Inspiration
Every student keeps notes everywhere. Obsidian, Notion, random .txt files, screenshots, lecture slides. The problem isn't storing them. The problem is that the connections between them exist only in your head, and your head forgets.
I kept having moments where I'd be reading about some ML paper and think "wait, this is the same idea as something from my business class last semester." But I could never find the other note, and even when I could, nothing helped me see the pattern. I wanted a tool that could see those patterns for me.
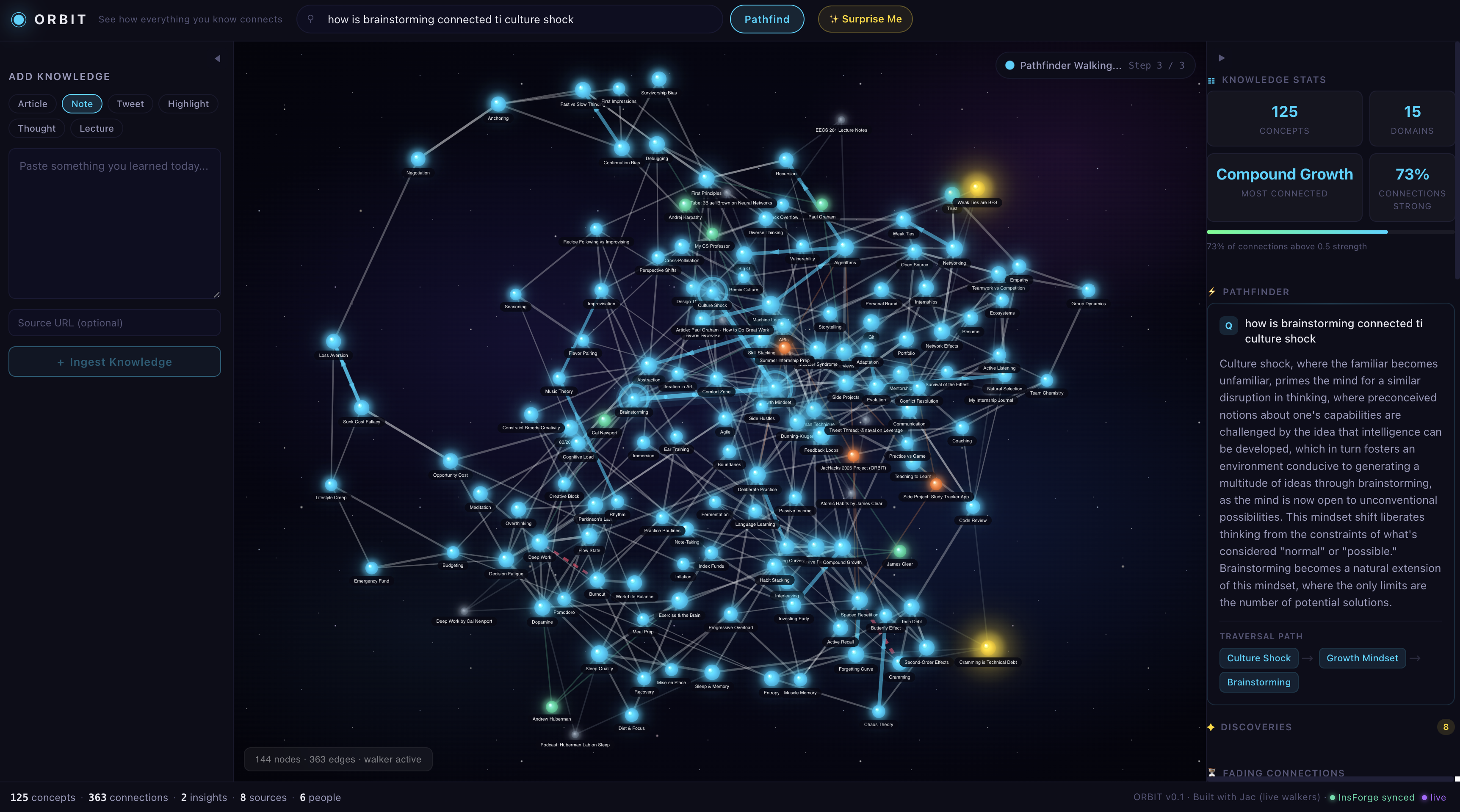
That became ORBIT. A second brain that doesn't just store your notes, it walks through them looking for connections, and answers your questions by physically traversing between ideas.
What it does
You feed ORBIT text (notes, articles, tweets, lecture snippets). It extracts the concepts, figures out how they relate to everything you've already added, and wires them into a living knowledge graph. Nodes are concepts. Edges are typed relationships (relates_to, builds_upon, contradicts, etc.).
Then the agents kick in:
- The Pathfinder walker answers your questions by finding the concepts in the question, walking paths between them through the graph, and using an LLM to explain the path it walked. The path IS the reasoning.
- The Explorer walker runs in the background. It picks random starting points, does weighted random walks biased toward weak edges, and surfaces hidden cross-domain insights you'd never find on your own.
- The Ingestor walker assesses every new concept against every existing one using an LLM, and only creates edges when the relationship is real.
- The Consolidator walker finds connections that are fading (using the Ebbinghaus forgetting curve) and flags what you're starting to forget.
- The Cartographer walker groups your knowledge by domain and tells you where your dense zones and blind spots are.
The frontend is a force-directed graph that glows. You can see the walker literally hopping from node to node when it answers your question. Open ORBIT in two browser tabs and updates sync live between them.
How I built it
The entire backend is written in Jac. Not a Python app with Jac sprinkled in, actually Jac. I picked Jac because the thesis of the whole project (knowledge is a graph, understanding is walking it) only maps cleanly onto a language where walkers, nodes, and typed edges are first-class primitives.
Structure:
- 14 .jac files total
- 6 node archetypes, 8 edge archetypes
- 5 walker agents with different traversal patterns
- 12
by llm()functions withsemannotations and per-function temperature tuning - Python interop for the math-heavy graph algorithms (BFS, PageRank, Louvain clustering, Brandes centrality)
jac start src/app.jacgives me a full REST API with Swagger docs automatically
The frontend is React plus react-force-graph-2d for the visualization. Dark space theme, dense starfield, nodes glow and pulse, walker trail leaves a luminous path you can see animate in real time.
InsForge handles two things: Postgres persistence so your graph survives across sessions, and realtime websocket sync so changes propagate across tabs instantly. Every node/edge/insight publishes to a per-user channel. LLM inference is Groq running llama-3.1-8b-instant.
Challenges we ran into
The biggest one took hours. When a Jac walker does here ++> new_node inside an ability, it
invalidates the [-->] enumeration for that walker. So any subsequent query from here
returns only the newly-attached node, not the existing ones. This broke my dedup logic
silently for a long time. Fix was to snapshot existing nodes BEFORE mutating the graph.
Also hit a gnarly bug where Jac's Pathfinder walker was returning "paths" that weren't actually edge-adjacent. It was doing BFS but storing visited nodes in visit order, then slicing between two anchors. The slice wasn't a real path. Had to restructure to build a concept-only adjacency dict during scan and run BFS on that dict in the finish hook.
LLM tool-calling with short inputs like "X is smart" kept crashing Groq because the model
returned JSON in the wrong schema. Wrapped every by llm() call in try/except so partial LLM
failures don't abort walker execution.
Accomplishments I'm proud of
Getting the walker traversal animation to feel alive. You type a question and watch the walker literally hop from node to node with a glowing trail. It's the clearest explanation of "explainable AI" I've ever seen.
Also: the whole project genuinely would not exist in regular Python without me having to build my own walker framework. Jac made the central abstraction free.
What I learned
Jac is a real language, not a wrapper. Once you think in walkers and typed edges, a lot of code you'd normally write as plumbing just disappears. Also learned that graph decay models (Ebbinghaus forgetting curve per edge type) are a surprisingly good fit for personal knowledge management.
What's next
Actual importing from Obsidian, Apple Notes, web clippings. Mobile app for voice-ingested thoughts. Multi-user merging so two people's graphs can intersect and you can find shared blind spots.
Built With
- groq
- insforge
- jac
- jaseci
- javascript
- llama-3
- networkx
- postgresql
- python
- react
- react-force-graph-2d
- render
- vercel
- vite
- websocket
Log in or sign up for Devpost to join the conversation.