-
-
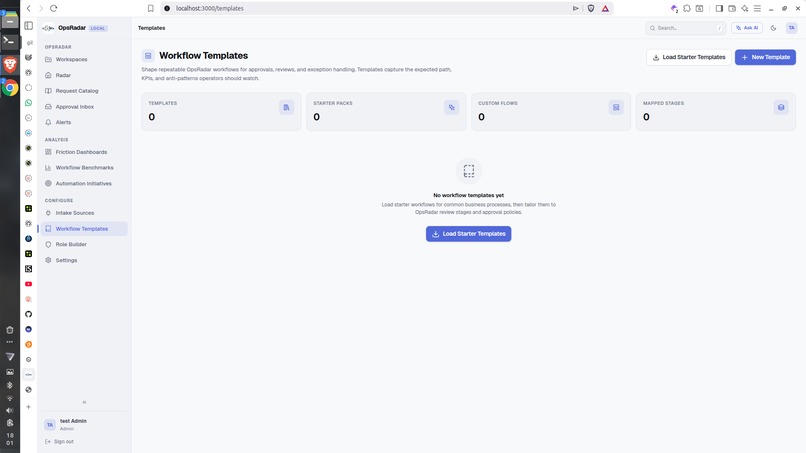
Workflow Templates
-
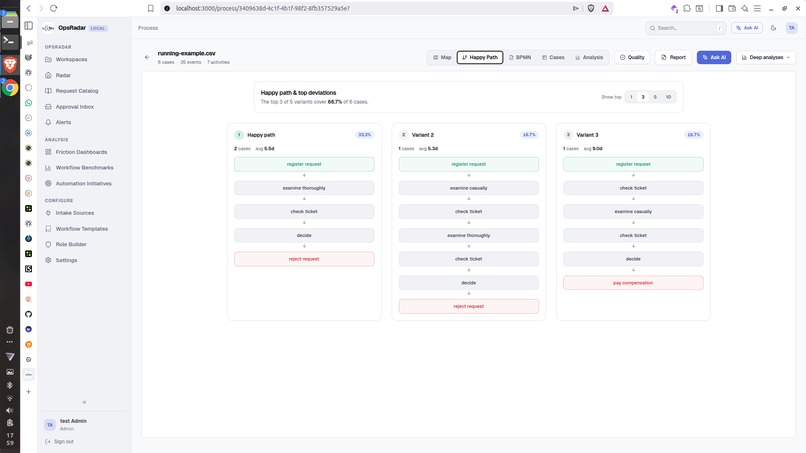
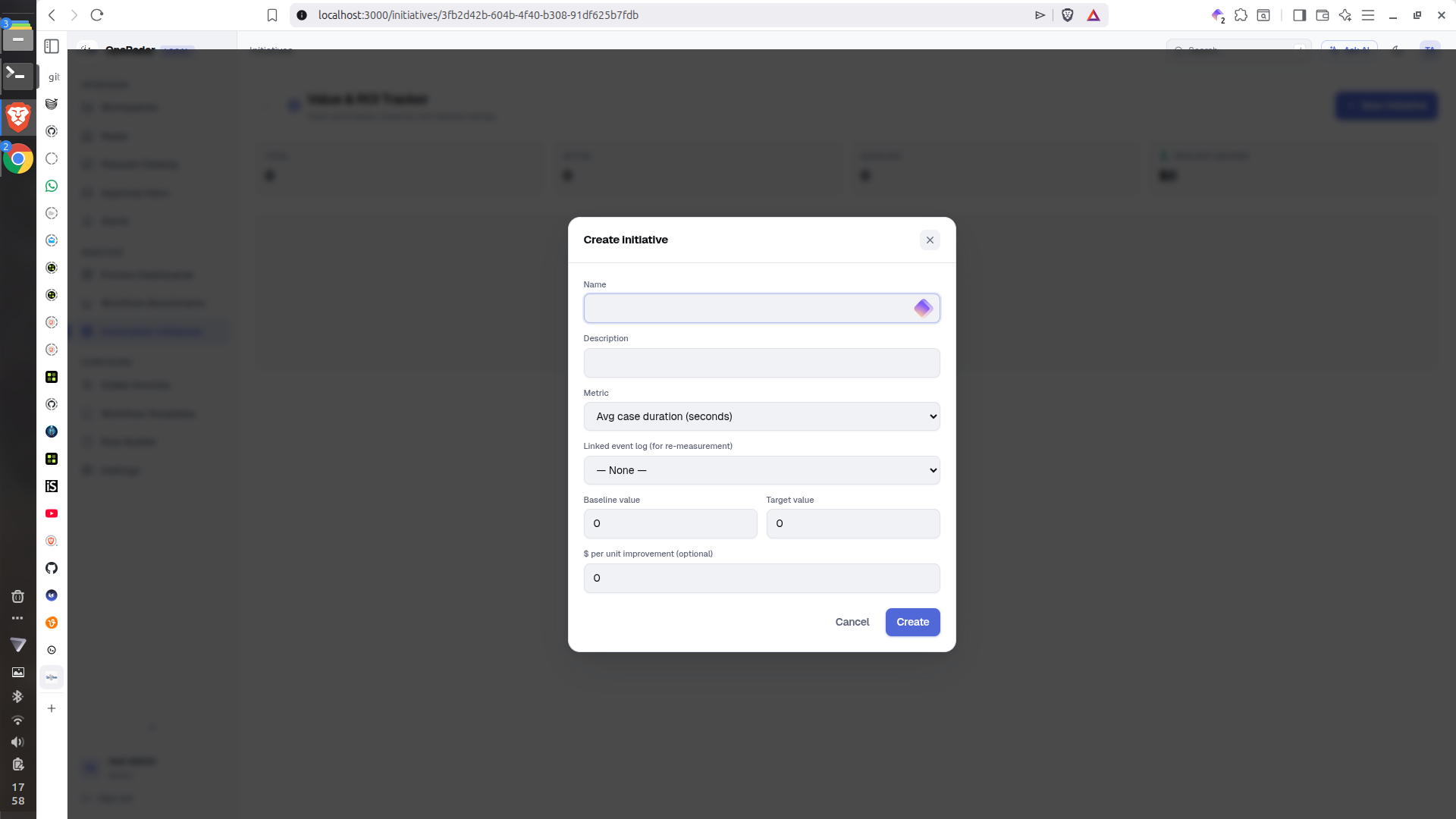
Governance View
-
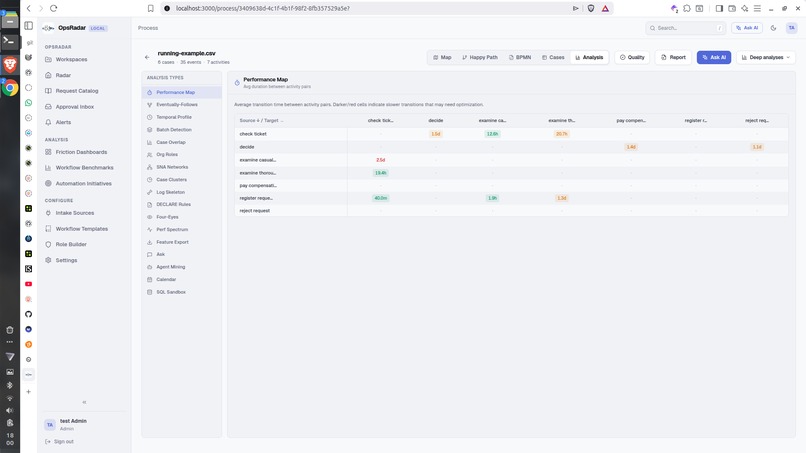
Dashboard Details
-
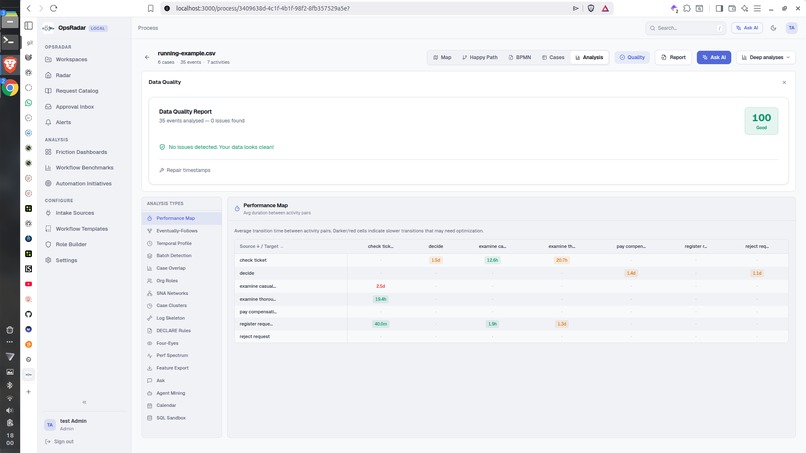
Operation CockPit
-
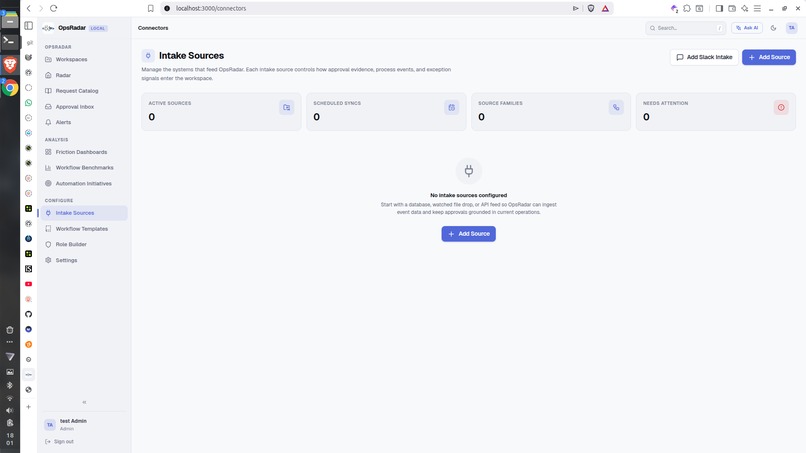
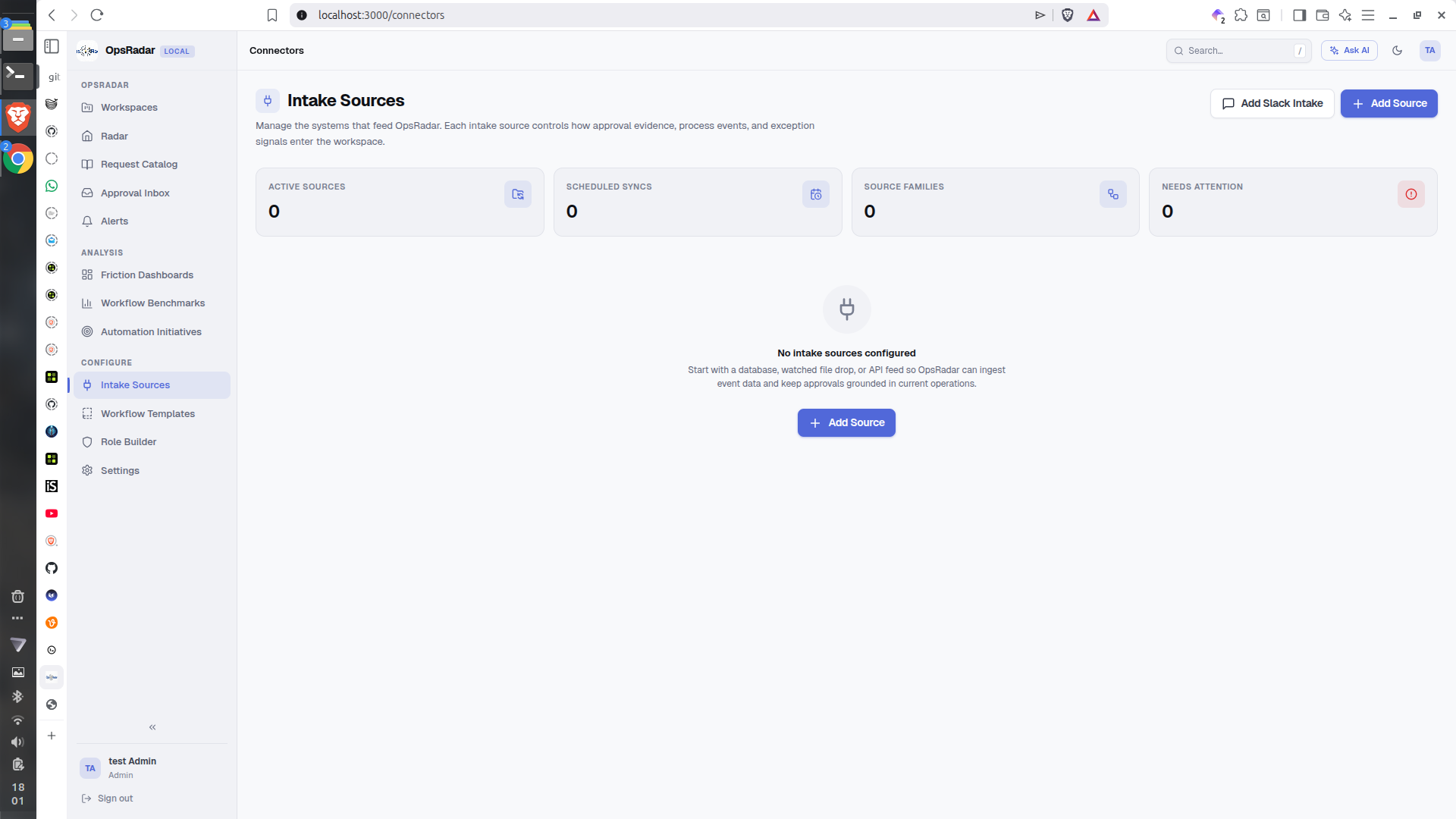
Intake Source Config
-
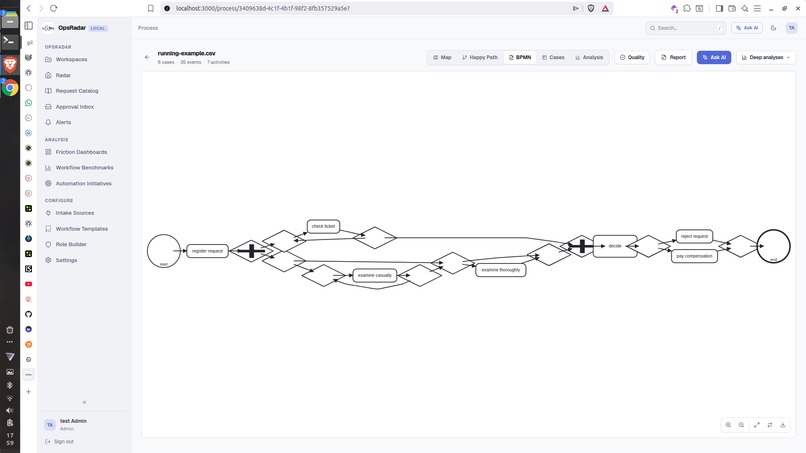
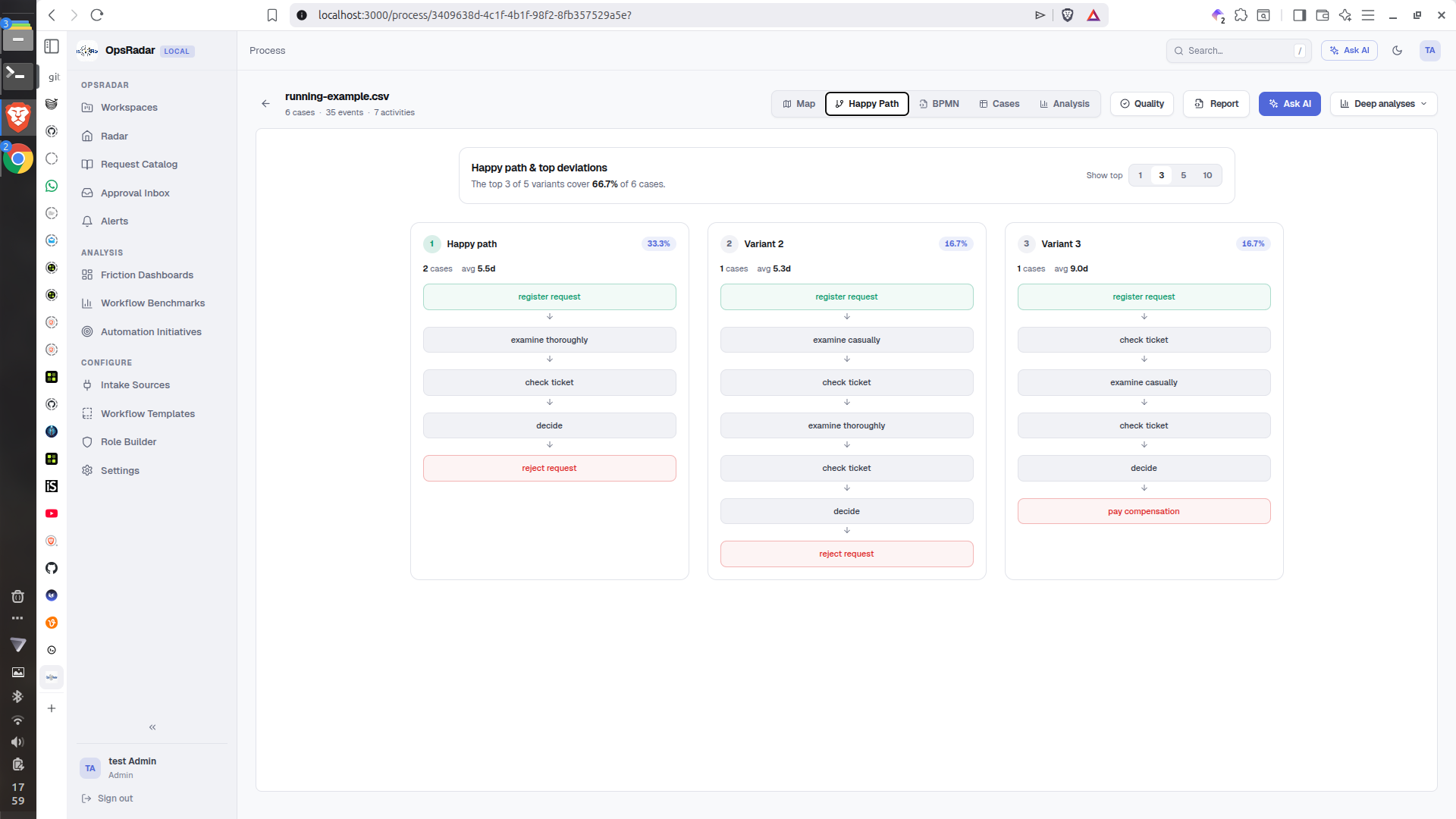
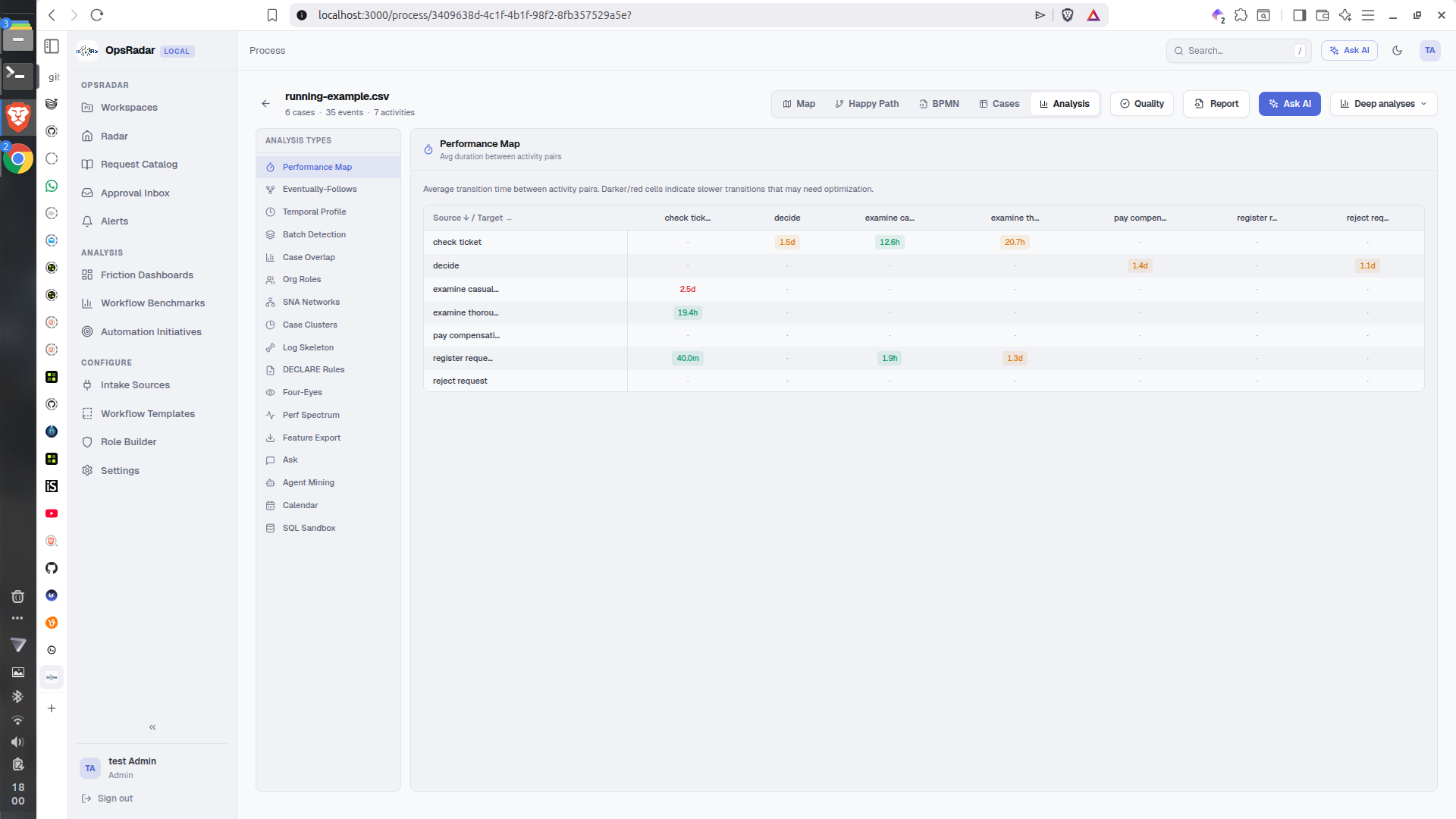
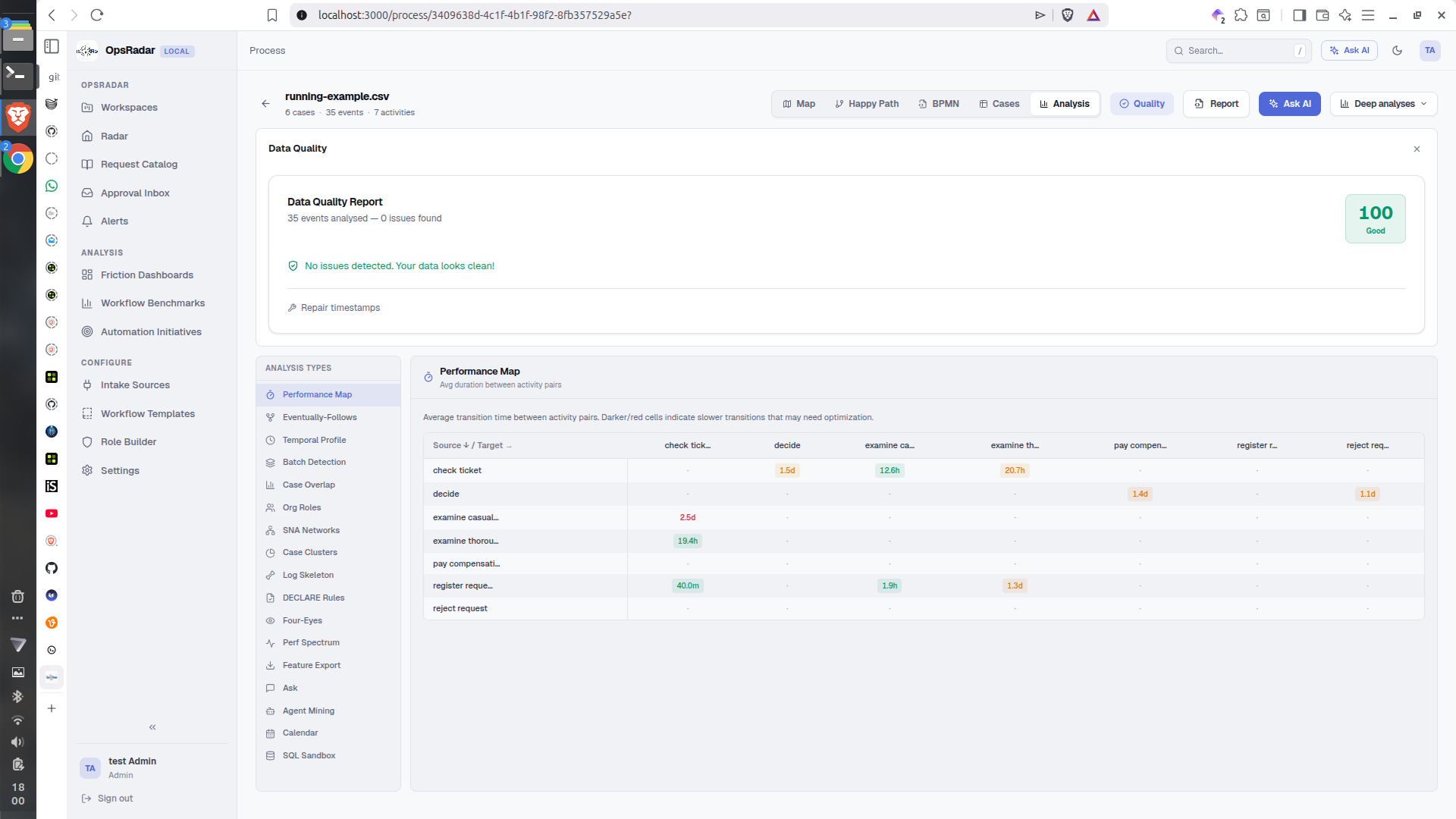
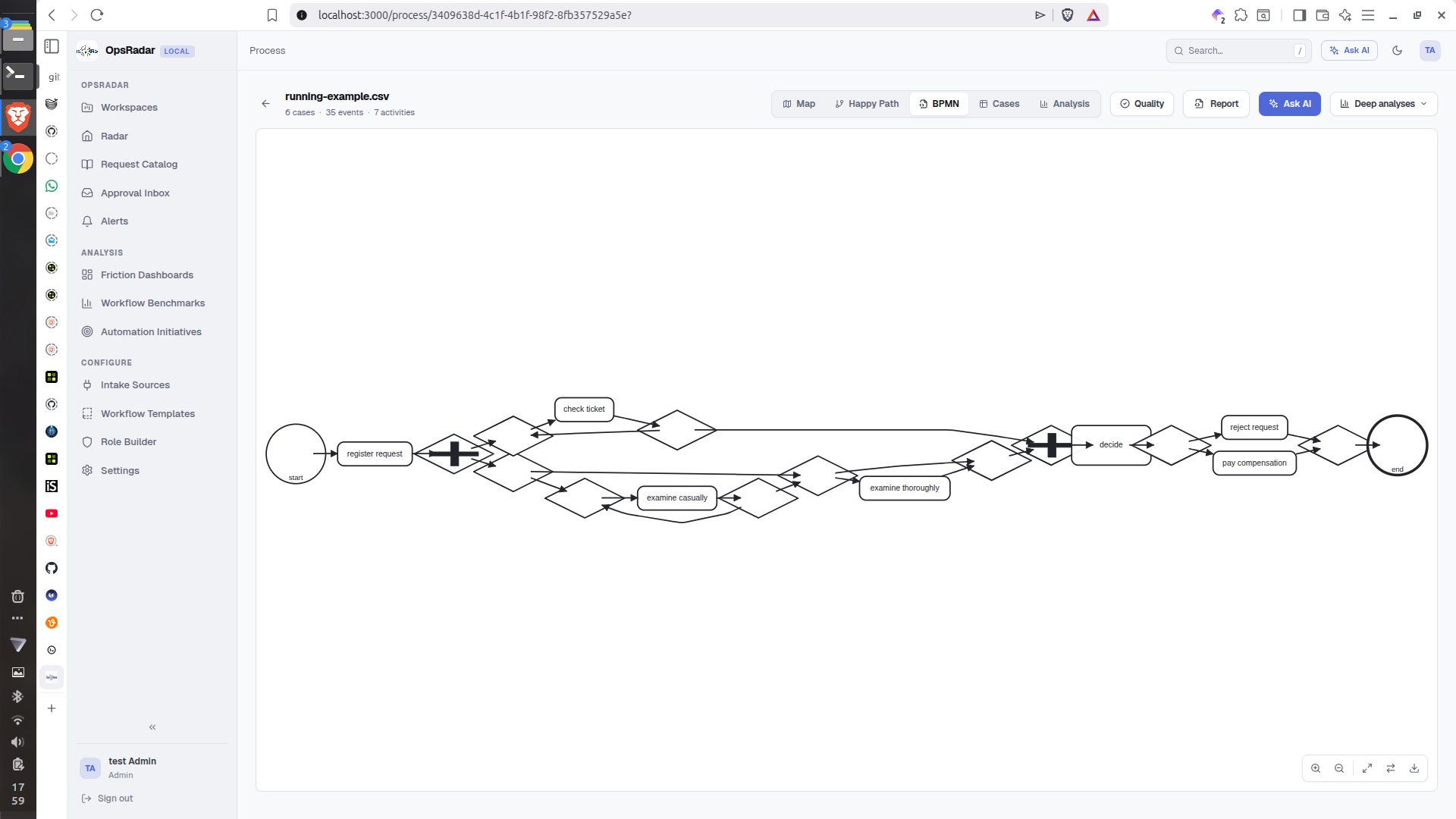
Process-Graph
-
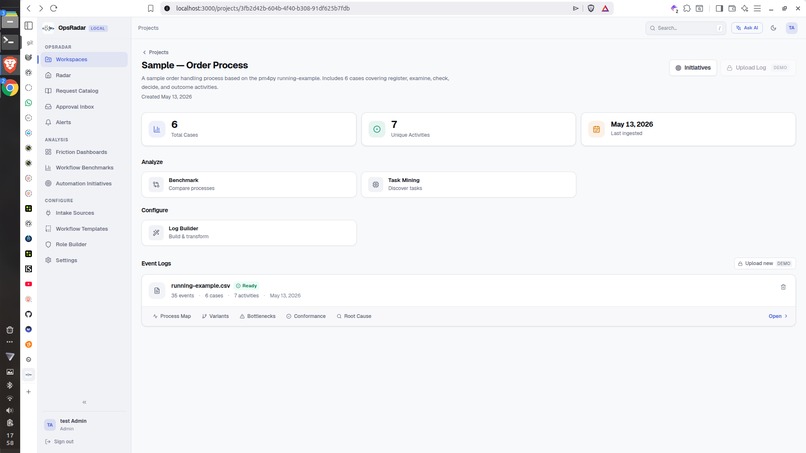
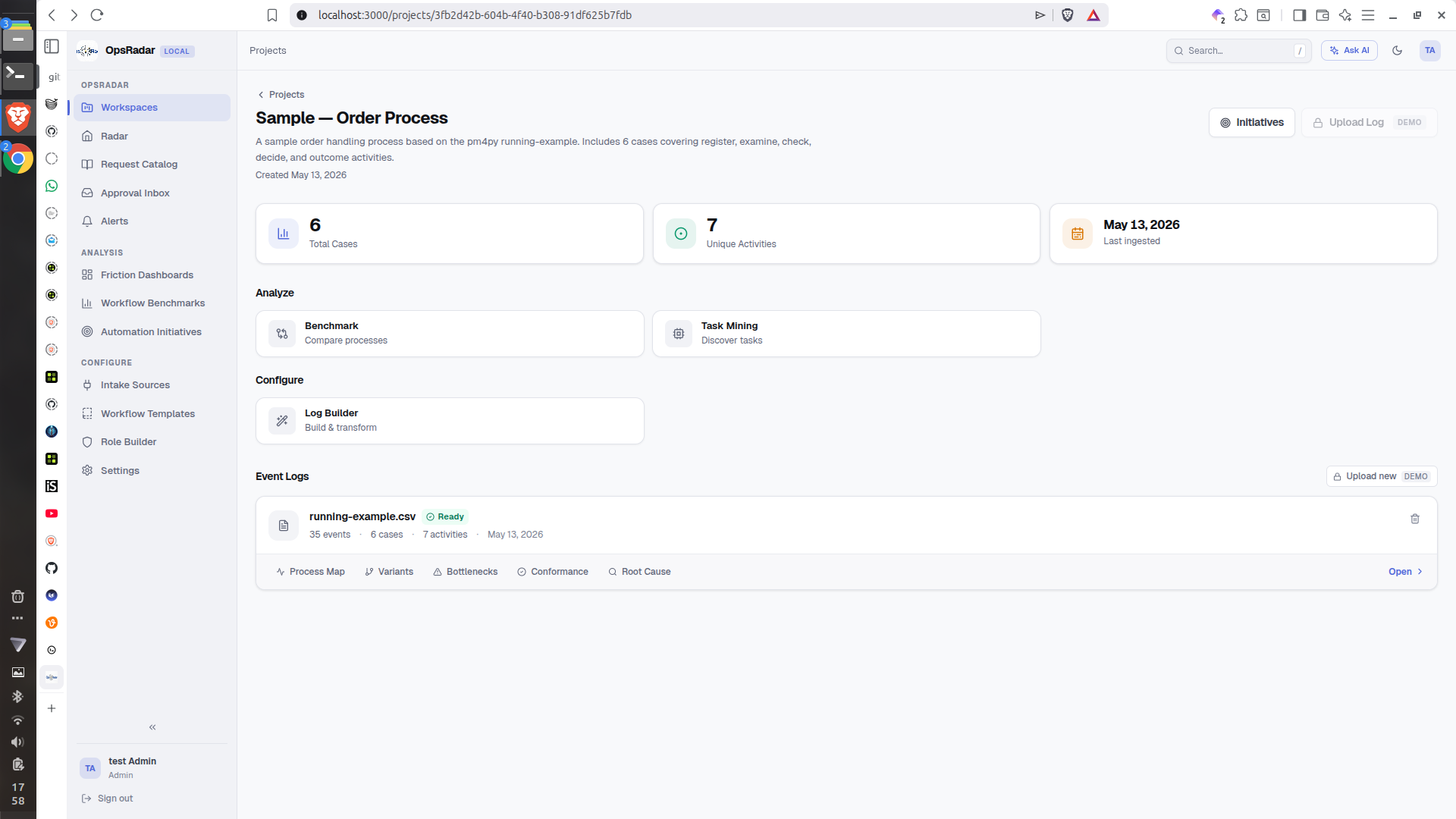
Workspace/Project- Overview
-
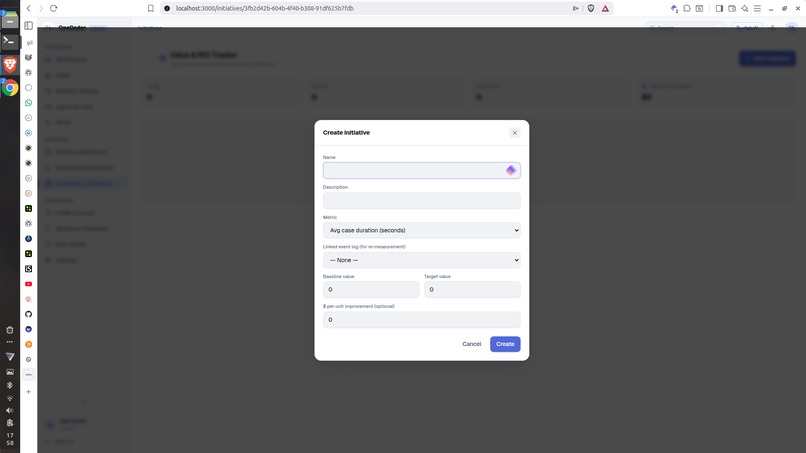
Request launch-Flow
Inspiration
OpsRadar was inspired by a common internal operations problem: simple requests often get scattered across Slack, Jira, email, and someone’s memory.
A tool access request might start as a Slack message, become a ticket, get approved in a reply thread, and then sit in an IT admin’s mental to-do list. The work may eventually get done, but nobody can confidently answer:
- Who owns the next step?
- Is the approval overdue?
- Was this request already made?
- Who approved access, when, and why?
- How much time are we losing to manual follow-up?
The problem is not that companies lack tools. The problem is that internal work falls between the tools.
OpsRadar was built to fix that coordination failure.
What it does
OpsRadar is an internal request coordination system. It turns scattered internal requests into structured, trackable workflows with:
- controlled request intake
- duplicate request detection
- role-based approval routing
- approval inbox
- request comments
- request-more-info flow
- simulated fulfillment
- audit timeline
- friction metrics
For the demo, we focused on access requests. A requester can submit a structured access request, OpsRadar checks for duplicates, routes it to the right approver, records the decision, creates a fulfillment task, simulates the access grant, and stores every step in an audit-friendly timeline.
The goal is simple:
One record. One owner. One status. One audit trail.
Business impact
OpsRadar improves operational efficiency by reducing time lost to manual coordination, duplicate requests, unclear ownership, approval chasing, and audit reconstruction.
A conservative estimate:
$$ 200 \text{ requests/month} \times 15 \text{ minutes saved/request} = 3000 \text{ minutes/month} $$
$$ 3000 \div 60 = 50 \text{ hours saved/month} $$
At an estimated fully-loaded internal cost of $50/hour:
$$ 50 \times 50 = 2500 $$
That is about $2,500/month, or roughly $30,000/year, in avoidable coordination cost.
This estimate only counts saved follow-up time. It does not include the extra value from faster onboarding, fewer dropped requests, better compliance, and easier audits.
How we built it
OpsRadar was built by adapting an open-source process and operations dashboard foundation into a focused internal request coordination product.
We added OpsRadar-specific product surfaces such as:
- Request Catalog
- Approval Inbox
- Intake Sources
- Workflow Templates
- Role Builder
- Friction Dashboards
On the backend, we implemented a request lifecycle with database-backed records for:
- operational requests
- approvals
- request events
- comments
- policy results
- fulfillment tasks
- simulated access grants
- notifications
- audit logs
The main demo lifecycle is:
Request created
→ Duplicate check
→ Policy/routing evaluation
→ Approval assigned
→ Approval decision
→ Fulfillment task created
→ Simulated access grant
→ Request completed
→ Audit timeline updated
We intentionally avoided arbitrary Slack message parsing. Instead, OpsRadar uses controlled intake through structured forms, configured intake sources, and Slack-style structured intake. This makes the tool more practical, safer, and easier to adopt in a real company.
We also started preparing OpsReader, the MCP-facing layer for OpsRadar, so AI clients can eventually inspect request state, blockers, owners, and audit history through authenticated context.
Challenges we faced
One challenge was keeping the scope practical. It would be easy to try to build a full ServiceNow or Jira replacement, but that is too large for a hackathon. We narrowed the project to one high-value workflow: internal access requests.
Another challenge was avoiding noisy automation. Parsing every Slack message would create privacy issues and unnecessary noise, so we designed controlled intake instead.
We also had to balance demo value with feasibility. Real Google Workspace, Okta, or Figma provisioning would be useful, but integrating every vendor API would distract from proving the core workflow. For the prototype, fulfillment is simulated so the end-to-end lifecycle can be demonstrated clearly.
What we learned
We learned that the highest-impact internal tools are often not flashy. They solve the boring coordination problems that waste hours every week.
The biggest lesson was that internal operations need more than dashboards. Teams need systems of record that track ownership, status, decisions, and audit history.
OpsRadar shows that even a lightweight internal tool can create meaningful business value when it reduces repeated follow-up, unclear approvals, and manual status chasing.
What is next
Next steps include:
- deeper Slack modal integration
- stronger SLA and escalation workflows
- real provisioning connectors for Google Workspace, Okta, GitHub, or Figma
- more notification channels
- expanded OpsReader MCP tools
- dashboard write-back tools such as filters, case tags, and saved views
- production hardening for authentication, authorization, and deployment
GitHub Repository:
https://github.com/Absolute-Martial/Ops-Radar
Demo Video:
https://youtu.be/9yXHIVRc40c
There is no deployment yet so
Live Demo:
Available through local Docker Compose setup in the GitHub repository.
as of Now the deployment done sucessfully so to
https://opsradar-hackathon.susankshakya.com.np/login
and
Credentials:
Email: clamp-hug-majestic@duck.com
Passwd : AdminPass@123!
Built With
- actions
- alembic
- api
- authentication
- casbin
- celery
- compose
- context
- docker
- excalidraw
- fastapi
- github
- jwt
- mcp
- mkdocs
- model
- novu
- postgresql
- protocol
- python
- react
- redis
- slack
- sqlalchemy
- temporal
- typescript
- vite


Log in or sign up for Devpost to join the conversation.