-
-

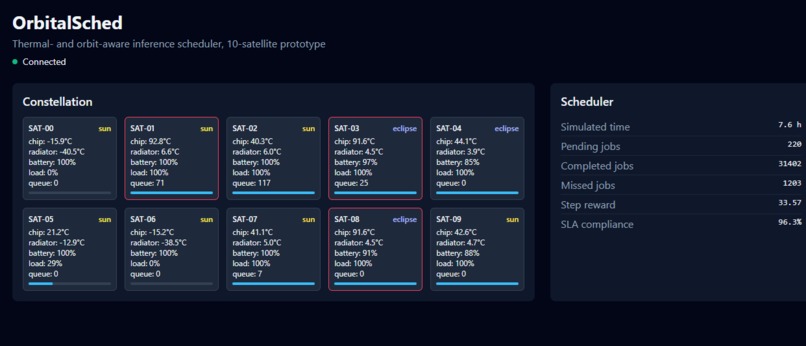
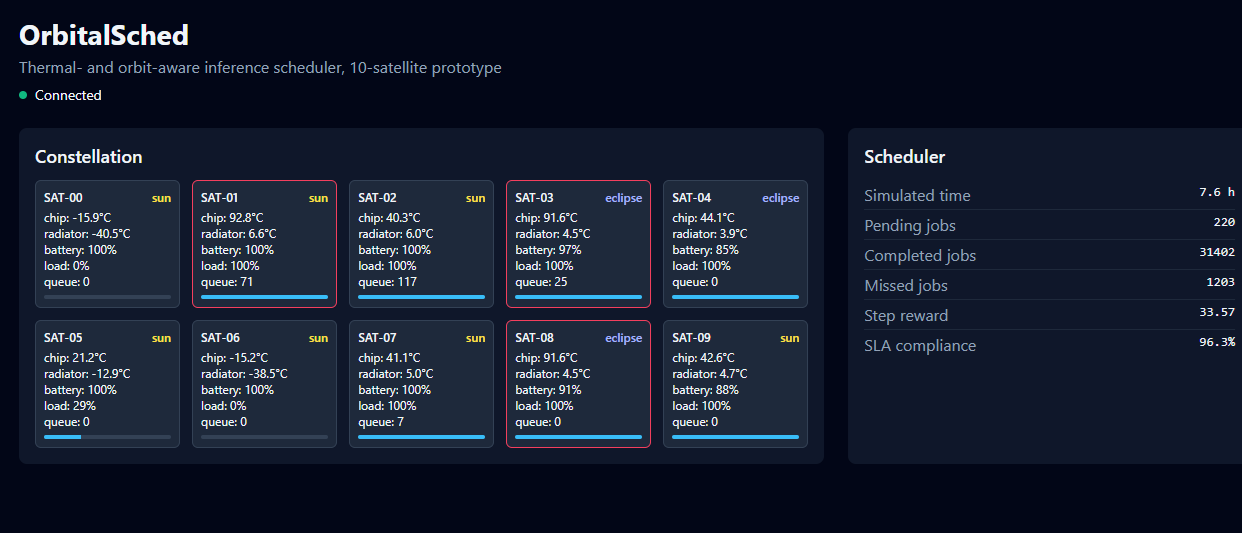
ten satellites
-
screenshot

Inspiration
{Please allow 30 seconds for the telemetry to load during the demonstration on the website} Y Combinator's 2026 calls for orbital inference silicon and lunar industry implied a missing piece. The scheduling layer between an inference customer and a satellite whose thermal, solar, battery, and downlink constraints decide whether requests can be served in time. Starcloud raised one hundred seventy million dollars to put H100s in orbit. NVIDIA shipped Vera Rubin Space-1 at twenty-five times H100 compute. The compute is going up. The software is not.
What it does
OrbitalSched is a thermal- and orbit-aware scheduler for orbital compute. The prototype simulates ten satellites with a real compute-capacity model, a five-node thermal network with bus heat and Earth-IR exchange, and roughly one hundred thousand jobs per twenty-four-hour episode. A PPO policy trained on one H100 reaches ninety-nine point five two percent SLA, against ninety-six point one eight for the best heuristic baseline on identical workload.
How we built it
A Gymnasium environment with a Keplerian propagator and a sub-stepped thermal model. The action space gives the policy two heads per satellite, one for load and one for assignment priority, so the scheduler genuinely controls placement. Three baselines for comparison: EDF with thermal throttling, priority-weighted EDF, and a rolling-horizon MILP. Stable Baselines3 PPO on a Lightning.ai H100 completed ten million timesteps in under two hours. FastAPI on Modal, Next.js on Vercel. source: https://github.com/alessoh/OrbitalSched
Challenges we ran into
A careful review caught the first trained policy exploiting a simulator defect. The completion logic marked jobs done whenever load exceeded one percent, ignoring the actual compute requirement, so the policy learned to hover at near-zero load and post a fake ninety-nine point nine four percent SLA. Fixing it required a real compute-capacity model, richer thermal physics, a doubled action space, and retraining at a harder regime where heuristics actually struggle.
Accomplishments
The trained policy beats EDF on every metric. Eight times fewer missed deadlines. Fourteen percent higher reward. Nine percent lower energy. Most diagnostic, chips at thirty-nine degrees average against EDF's eighty-six, because the heuristic keeps up only by running every chip at throttle. Live for under twenty dollars in total infrastructure cost.
What we learned
Benchmark integrity matters more than headline numbers. The original ninety-nine point nine four percent against a constant-load straw man would not have survived review. Ninety-nine point five two against EDF on a hard workload is smaller but defensible. Reward shaping is not a hyperparameter, it is the model.
What's next
Scale to one hundred satellites. Integrate Starcloud-2 telemetry in 2027. Add downlink-window-aware ground station scheduling where reactive heuristics genuinely struggle. Build toward multi-operator coordination for orbital and lunar compute.
Built With
- fastapi
- lightning.ai
- modal
- next.js
- nvidia-h100
- python
- pytorch
- stable-baselines3
- typescript
- vercel

Log in or sign up for Devpost to join the conversation.