-
-

gloo.wiki website
-
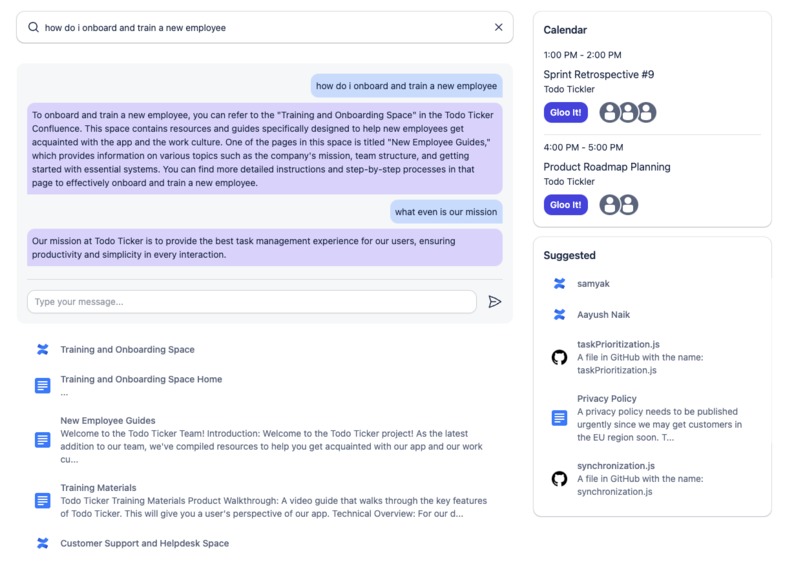
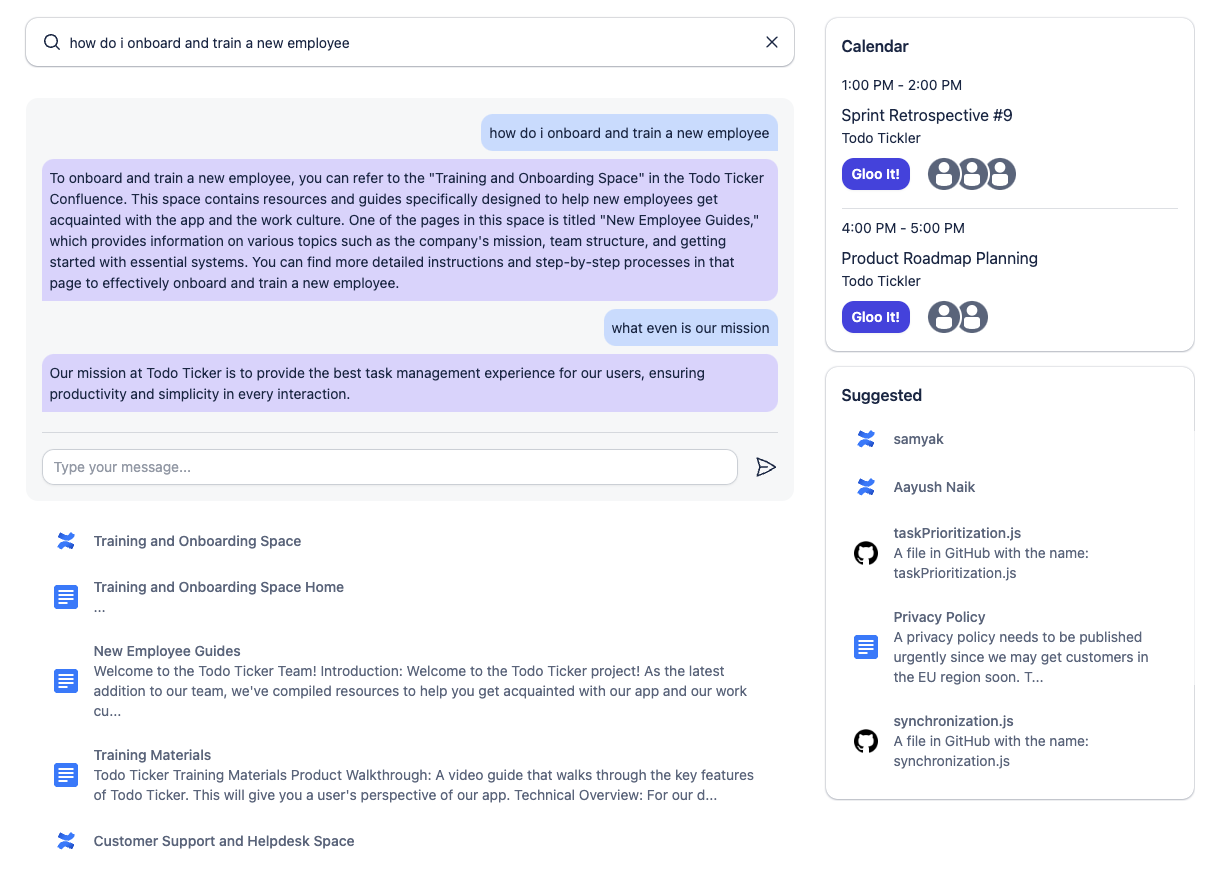
Chat with your data
-
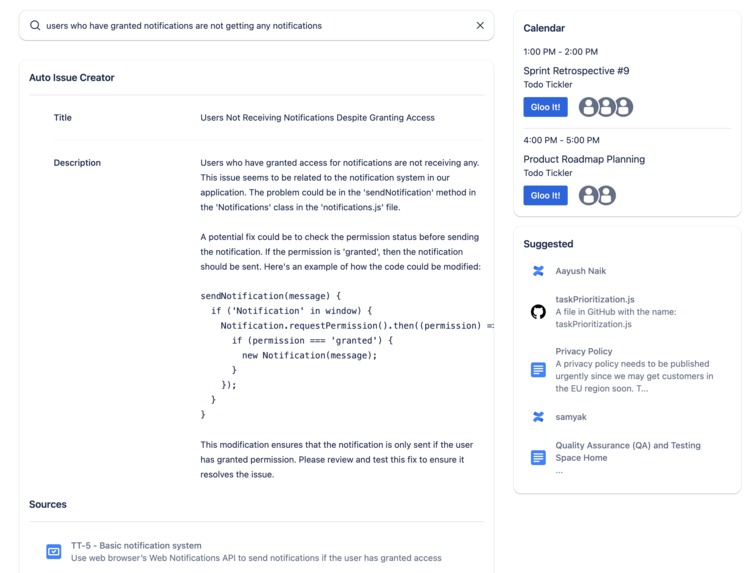
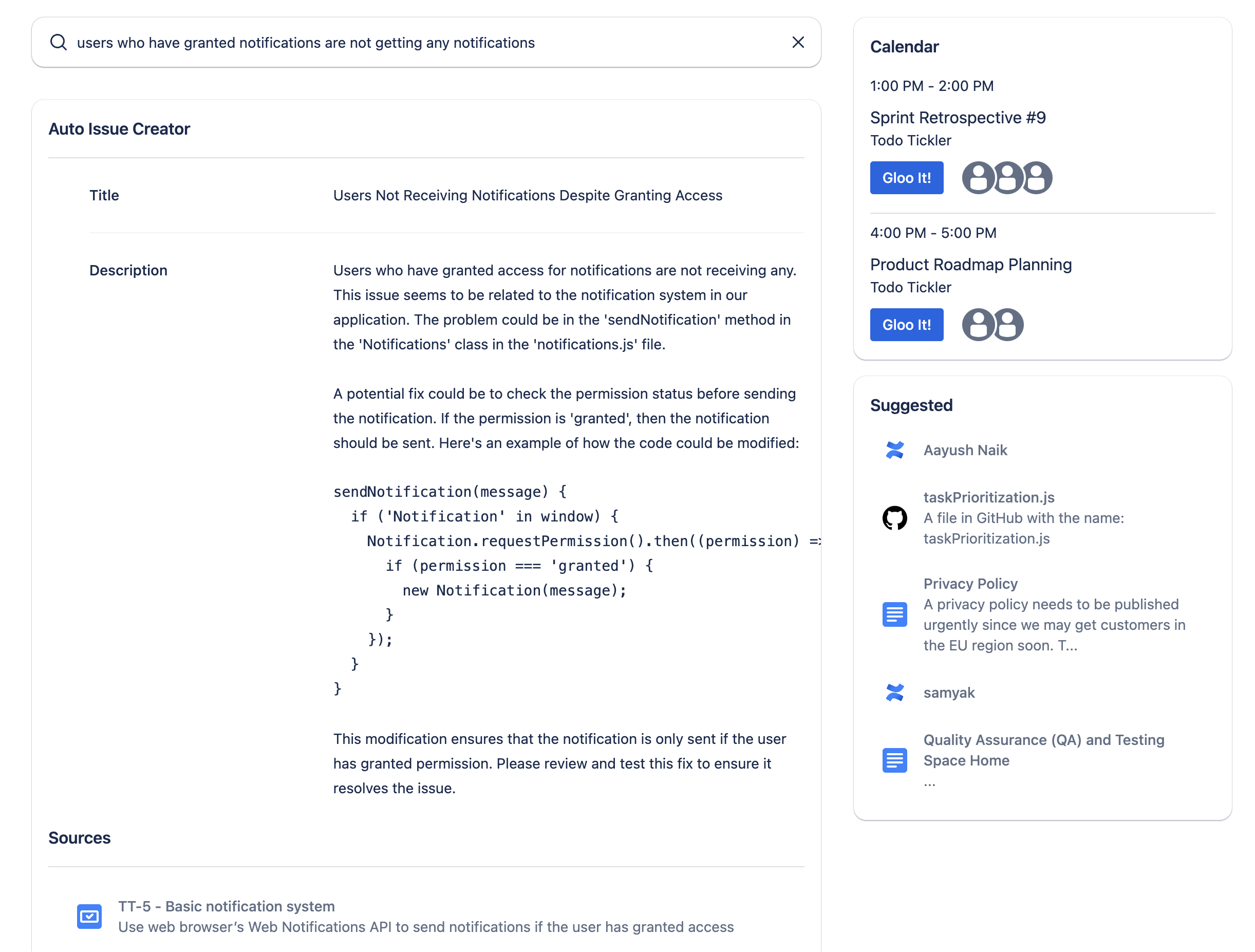
Automatically create issues and potential code fixes just from an issue description
-
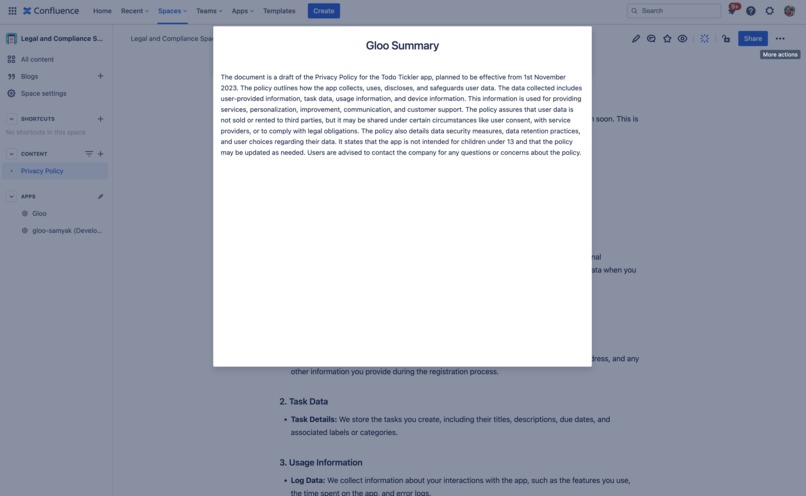
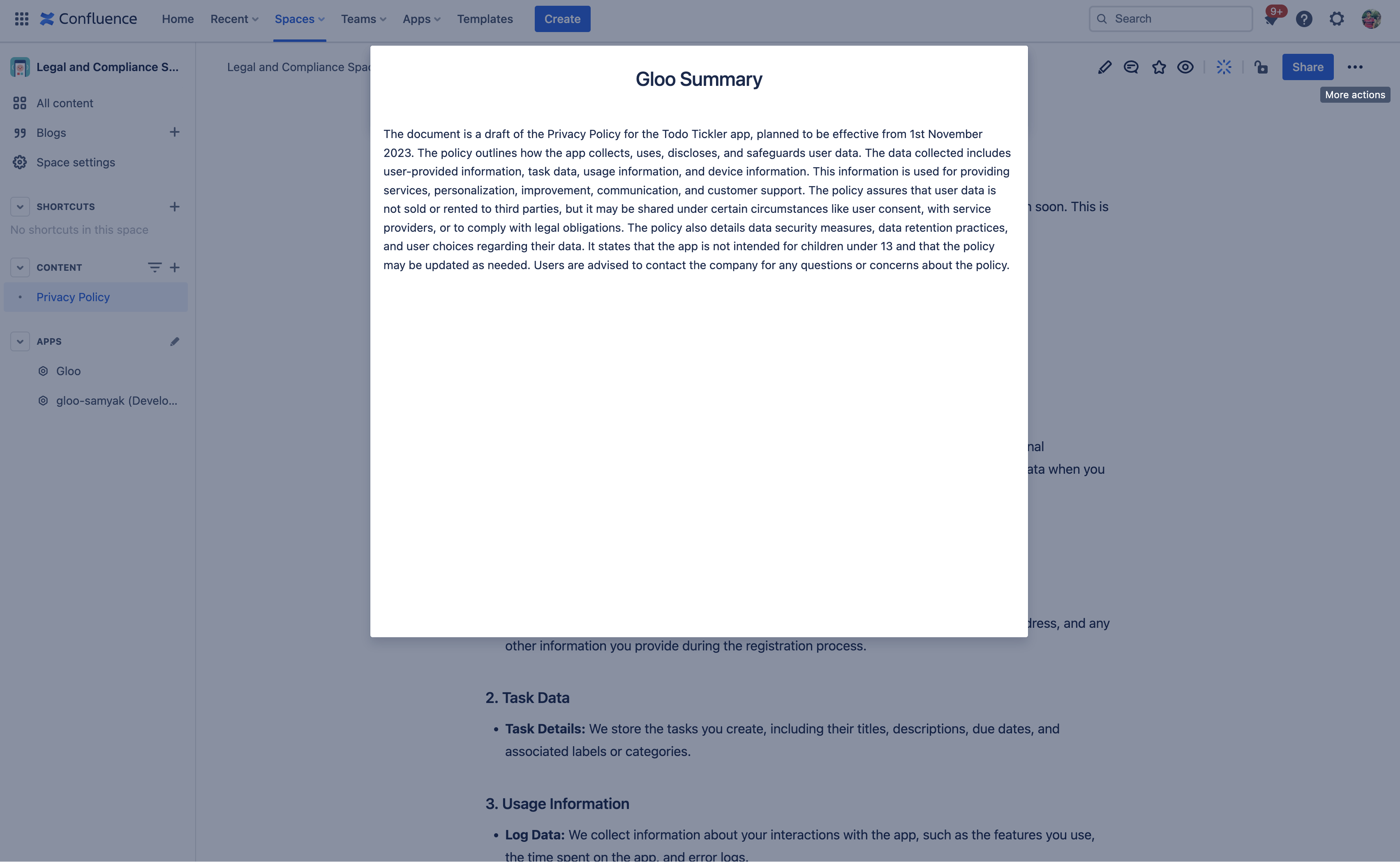
Generate concise summaries of any document
-
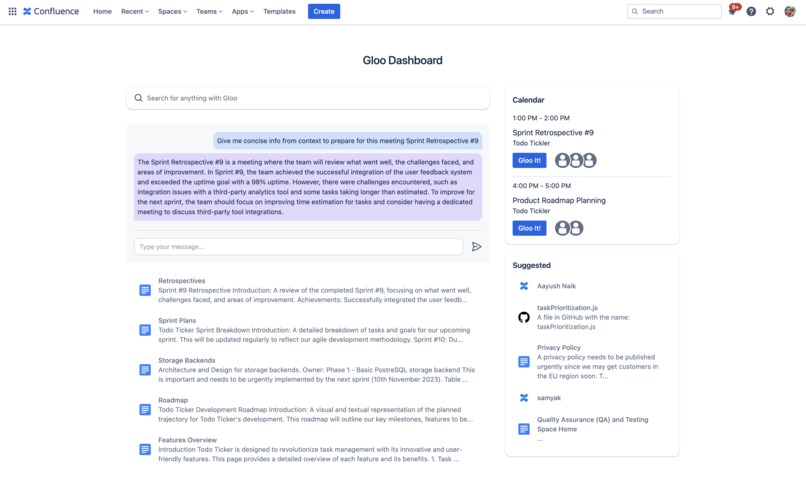
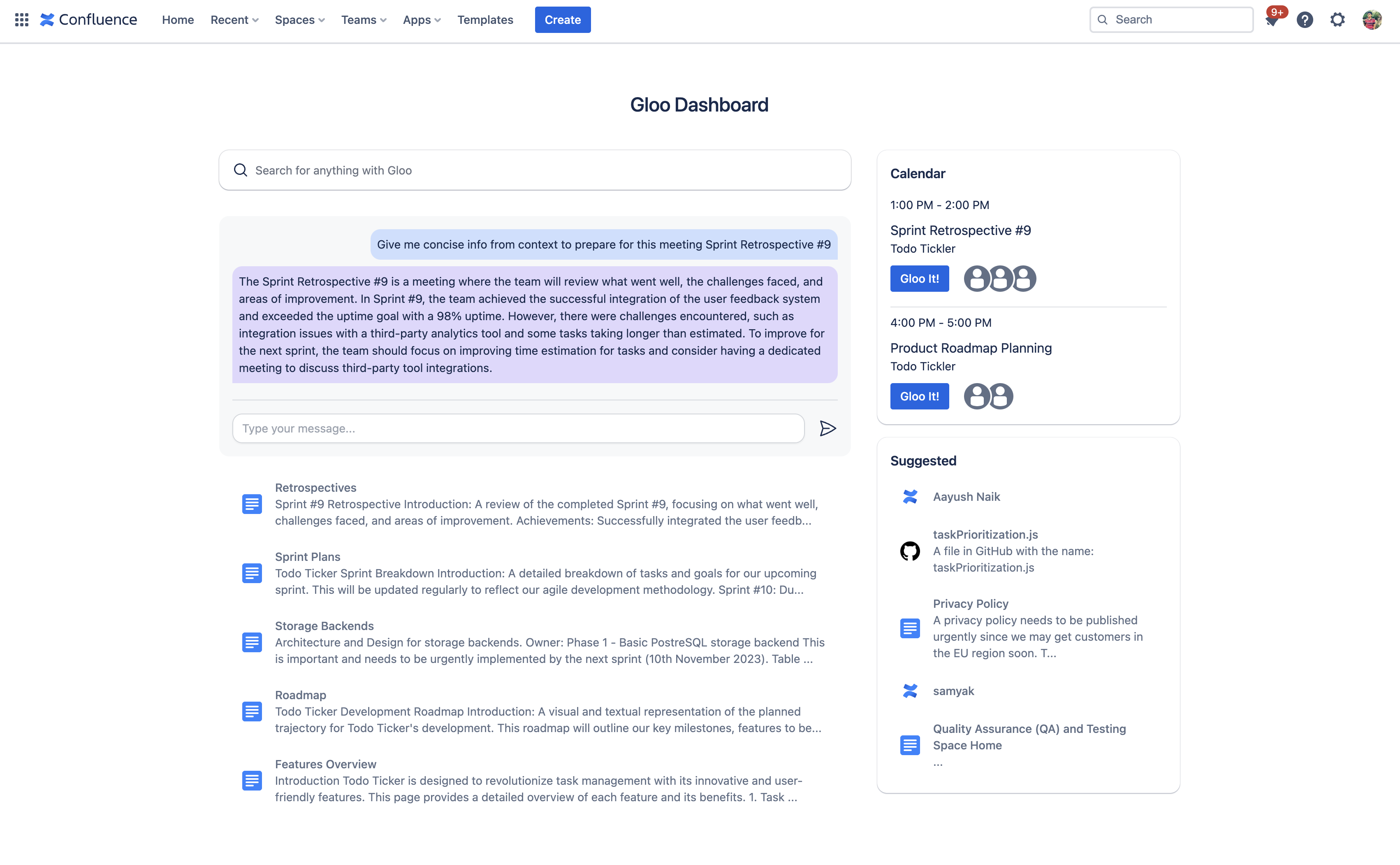
Gloo it! - get all information you need for a meeting with a click of a button
-
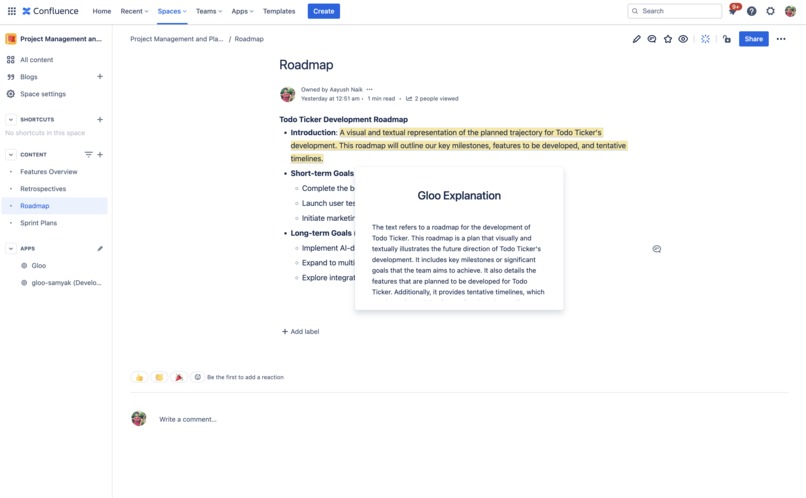
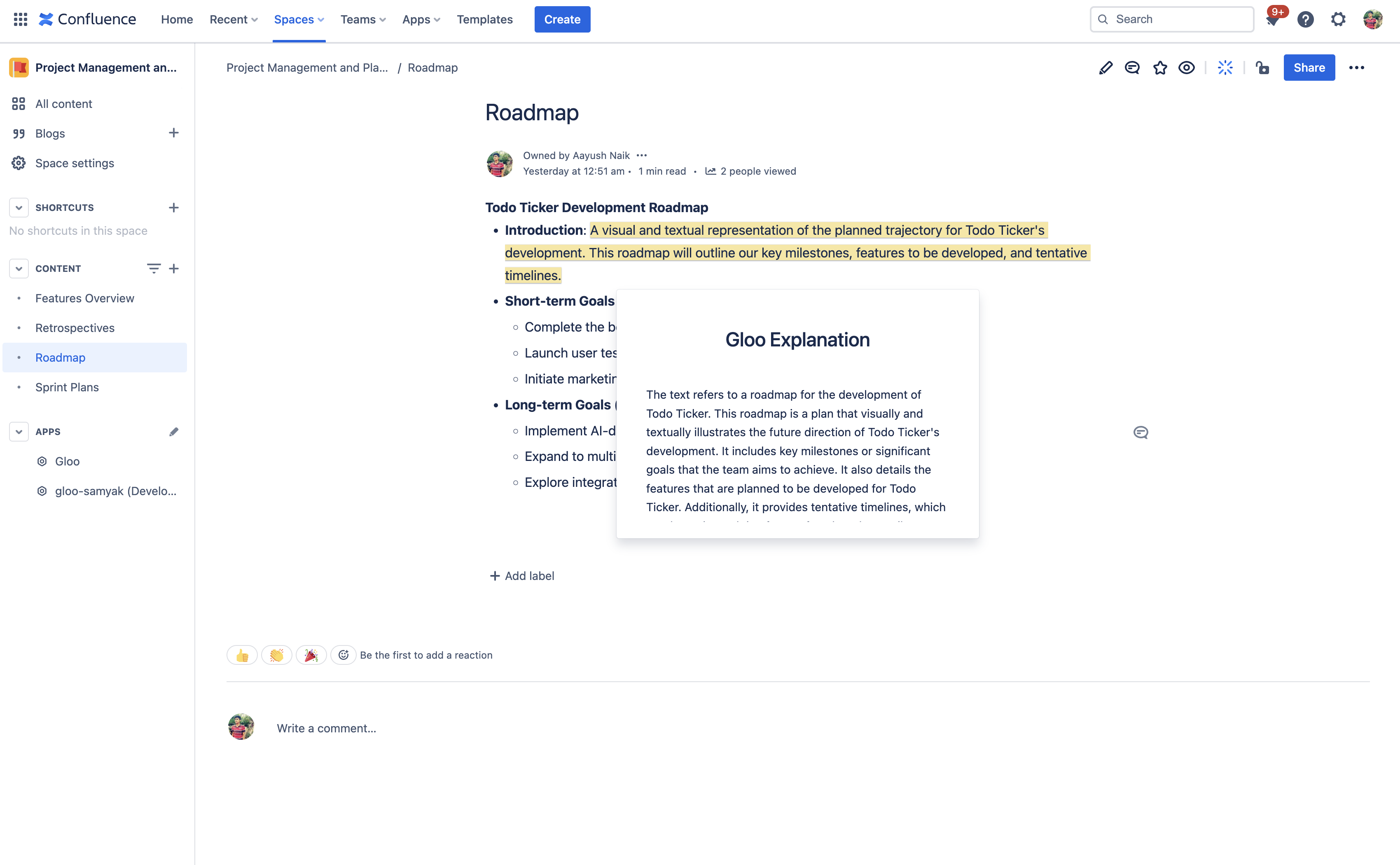
Explain any snippet using context from other documents
-
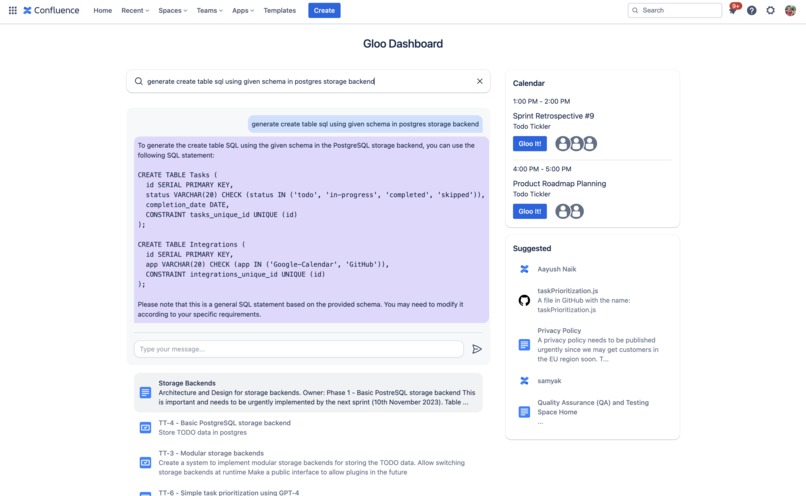
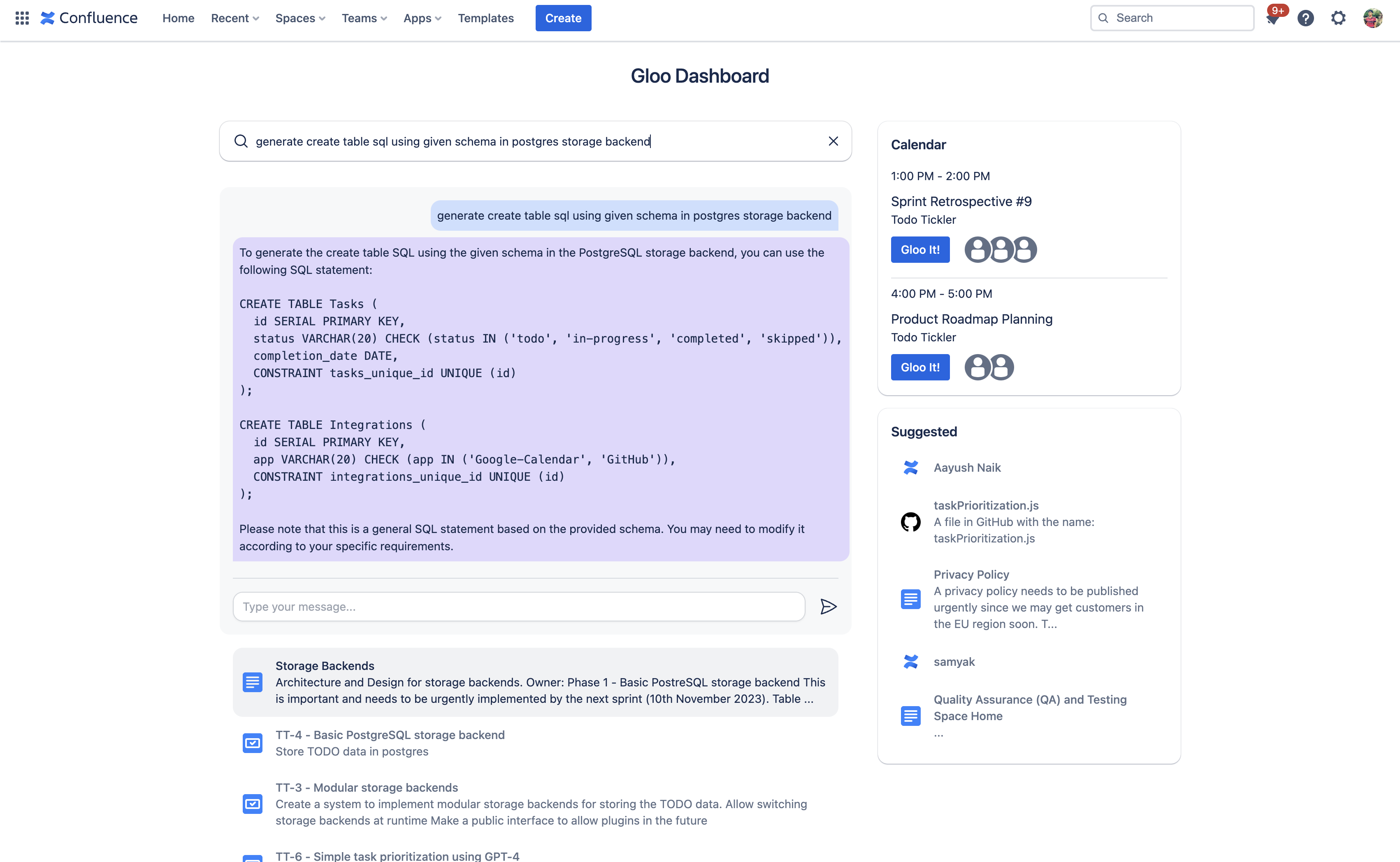
Generate code directly from your data!

Inspiration
Ever since our team started using tools like Jira, and Confluence, we realized that while these tools were powerful on their own, they lacked a seamless way to integrate with each other and provide contextual information. We often found ourselves hopping from one tool to another, trying to gather all the data we needed for a project. The idea for Gloo was born from this pain point: we wanted a unified interface that would glue these platforms together and provide actionable insights.
What it does
- 📄 Index all content across Jira, Confluence, GitHub and more.
- 🔎 Search across all your content instantly.
- 💬 Chat with your data: ask any question and refine with follow ups.
- 📃 Summarize large documents and issues quickly.
- 📅 Gloo it! - get all the information you need before a meeting.
- 🐛 Auto create issues! - describe a bug and Gloo will gather relevant information and if it can find the bug in your code, it will even provide you with a fix!
How we built it
To bring Gloo to life, we leveraged React for front-end development. By incorporating Atlassian's design components, Gloo's UI seamlessly integrates into the existing Atlassian ecosystem, offering users a touchpoint that feels familiar and intuitive, thereby reducing cognitive overload.
The Atlassian Forge platform played a pivotal role in our development process. It provided a robust foundation that allowed for secure, scalable, and efficient integration with Jira, and Confluence. With Forge's capabilities, we were able to implement queues and asynchronous API calls, facilitating parallel ingestion of data, and ensuring that projects and spaces could be indexed efficiently.
On the backend, we chose the Python FastAPI framework. This server allowed us to integrate with the llama_index library for efficient data indexing and LLM connection. To extract insights from the raw data, we used OpenAI to generate embeddings using the "text-embedding-ada-002" model. To store and query these embeddings, we used the Elasticsearch vector store. Since elasticsearch also has full text searches, it allowed Gloo to return results in real-time. For chat, we use the GPT-3.5-Turbo-16K model and for all other generative features we use the GPT-4 model.
Challenges we ran into
- Speeding up chat and other models: the default llama_index chat component made 4 calls to OpenAI for every message, leading to wait times of 30-40s per message. We cut down the number of GPT calls to 2 and along with some prompt engineering got down the response time to 5-10s (3-8x improvement). We are using a custom fork of llama_index to make this possible.
- Prompt engineering: it took many attempts to get the generative models (GPT-3.5 16k and GPT-4 in our case) to output good results taking into account the context and past history.
- Indexing data efficiently: getting different kinds of data (jira project, jira issue, github file, confluence page, etc.) into a common format and indexing them in parallel took some time to get right.
- Privacy and security: ensuring user data is segregated between accounts and not intermixed even with fuzzy searches and generative models.
- Integrating text, vector and chat searches from a common elasticsearch index was not very straightforward.
Accomplishments that we're proud of
- Getting the generative models to output mostly predictable and useful results.
- Response times of text and chat search, considering that the latter involves at least two GPT calls.
- End-to-end data ingestion: from the custom UI to the vector DB.
- Useful features and not just a chatbot over an index.
What we learned
- How to clean, store and index (mostly) unstructured data.
- Nuances of making generative AI models work for custom use cases, augmented with our own data.
What's next for Gloo
The most obvious improvement to Gloo is adding more data sources - slack, GitHub PRs/GitLab MRs, blog posts and many more. This will make the insights generated by Gloo even better.
There are many more places where AI can be used (along with the data) to streamline development processes and speed them up by many multiples. Some examples include: automatically generating summaries of issues fixed in a sprint, getting the code snippet to perform a particular action in a codebase (ex: "get an analytics database connection given user id") and adding relevant info + code to a Jira issue when it's opened.
On the backend, Gloo is yet to be scaled to support huge amounts of data, say thousands of issues or millions of lines of code.
Built With
- elasticsearch
- fastapi
- gpt
- llamaindex
- node.js
- openai
- python

Log in or sign up for Devpost to join the conversation.