Inspiration
What it does
How we built it
Challenges we ran into
Accomplishments that we're proud of
What we learned
What's next for OptiCV
What Inspired Me: The inspiration for this project came from the growing need for smarter, AI-driven solutions in managing and retrieving large amounts of unstructured data. With advancements in technologies like LangChain and Gemini, I saw an opportunity to build a system that seamlessly integrates cutting-edge AI models with robust database solutions like Pinecone to enable efficient Retrieval-Augmented Generation (RAG). My goal was to create a powerful tool that leverages these technologies to enhance information accessibility and accuracy.
What I Learned: This project was a deep dive into modern AI and full-stack web development. I gained hands-on experience with:
Next.js: Building efficient and server-rendered web applications for optimal performance.
LangChain: Implementing modular pipelines for handling conversational AI and chaining large language models effectively.
Hugging Face Models: Deploying and fine-tuning pre-trained transformer models for specific tasks like question answering and summarization.
Pinecone Database: Utilizing a vector database for semantic search and similarity matching, crucial for RAG systems.
Gemini Integration: Combining advanced AI capabilities with RAG workflows to improve user interactions and generate contextually relevant responses.
Additionally, I learned how to orchestrate these tools together to create a scalable and user-friendly solution.
How I Built the Project:
Frontend: I developed the frontend using Next.js for its server-side rendering capabilities and its ability to create a seamless user experience.
Backend Logic: The backend incorporated LangChain to chain various steps of the AI pipeline, like data ingestion, query processing, and response generation.
Model Deployment: I integrated Hugging Face's transformer models via APIs for natural language understanding and generation tasks.
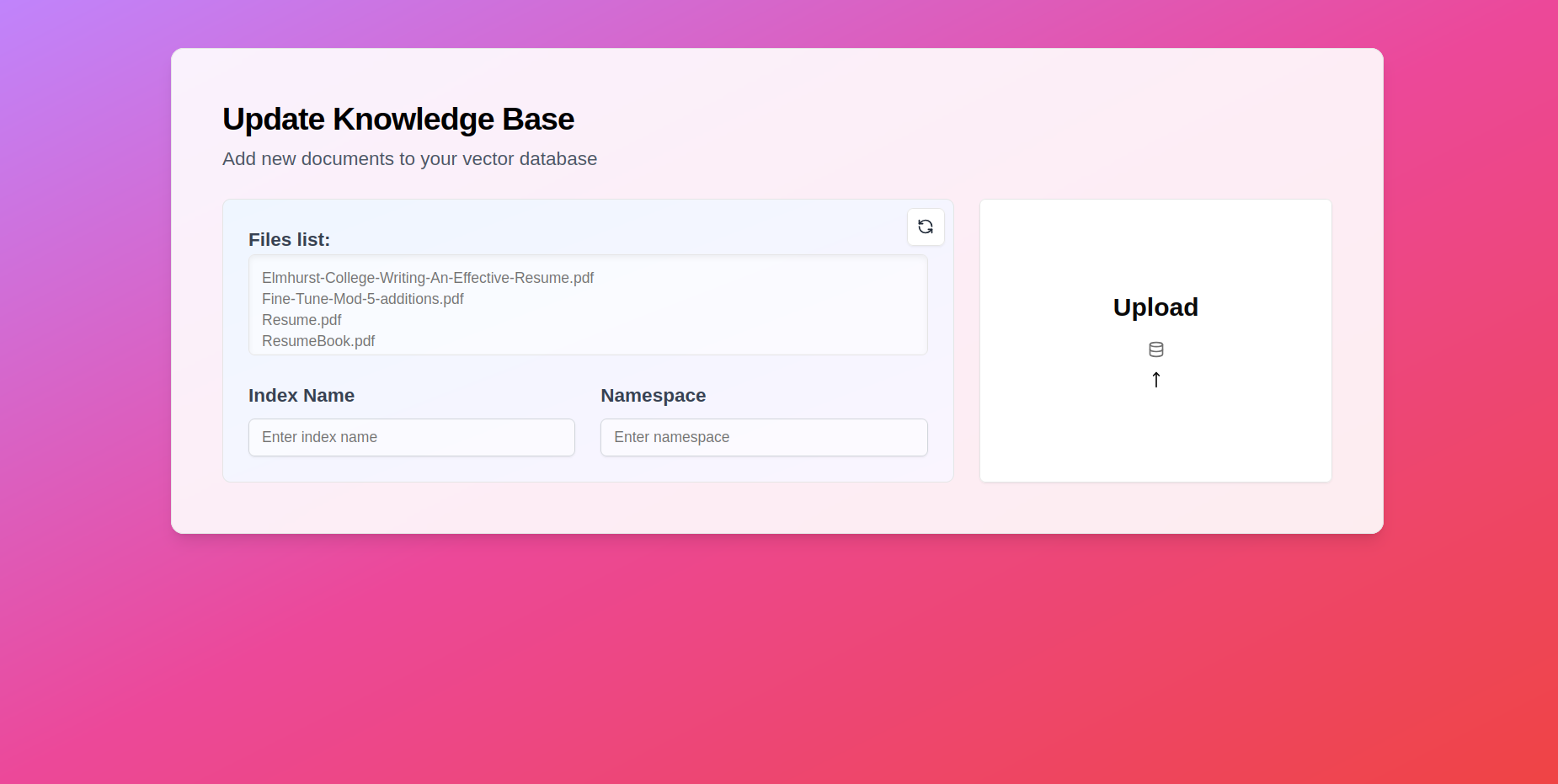
Database: Pinecone was used to store and retrieve vector embeddings for efficient document retrieval during the RAG process.
Gemini Integration: Gemini acted as the overarching AI system, enhancing the quality of responses with its cutting-edge model capabilities.
Workflow: The RAG pipeline combined Pinecone for document retrieval, LangChain for chaining tasks, and Gemini for generating highly relevant and contextual answers.
Challenges I Faced:
Integration Complexity: Combining multiple technologies (Next.js, LangChain, Hugging Face, Pinecone, Gemini) required a deep understanding of their APIs and workflows.
Latency Issues: Ensuring low-latency responses in RAG required optimizations in embedding generation and vector search.
Model Fine-Tuning: Adapting Hugging Face models to specific use cases involved significant experimentation and computational resources.
Scalability: Managing Pinecone's vector database for large-scale queries while keeping it performant was challenging.
Context Management: Handling and maintaining context in multi-turn conversations without compromising relevance was another intricate problem.
Built With
- huggingface
- langchain
- next.js
- pinecone


Log in or sign up for Devpost to join the conversation.