittrends-wgjunza/public/dashboards/188f46ee-f660-4974-90ff-140de075da66
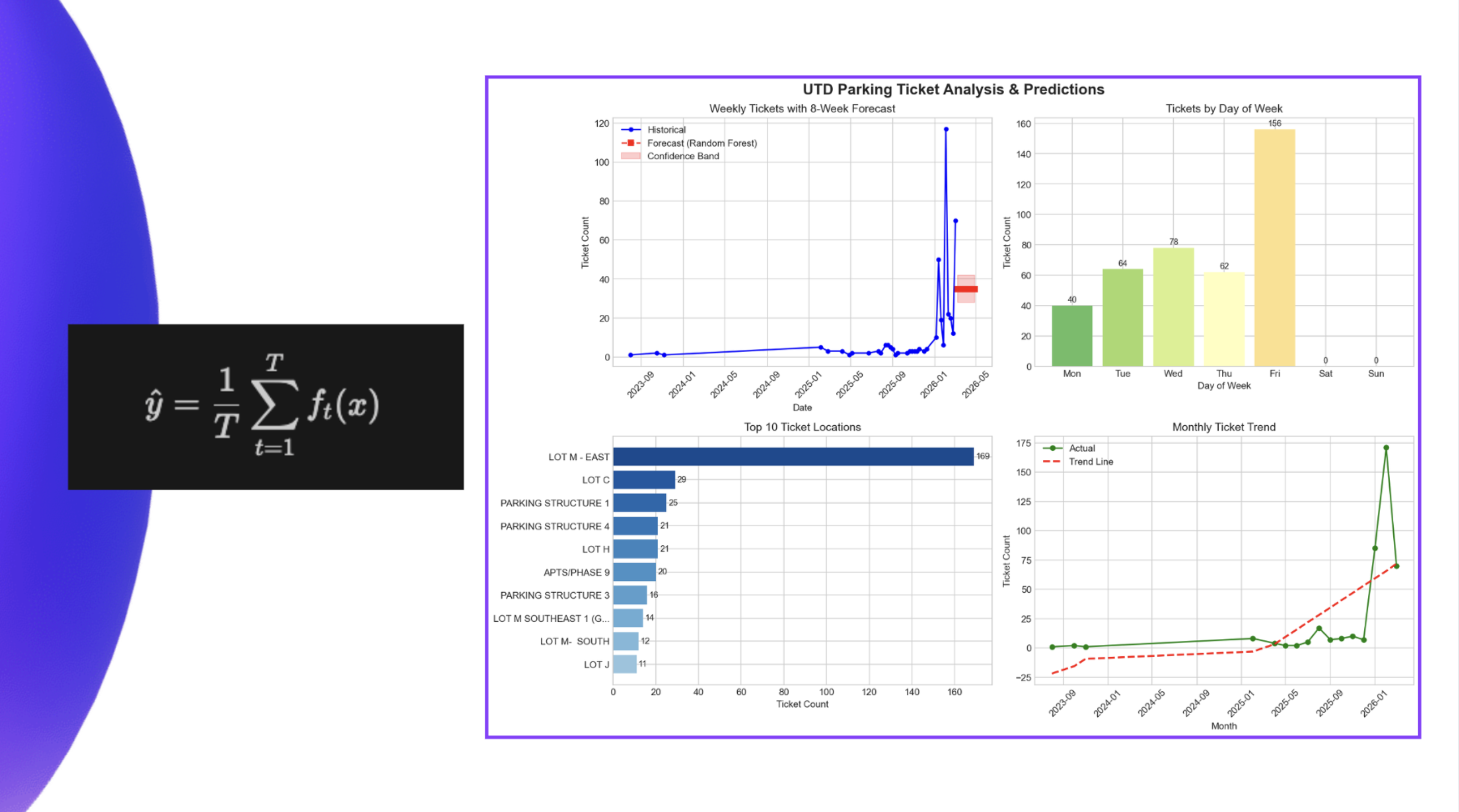
After exploring the data, we wanted to answer questions such as which days are most likely to have higher enforcement activity and what times of day tickets are most likely to be issued. To do this, we trained machine learning models using scikit-learn and engineered features from the citation timestamps such as hour of day and day of week. These models estimate the probability of parking enforcement at different times, turning historical ticket data into predictive insights.
Challenges we ran into
There was significant security in front of the parking ticket data, including frequent reCAPTCHAs that made automated retrieval difficult. Additionally, once some tickets were paid, their records were removed from the parking portal, creating gaps in the dataset. As a result, the initial data retrieval and cleaning process was challenging and required several workarounds to gather and maintain a reliable dataset.
Accomplishments that we're proud of
Being able to work together, and being able to come to consensus without wasting time.
What we learned
We learned automated web scraping, some machine learning algorithms, and how to give a solid product pitch.
Looking Ahead
We would want to create a responsive frontend built with React to display the insights. We used Figma to create a mockup of the features we wanted to use, and explore directions of the data stories we could create.
Figma Project: https://www.figma.com/make/vtKnLnSo6vKicfQe64l4SQ/Untitled?t=ajCn9cZ5IDYt3CYO-1&preview-route=%2Freports
Built With
- gemini
- github
- javascript
- jupyter-notebook
- mongodb
- next.js
- playwright-+-chrome
- pocketbase
- python

Log in or sign up for Devpost to join the conversation.