Inspiration
The inspiration came from a common problem every development team faces. You open a piece of code, see that it was modified months ago, and immediately have questions: Why was this change made? Was there a production issue? Is it safe to modify? Who made the decision?
The answers usually exist somewhere in merge requests, review discussions, linked issues, and pipeline history, but finding them often means spending significant time searching across multiple tools.
We realized that GitLab already contains the knowledge needed to answer these questions. The challenge is that the information is fragmented and difficult to retrieve. That led us to build Orbit Memory — a way to query the reasoning behind code changes using natural language and receive evidence-backed answers in seconds.
Getting here was not straightforward. The Orbit API uses a directed knowledge graph with strict relationship traversal rules — a single wrong direction silently returns zero results instead of an error, which made early query development a process of trial and error. On the other side, the LLM would confidently generate plausible-sounding answers that were not grounded in the actual data, filling gaps with fabricated details. We spent significant time engineering the pipeline to solve both problems: building a deterministic query layer that handles graph traversal correctly, and an evidence-ranking system that forces the LLM to cite real merge requests and report what it does not know rather than guess.
What it does
Orbit Memory is an institutional knowledge agent that reconstructs the reasoning behind code by querying the GitLab Orbit knowledge graph. It operates as both a CLI tool and a GitLab Duo Chat agent, published on the GitLab AI Catalog.
A developer asks a natural language question and gets a cited, evidence-backed answer drawn from actual merge request history, review discussions, linked issues, and pipeline results.
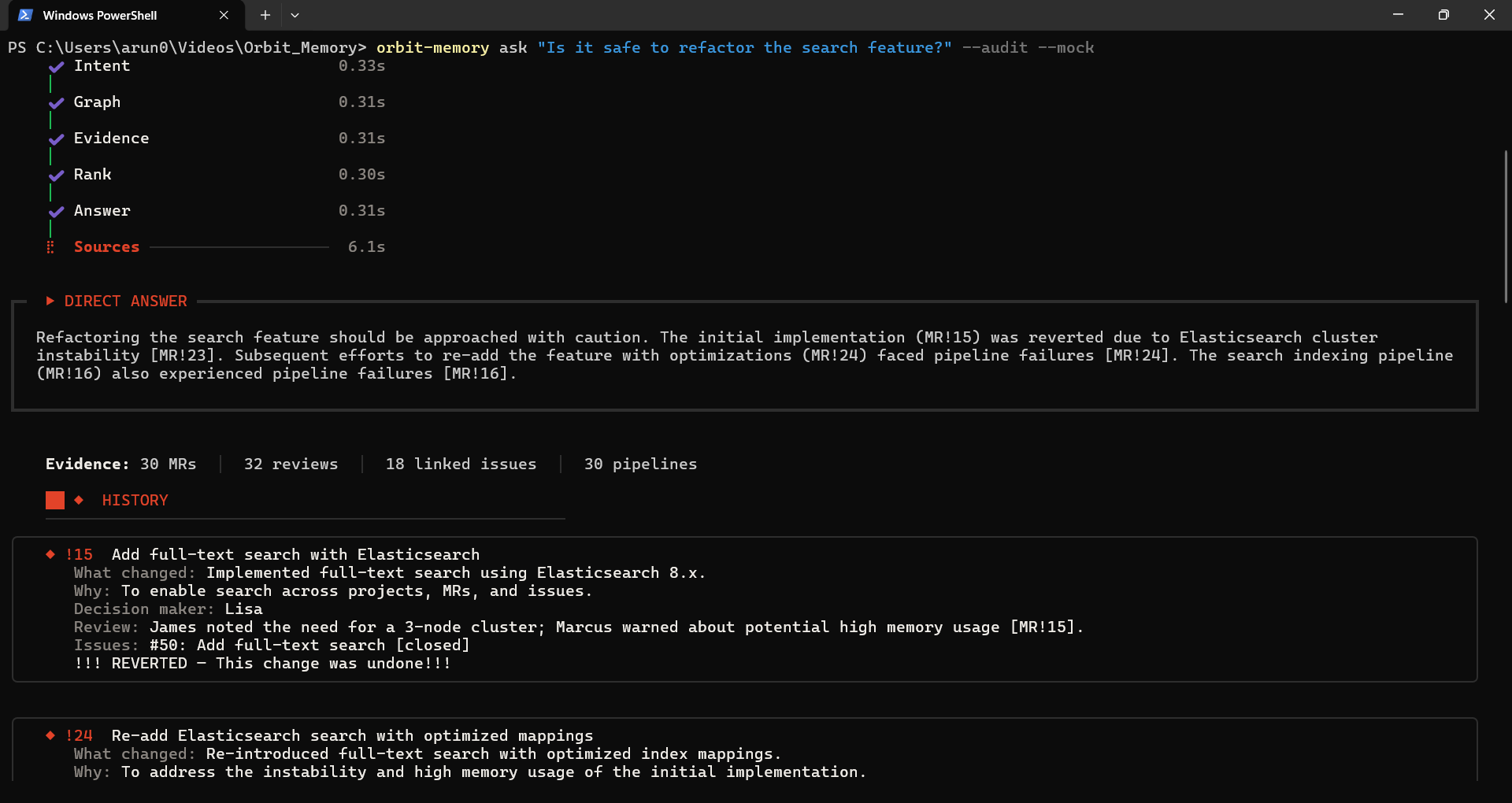
$ orbit-memory ask "Why was process_payment changed?"
┏━ ▶ DIRECT ANSWER ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ ┃
┃ The payment system was upgraded from Stripe v2 to v3 because ┃
┃ Stripe v2 is being deprecated in Q3 [MR!2]. The upgrade added ┃
┃ async/await support for non-blocking payment processing and ┃
┃ retry logic with exponential backoff. ┃
┃ ┃
┗━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┛
Evidence: 30 MRs │ 32 reviews │ 18 linked issues
intent WHY ┃ mrs 7/30 ┃ 5.8s
Beyond asking questions, developers can assess knowledge concentration risk with bus-factor, generate onboarding briefings for any module with briefing, and interactively browse the knowledge graph with explore. Query history, connectivity health checks, and configuration validation are all built in.
The output adapts to the developer's context — from a quick two-sentence answer in --brief mode, to a full diagnostic trail in --audit mode for forensic investigation, to machine-readable --json for downstream tooling. A built-in --mock flag activates a 30-MR sample dataset so the tool can be demonstrated and tested without a live GitLab instance.
How we built it
This is not an AI wrapper. Orbit Memory is a three-phase pipeline that transforms raw graph data into cited, verifiable narratives. The LLM's role is narrow: take structured evidence, produce a narrative, cite sources. Everything else — intent detection, graph traversal, enrichment, scoring, quality assessment — is deterministic.
"Why was process_payment changed?"
│
▼
┌──────────────────────────────────────┐
│ PHASE 1: QUERY │
│ │
│ Classify question into one of │
│ 13 intent types (WHY, WHO, WHAT, │
│ HOW, SAFETY, DEPENDENCIES, REVERT, │
│ ISSUES, REVIEWER, HISTORY, etc.) │
│ │
│ Build Orbit graph traversal query │
│ using one of 6 query strategies │
│ Execute against the knowledge graph │
└──────────────────┬───────────────────┘
│
▼
┌──────────────────────────────────────┐
│ PHASE 2: EXTRACT │
│ │
│ For each MR, run 9 parallel │
│ enrichment calls: │
│ reviewers, approvers, merger, │
│ labels, files, note authors, │
│ linked issues, pipelines, │
│ review comments │
│ │
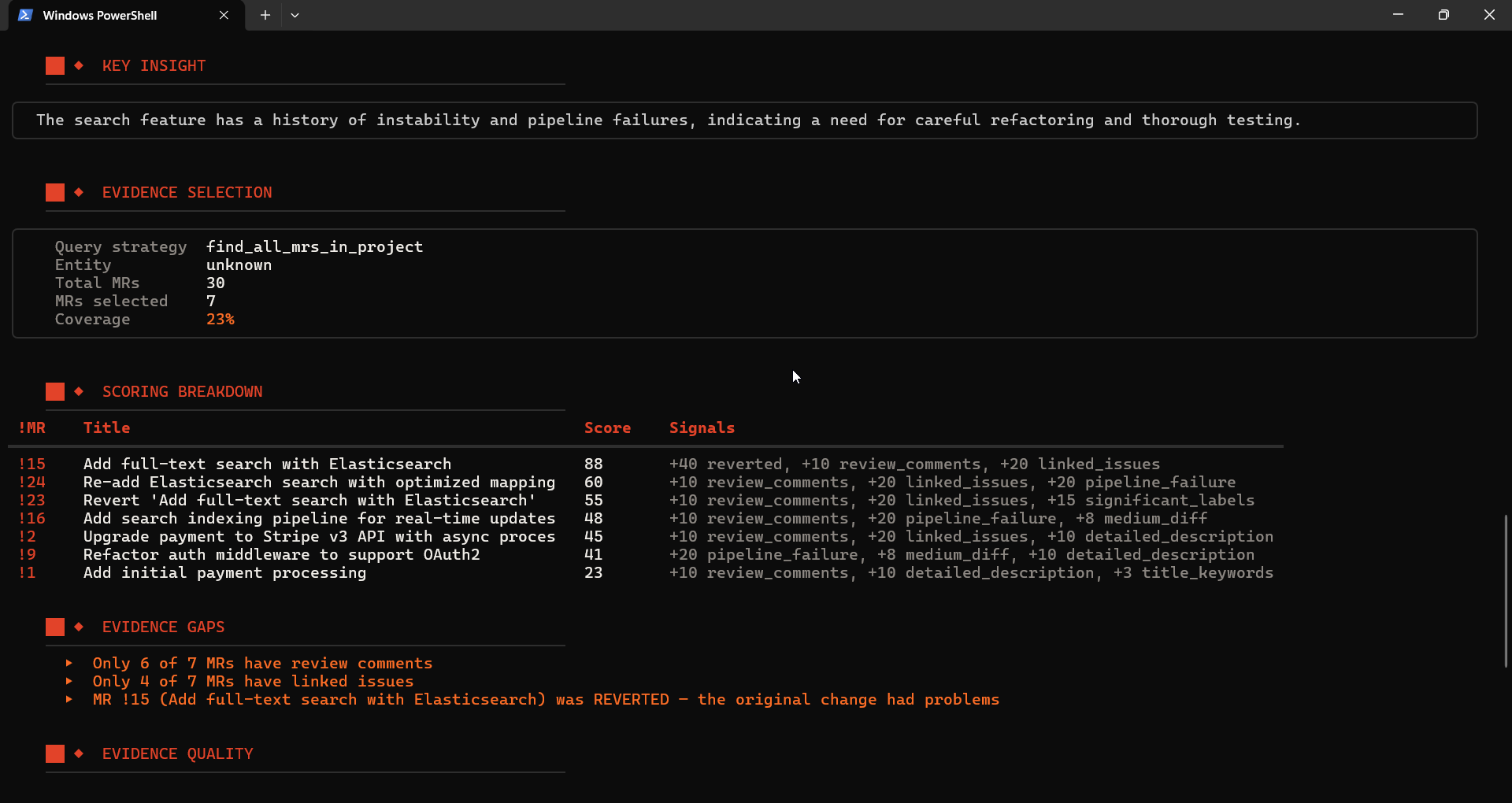
│ Score every MR using 10 signals: │
│ reverted (+40), review depth (+25), │
│ linked issues (+20), pipeline │
│ failures (+20), labels (+15), │
│ diff size (+15), and more │
│ │
│ Rank and select top N evidence │
└──────────────────┬───────────────────┘
│
▼
┌──────────────────────────────────────┐
│ PHASE 3: SYNTHESIZE │
│ │
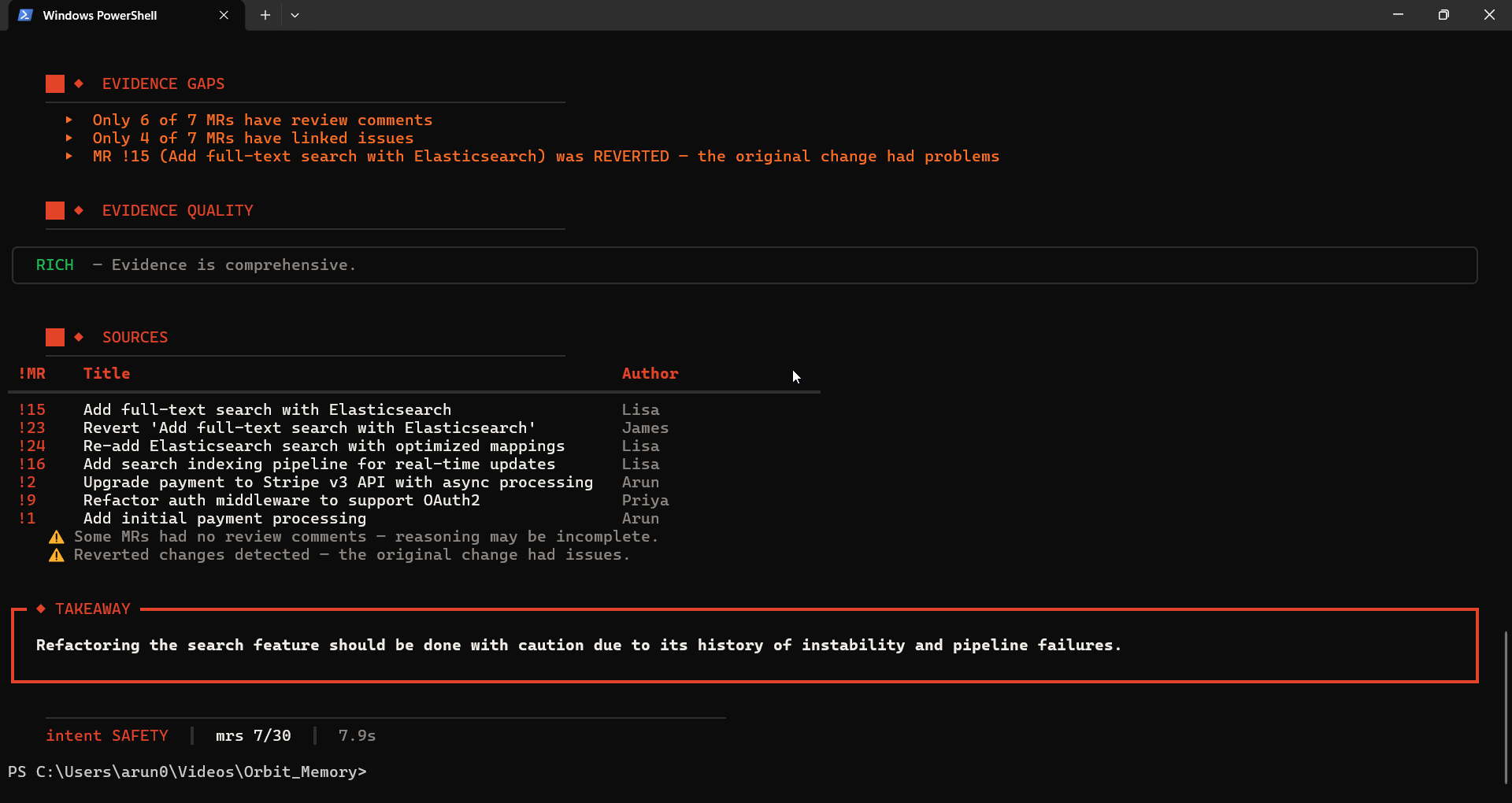
│ Build evidence quality report: │
│ RICH / MODERATE / SPARSE │
│ Detect and flag specific gaps │
│ "Only 1 of 3 MRs have reviews" │
│ │
│ Send structured evidence + quality │
│ report + intent-specific rules │
│ to the LLM │
│ │
│ Every claim must cite [MR!N] │
│ Missing data reported, not guessed │
│ Confidence notes flag uncertainty │
│ │
│ Output formatted for terminal │
│ (Rich) or machine-readable (JSON) │
└──────────────────────────────────────┘
Intent classification runs first and drives everything downstream — which graph queries execute, which evidence gets prioritized, and what synthesis instructions the LLM receives.
The 9 parallel enrichment calls per MR reduced query time from approximately 25 seconds to 10-15 seconds. The 10-signal scoring system ensures the most architecturally significant decisions surface first, not just the most recent ones.
The evidence quality system evaluates data density before synthesis and injects gap reports into the LLM context. This is what prevents hallucination — the model is explicitly told what data is missing and instructed to report gaps rather than fill them.
Challenges we ran into
The biggest challenge was the Orbit API's strict directed graph model. Relationship direction is enforced — using the wrong direction returns zero results silently. No error, no warning. We spent significant time debugging empty responses before building programmatic direction enforcement into the query layer.
The second challenge was LLM hallucination. Without guardrails, the model would fill sparse evidence with plausible but fabricated details. We solved this by injecting evidence quality reports and gap detection directly into the LLM context, enforcing citation rules, and detecting hedging language in outputs.
Resolving anonymous review comments was also non-trivial. Review comments in the graph don't always carry author identity directly, requiring an enrichment step that maps note authors against the MR's reviewer and approver set.
Running 9 enrichment queries per MR introduced complex error handling. A single MR's enrichment failure could not be allowed to crash the entire pipeline, so we built per-MR error isolation that degrades gracefully.
Accomplishments that we're proud of
Orbit Memory is fully functional against real GitLab instances, not a prototype. Published on the GitLab AI Catalog as an installable Duo Chat agent.
284 tests across 8 modules covering intent classification, query building, context extraction, ranking, evidence reporting, narrative generation, UI layout, and verbosity resolution.
Language-agnostic by design — it queries SDLC entities (MRs, issues, users, pipelines), not source code, so it works across all languages indexed by Orbit without configuration.
Five output modes serving five different use cases — from quick answers in chat to full forensic investigation — all powered by the same pipeline.
The system explicitly reports what it doesn't know. When evidence is sparse, it says so. It does not guess.
What we learned
Intent classification is the highest-leverage component. Getting the intent right determines everything downstream. We iterated on the intent system more than any other part.
Graph directionality is non-obvious. Developers think "this MR has reviewers" but the graph stores it as "User REVIEWED MergeRequest." This semantic gap caused more bugs than any other technical issue.
LLMs are better synthesizers than retrievers. The LLM in Orbit Memory has a narrow role — take structured evidence, produce a narrative, cite sources. The deterministic pipeline handles retrieval, scoring, and quality assessment.
Evidence quality matters more than quantity. Three well-documented MRs produce a better answer than thirty MRs with only titles.
Developers trust tools that admit uncertainty. Users consistently preferred answers that flagged gaps over tools that produced confident but unverifiable claims.
What's next for Orbit Memory
Deeper code-level exploration — developers will be able to ask about specific functions, classes, and modules, getting walkthroughs of what the code does and why it was structured that way.
Proactive knowledge surfacing — when a developer opens an unfamiliar file or MR, relevant context will surface automatically without asking.
Team knowledge health dashboard — project-wide knowledge risk visualization identifying modules where critical knowledge is concentrated in a single person, tracking distribution over time.
Integration with merge request workflows — when a new MR touches a historically sensitive area, Orbit Memory will automatically post decision history as an MR comment, giving reviewers the context they need before approving.
Built With
- click
- gitlab
- gitlab-ai-catalog
- gitlab-duo-agent-platform
- gitlab-orbit-api
- httpx
- pytest
- python
- rich

Log in or sign up for Devpost to join the conversation.