

Inspiration
One of our members, Japnit, runs a Non-Profit Organization, Go Girl (https://www.gogirlorganisation.com/), to teach underprivileged girls how to code for free in India. They have taught over 2000 girls in the native Indian Language. One major challenge they face is understanding and determining the quality of lectures provided by tutors. They need to ensure that quality education is imparted to students from remote and rural India, especially in the online mode. Whether these lectures are engaging and the speech manner is appropriate for the class needs to be determined. Empirically defining the quality of these lectures/teaching sessions is challenging and a laborious task to go through recordings manually. That is until we developed this product to provide instant feedback for speakers and presenters to help them develop their presentation skills with actionable items.
What it does
1. Instant multimodal feedback for speakers to help improve their presentation skills: Giving presentations, speeches or awesome elevator pitches can often be a daunting task. By getting instant feedback on their presentations, speakers can either practice long stretches at once or complete crucial last-minute preparation for that pitch. Using a congregation of NLP, image and audio processing tools, our software provides instant feedback to the speakers and helps them improve their presentation in three different aspects, namely expressions, tone, and content.
2. Help speakers be more expressive and engaging: We use TensorFlow library, which uses its eye tracking and sentiment analysis capabilities to measure the speaker's engagement. The software helps the speaker feel more natural with their facial expressions and eye-movement during important presentations.
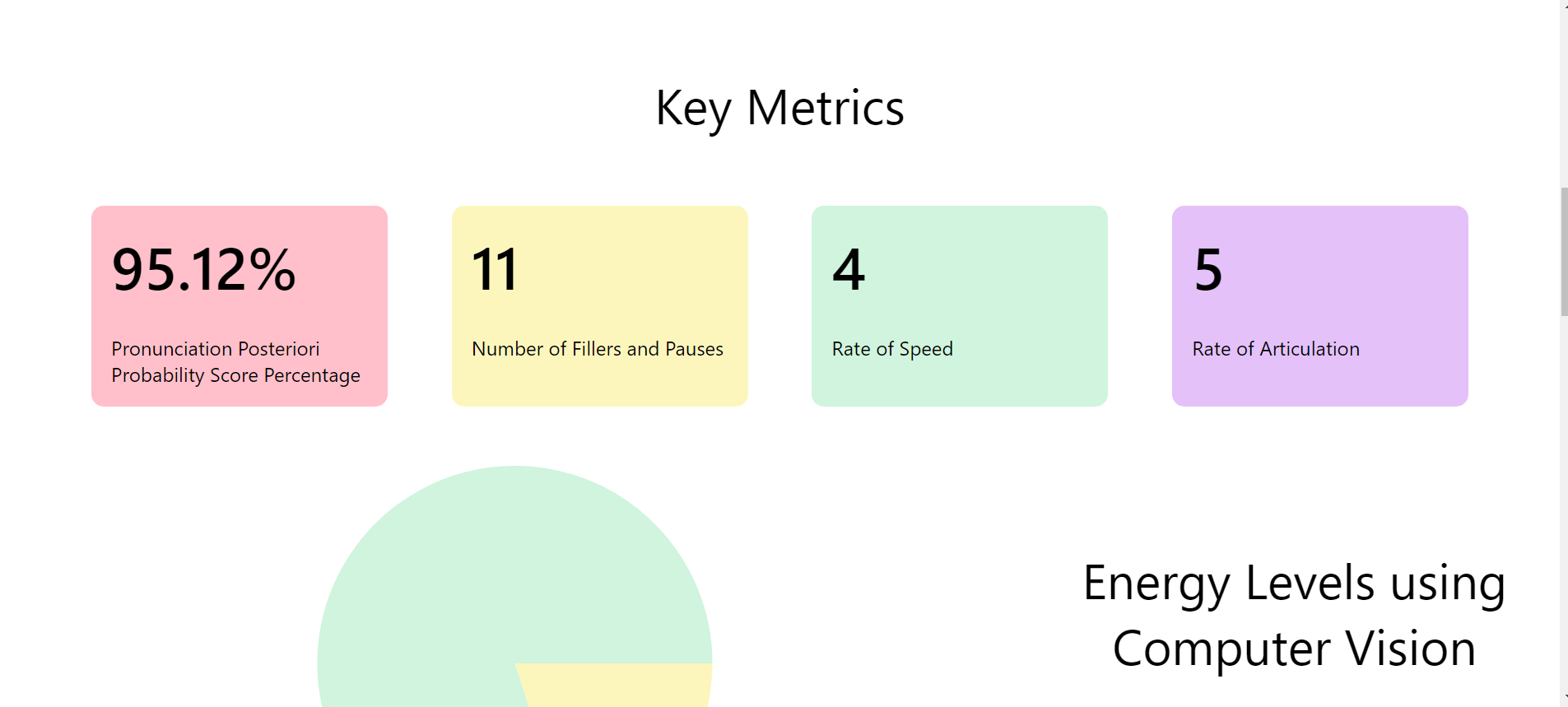
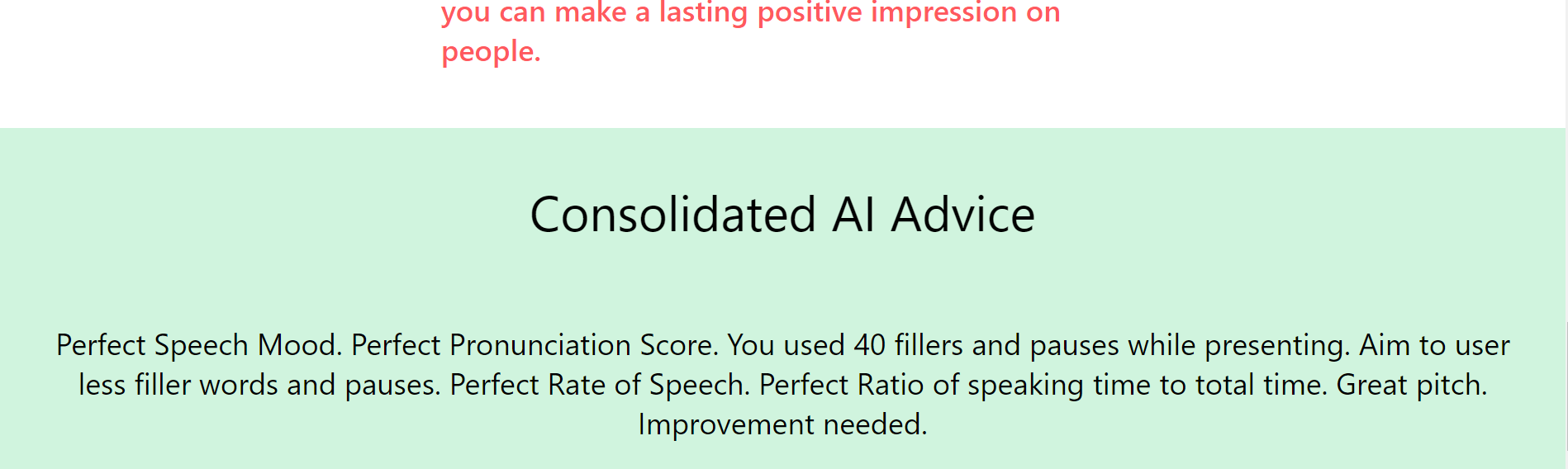
3. Provide feedback to make speakers sound more confident and relaxed: Several metrics such as the pace of speaking, number of pauses & usage of filler words, and pronunciation score can indicate the quality of a presentation. We use audio processing APIs to extract the relevant metrics and use Cohere’s generative model to analyze metrics to present personalized actionable methods of improvement in a concise manner.
4. Making sure that the content is on-point and free of unfavourable speech patterns: Using Cohere’s API for Topic extraction and content summarization, our software highlights the main ideas that are being put forward in your presentation. Our software is also able to detect speech patterns which are unfavourable during presentations. For example, we detect persistent repetition of the same ideas using cohere’s semantic search model.
Technologies Used
- Front-end development: React, Javascript
- Back-end development: Python with Flask.
- Image Processing: Tensor-flow
- Audio Processing: AssemblyAI API, My-Voice-Analysis API Built upon Praatscript based library
- Natural Language Processing: Cohere API
How it works
User selects a speech video they want to analyze. Instantly, TensorFlow library uses eye tracking and sentiment analysis capabilities to measure the speaker's engagement. Next, the video is transcribed using Assembly-API. The text is used by Cohere's API for analysis such as speech summarization and topic extraction. Then, My-Voice-Analysis is used to extract key metrics such as speech mood, pace, and clarity. Finally, Cohere's API is utilized again for overall analysis and to provide actionable feedback.
Challenges we ran into
- Dependency Issues while integrating numerous APIs and libraries to bring together different processing abilities of the software. Also integrating React, a javascript-based library, with flask and python-based scripts.
- Deciding which features to prioritize
- Providing the user with a user friendly, cohesive and centralized experience in a short period
Accomplishments that we're proud of
- We generated natural language feedback from distinct numeric metrics by manipulating prompts in cohere's generative models.
- We found and fixed implementation bugs in open-source audio processing library, "my-audio-analysis", for using in our project.
- We developed a working model of our idea pulling in various APIs and smaller modules/libraries.
What we learned
- We learnt how to use Cohere's various language models such as generative and embedding models for topic extraction and text summarization.
- Time Management and prioritization when working under a tight deadline.
- Audio to text conversion using Assembly AI
What's next for OratorMe
We want to provide more personal and intricate feedback to the users based on long term and continuous analysis of their presentation skills. We also want to work towards making the software more scalable and resilient for handling large quantities of video data.
Built With
- assembly-ai
- assemblyai
- cohere
- computer-vision
- flask
- javascript
- natural-language-processing
- praatscript
- python
- react
- tensorflow


Log in or sign up for Devpost to join the conversation.