-
-

Landing Page
-
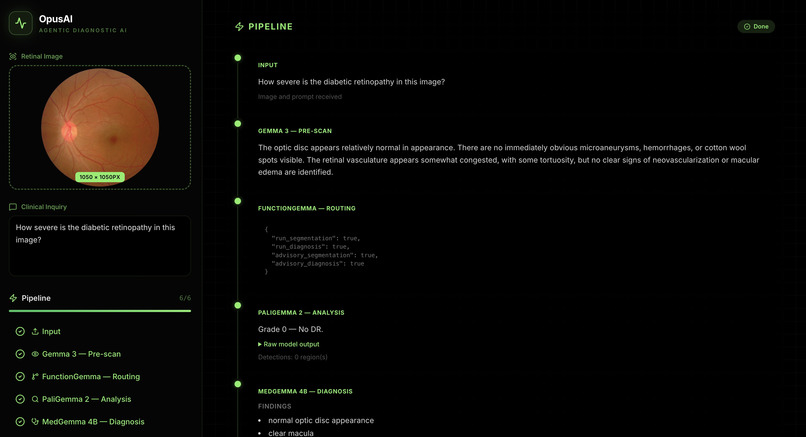
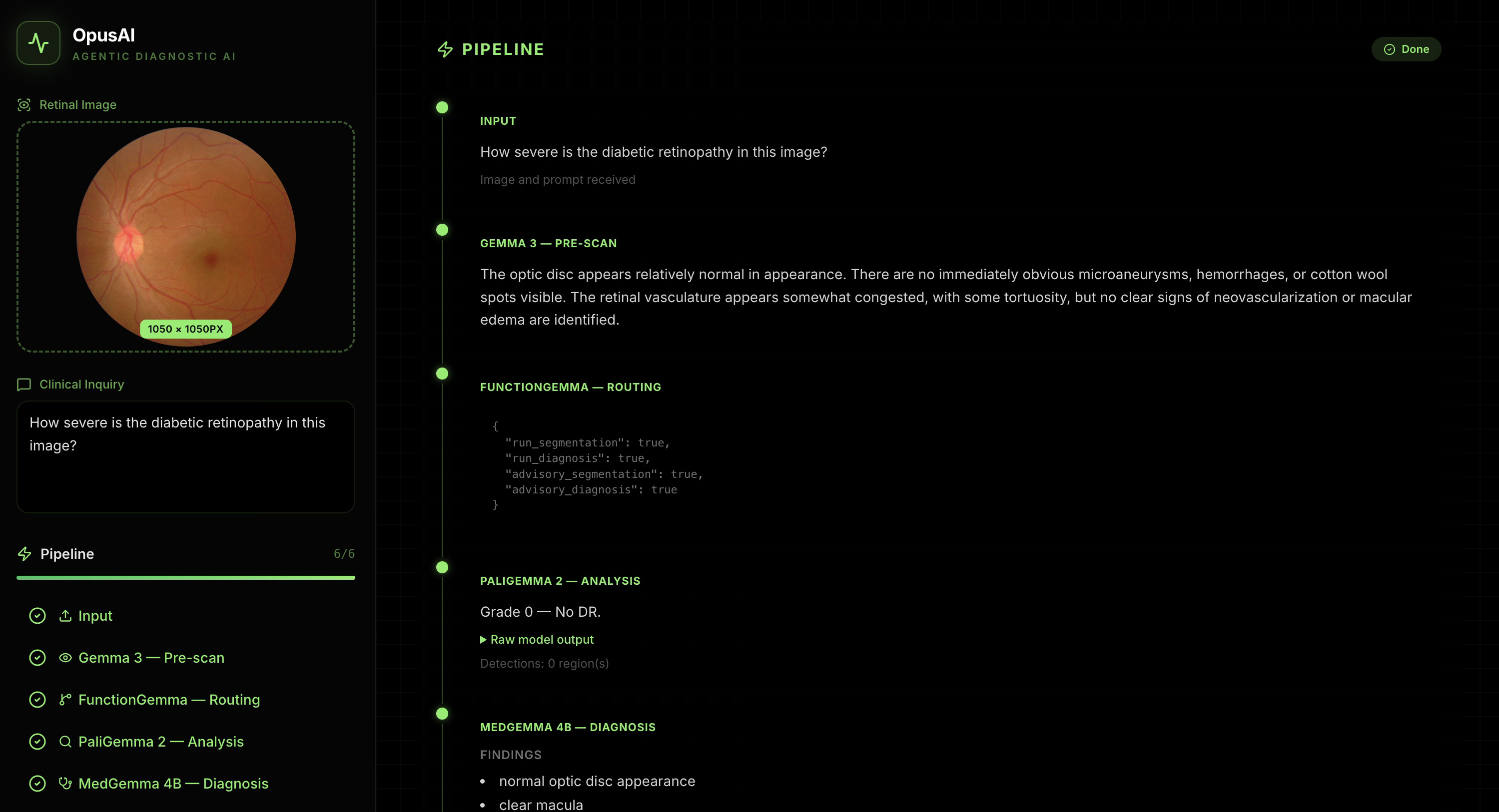
Dashboard for Fundus Image Reasoning for Ophthalmologist
-
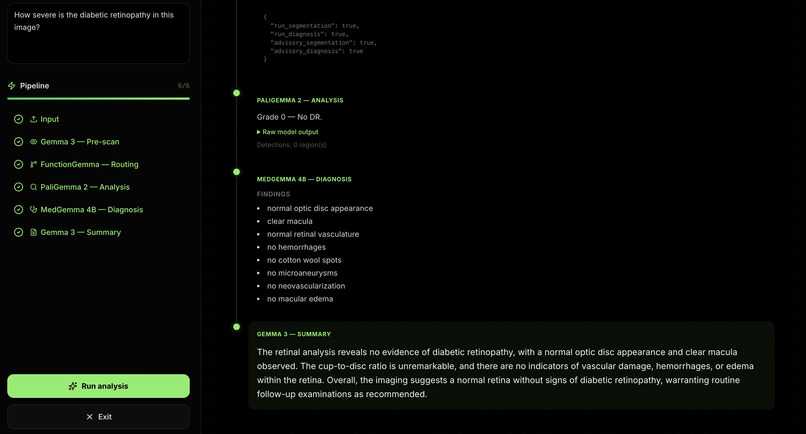
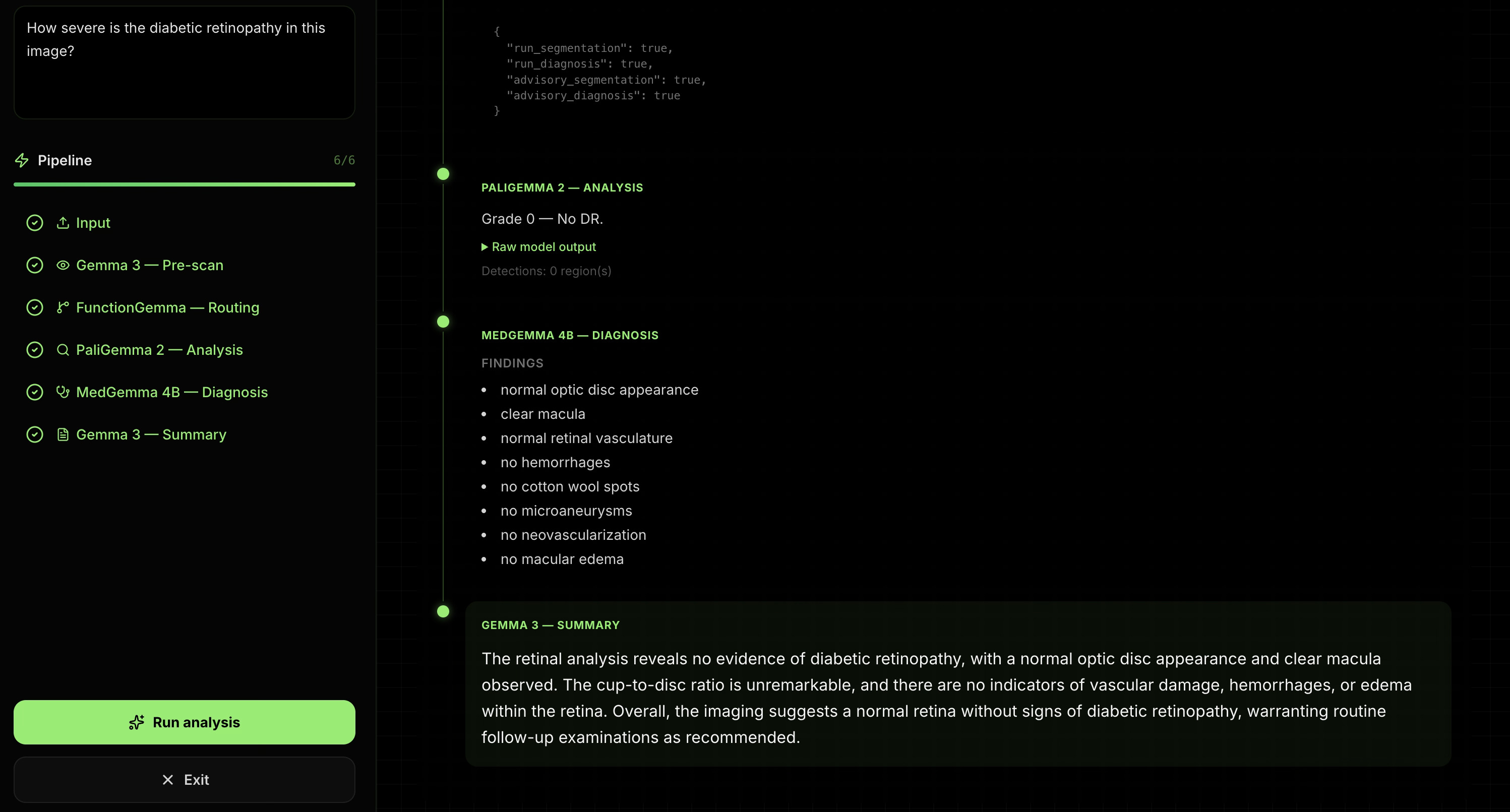
Summary of image and QA

Inspiration
Eye care generates huge amounts of imaging data fundus photos, follow-up series, screening backlogs. Clinicians and engineers both feel the same tension: you want intelligent help at the point of care, but patient images are sensitive. Sending every scan to a generic cloud API is often unacceptable for policy, trust, and latency not because teams dislike AI, but because they need control over where data lives and which models run. We were inspired by the idea of a transparent, staged workflow: not one black-box answer, but a pipeline that looks like a careful read quick context, a decision about what to run, specialized vision, structured medical reasoning, and a final narrative while staying hostable on your own machines when you want that.
What it does
OpusAI takes a retinal fundus image plus a clinical question and runs a six-stage pipeline: Input — Accept image and prompt. Gemma 3 (pre-scan) — Short visual description of the fundus. FunctionGemma (routing) — Tool-style orchestration to decide how to proceed (e.g. segmentation vs. diagnosis paths). PaliGemma 2 — Retinal-focused vision analysis (e.g. grading / localization-style outputs, depending on your server and prompts). MedGemma 4B — Structured diagnosis-style output (e.g. findings list) for downstream display and summary. Gemma 3 (synthesis) — One consolidated clinical-style narrative across prior stages. The dashboard streams Server-Sent Events (SSE) so users see which step is running, interim “thinking,” and then step-level results not only a final blob of text.
How we built it
Backend: FastAPI (POST /api/analyze) orchestrates async calls to Ollama (Gemma 3, FunctionGemma, MedGemma by default) and an HTTP service for PaliGemma. Configuration is environment-driven (URLs, model names, full-pipeline vs. route-gated behavior) so one codebase can target laptop, workstation, or optional remote inference. Frontend: React, TypeScript, Vite, Tailwind—a focused OpusAI UI that consumes the SSE stream and shows a vertical pipeline timeline. Models: We leaned on Google’s Gemma family and MedGemma for text + multimodal chat patterns, and PaliGemma for fundus-specific vision, connected through small, explicit contracts between stages (what text from pre-scan and PaliGemma is passed into MedGemma and into the final merger). If you want to express “confidence” as a scalar in docs or slides, a simple normalized score is just c∈[0,1]; severity or grading can be treated as an ordinal label on top of that—useful when explaining calibration vs. clinical ground truth to judges or clinicians.
Challenges we ran into
Multimodal inference on Apple Silicon — Some MPS paths misbehaved with vision-language stacks; we defaulted to safer device choices and made overrides explicit via env vars. Small-model routing — FunctionGemma sometimes answered in prose instead of calling tools; we tightened prompts and nudges so the loop stays tool-first for reliable orchestration. JSON from local LLMs — MedGemma outputs had to be parsed robustly (fences, partial JSON, extra text). UX truthfulness — Showing “thinking” without cluttering the final view required clear state rules (running vs. complete, what persists in the timeline).
Accomplishments that we're proud of
A clear, inspectable pipeline end users can follow stage by stage. Local-first defaults via Ollama so demos and deployments can avoid shipping images to arbitrary third-party APIs. A single orchestrator that still allows swap-in servers (PaliGemma HTTP, optional HF/Modal-style MedGemma) without rewriting the app. Streaming UX that makes long multimodal runs feel alive and debuggable, not opaque.
What we learned
Orchestration beats one giant prompt each stage has a job; the hard part is interfaces (what context to pass forward). Reliability is a product feature parsing, retries, and sane fallbacks matter as much as model choice. Privacy and speed are design constraints, not afterthoughts: where models run and how data moves should be first-class in the architecture, not only in the Terms of Service.
What's next for OpusAI
Stronger evaluation — Curated fundus benchmarks, explicit reporting of limitations and failure modes. DICOM / workflow hooks — Deeper integration with imaging pipelines and audit logs. Calibration and safety UX — Clearer handling of uncertainty (when to show c vs. when to refuse a single label). Deployment packs — One-command local bundles (Ollama + services + env templates) for reproducible demos and pilot sites.
Built With
- fastapi
- finetuning
- functiongemma
- gemma
- gemma3
- hugging-face
- lora
- lucidereact
- medgemma
- ollama
- paligemma
- peft
- pilllow
- postgresql
- python
- pytorch
- qlora
- react
- sft
- sse
- supabase
- tailwindcss
- three.js
- typescript


Log in or sign up for Devpost to join the conversation.