-
-
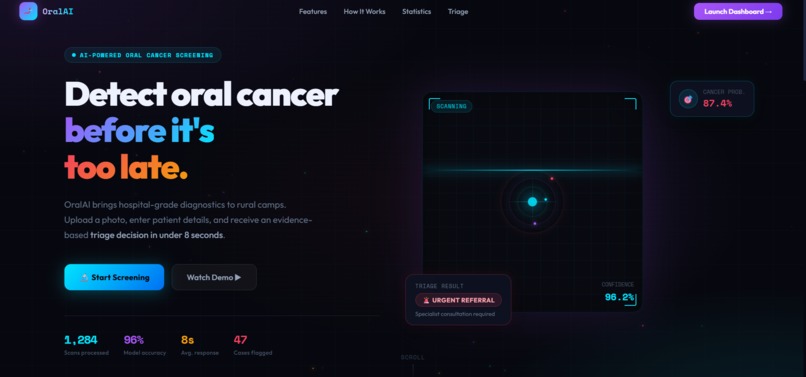
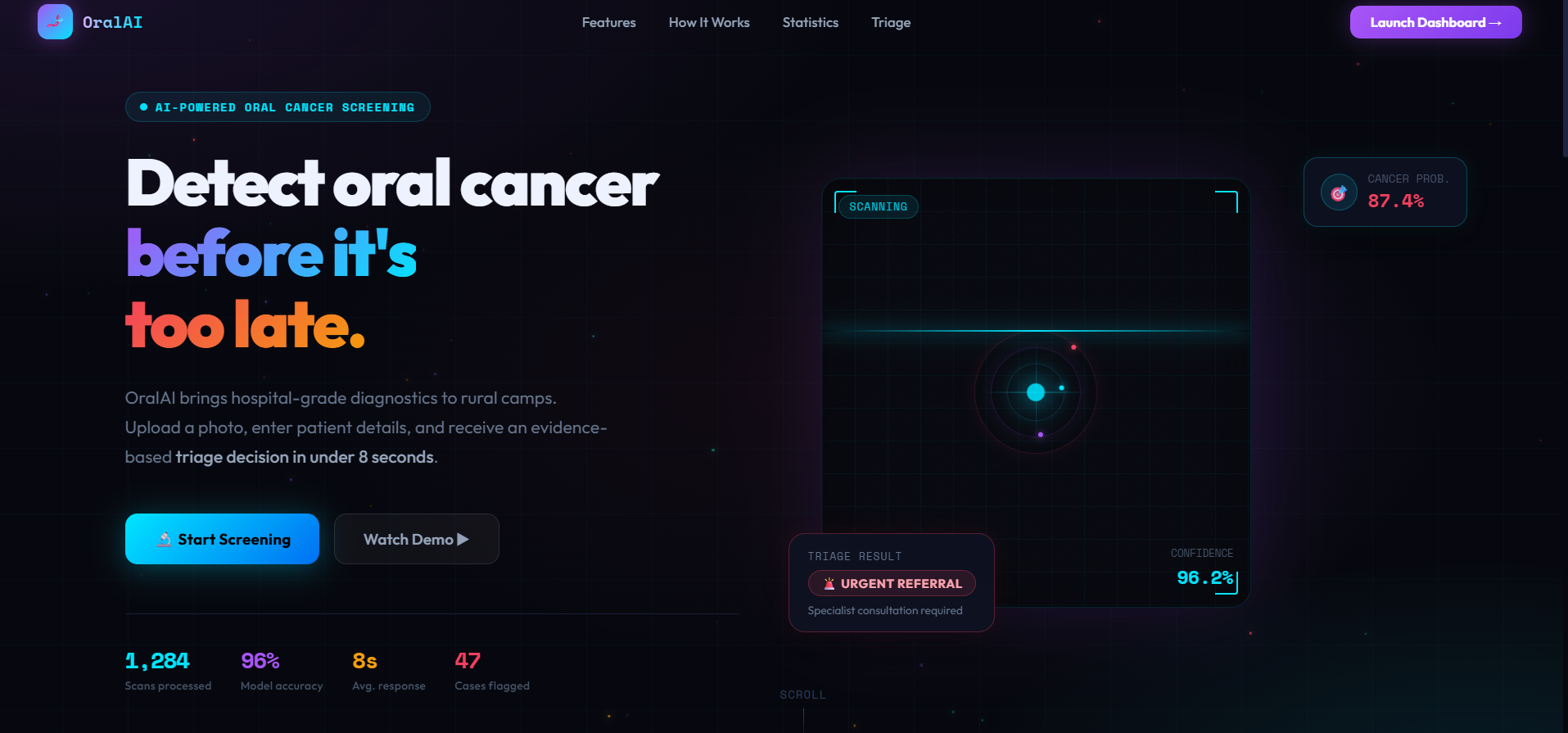
Landing Page
OralAI: Building an AI Triage Engine for Oral Cancer Screening in Rural India
🌱 Inspiration
Oral cancer is not a rare disease in India — it is an epidemic hiding in plain sight.
India accounts for nearly one-third of the world's oral cancer cases, driven by widespread tobacco chewing, gutka, and areca nut consumption deeply embedded in rural culture. The tragedy is not just the disease — it is when it is caught.
5-year survival rate at Stage I: ~80% 5-year survival rate at Stage IV: ~30%
That gap — 50 percentage points — is not a medical gap. It is a system gap.
Rural screening camps screen thousands of patients, but specialists travel hundreds of kilometres to perform manual visual inspections. The brutal reality:
- Only 5–10% of screened patients actually need specialist intervention
- Yet 100% of patients consume specialist time
- The system is not scalable, not sustainable, and not saving enough lives early
This inefficiency felt solvable. If AI could tell us — with confidence — which patients are low risk and which are urgent, specialists could focus exclusively on the cases that matter. That was the inspiration for OralAI.
🔨 How We Built It
OralAI is a full-stack AI system built across three layers.
1. The Deep Learning Core — EfficientNet
The image classification backbone is EfficientNetB0, trained using transfer learning on oral mucosa imagery. We chose EfficientNet specifically for its compound scaling formula:
$$d = \alpha^\phi, \quad w = \beta^\phi, \quad r = \gamma^\phi$$ $$\text{subject to} \quad \alpha \cdot \beta^2 \cdot \gamma^2 \approx 2, \quad \alpha \geq 1, \beta \geq 1, \gamma \geq 1$$
Where $d$, $w$, $r$ are depth, width, and resolution scaling coefficients — giving us state-of-the-art accuracy with far fewer parameters than ResNet or VGG.
Training used a two-phase strategy:
- Phase 1 (Feature Extraction): Backbone frozen, only classification head trained
- Phase 2 (Fine-tuning): Top 20 backbone layers unfrozen at learning rate $1 \times 10^{-5}$
The model outputs $P(\text{Normal} \mid \text{image})$, so:
$$P(\text{Cancer}) = 1 - P(\text{Normal} \mid \text{image})$$
2. The Risk Fusion Engine
OralAI doesn't rely on the image alone. Three independent signals are fused:
$$\text{Final Risk} = (0.60 \times P_{\text{image}}) + (0.25 \times S_{\text{lifestyle}}) + (0.15 \times S_{\text{symptom}})$$
Lifestyle Risk Score $S_{\text{lifestyle}}$ is computed as:
$$S_{\text{lifestyle}} = \frac{(40 \cdot \mathbb{1}{\text{age}>40}) + (30 \cdot \mathbb{1}{\text{tobacco}}) + (20 \cdot \mathbb{1}{\text{alcohol}}) + (10 \cdot \mathbb{1}{\text{lesion}>14d})}{100}$$
This deterministic, rule-based component is fully auditable — any health worker can trace exactly why a score was computed the way it was.
Symptom Risk Score $S_{\text{symptom}}$ is only activated for URGENT REFERRAL
cases via a secondary clinical questionnaire:
| Symptom | Weight |
|---|---|
| Pain present | $+0.20$ |
| Bleeding from lesion | $+0.25$ |
| Difficulty swallowing | $+0.20$ |
| Unexplained weight loss | $+0.15$ |
| Lymph node swelling | $+0.20$ |
3. Triage Classification
The Final Risk Score maps to one of four clinical triage levels:
| Level | Threshold | Action |
|---|---|---|
| 🚨 URGENT REFERRAL | $\geq 75\%$ | Immediate specialist + Advanced Diagnosis |
| ⚠️ HIGH RISK | $\geq 50\%$ | Schedule at next camp |
| 🟣 MODERATE RISK | $\geq 30\%$ | Follow-up in 30 days |
| ✅ LOW RISK | $< 30\%$ | Routine annual screening |
4. The Stack
- Backend: Python + Flask + TensorFlow/Keras
- Frontend: React 18 + Framer Motion
- PDF Generation: jsPDF (entirely client-side — zero patient data stored on server)
- Model: EfficientNetB0 serialised to
.kerasformat
📚 What We Learned
1. Multi-modal fusion beats single-modality classifiers in the real world. Image quality in rural field settings is inconsistent — poor lighting, angle variation, motion blur. A pure image classifier breaks under these conditions. Fusing it with structured lifestyle data that is immune to image quality made the system dramatically more robust.
2. Threshold design is a clinical decision, not a technical one.
Setting the URGENT REFERRAL threshold at 75% wasn't arbitrary. We calibrated
it against the principle that:
$$\text{Cost}(\text{False Negative}) \gg \text{Cost}(\text{False Positive})$$
A missed cancer is catastrophically worse than an unnecessary referral. This forced us to think like clinicians, not just engineers.
3. Interpretability matters as much as accuracy. A 96.2% accurate black box is useless if a health worker can't explain to a patient why they are being referred. The weighted fusion formula — where every component is visible and auditable — was a deliberate design choice to make every triage decision explainable.
4. Client-side PDF generation is a privacy architecture decision. Choosing jsPDF over server-side rendering wasn't about convenience. It meant that patient oral images are never stored, never logged, and never transmitted beyond the inference call. In a healthcare context, data minimisation is an ethical obligation.
🧱 Challenges We Faced
Challenge 1: Limited labelled oral cancer image data Oral cancer datasets are small by deep learning standards. We addressed this through aggressive data augmentation (flipping, rotation, brightness jitter, zoom) and transfer learning from ImageNet — letting the model leverage low-level visual features learned on millions of general images before adapting to oral tissue morphology.
Challenge 2: Balancing sensitivity and specificity Early threshold configurations produced either too many false-positive urgent referrals (wasting specialist time) or too many false negatives (missing malignancies). Finding the operating point that satisfied both constraints required iterative calibration against the validation set.
Challenge 3: Designing for health workers, not doctors The system had to be operable by a community health worker with minimal technical training. This meant every interface decision — from the four-level triage label to the one-tap PDF download — had to prioritise clarity over clinical sophistication.
Challenge 4: Making the Advanced Diagnosis gate meaningful
The secondary symptom questionnaire needed to be gated correctly. Showing it
to all patients would create fatigue and slow down high-volume camps. Restricting
it to URGENT REFERRAL cases only ensured it added maximum diagnostic value
precisely where it was needed — without burdening the 80%+ of patients who
are correctly filtered as low risk.
🚀 What's Next
- 📱 Flutter mobile app with offline inference for zero-connectivity rural settings
- 🔬 Multi-class lesion detection: leukoplakia, erythroplakia, OSMF
- 🏛️ API integration with Ayushman Bharat Digital Mission (ABDM)
- 🔄 Longitudinal patient tracking across multiple screening visits
- 🗣️ Multilingual UI: Marathi, Hindi, Tamil for field workers
OralAI is not a finished product. It is a proof that AI-first rural cancer screening is technically feasible, clinically meaningful, and operationally deployable — today.

Log in or sign up for Devpost to join the conversation.