Inspiration
It started with a number: $460,000,000.
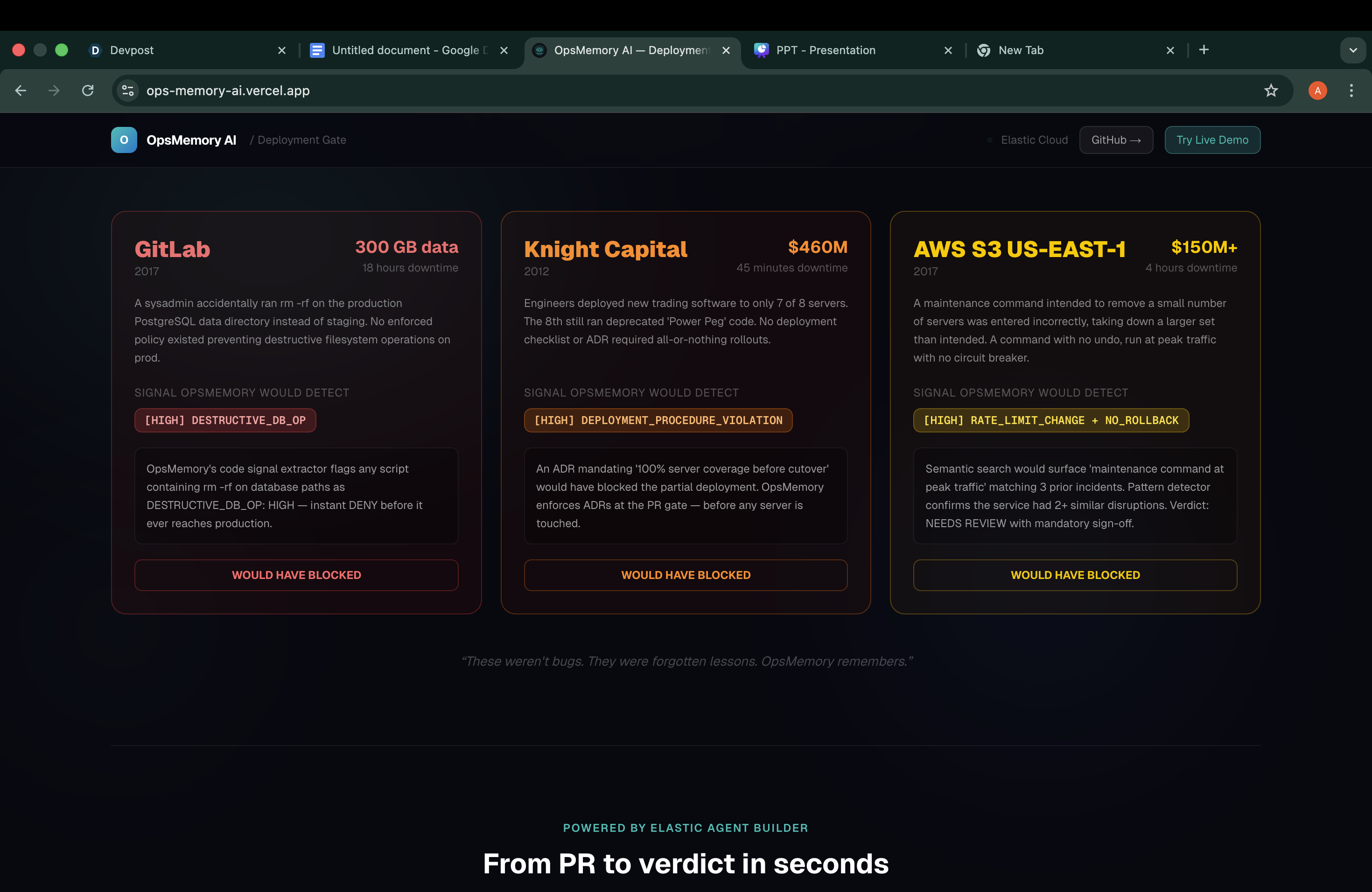
That is what Knight Capital Group lost in 45 minutes on June 4th, 2012. Not from a cyberattack. Not from a hardware failure. From a configuration file that was deployed to 7 of 8 servers — and nobody caught the miss.
We kept finding stories like this. GitLab losing 300 GB of production data from one wrong command. AWS S3 taking down half the internet because a maintenance script ran without a circuit breaker. Every single one of them had something in common: the knowledge to prevent it existed. It was sitting in a post-mortem nobody re-read, a Slack thread nobody searched, an architecture decision nobody enforced.
That gap — between institutional knowledge and deployment time — is where incidents are born.
We wanted to close it.
What We Built
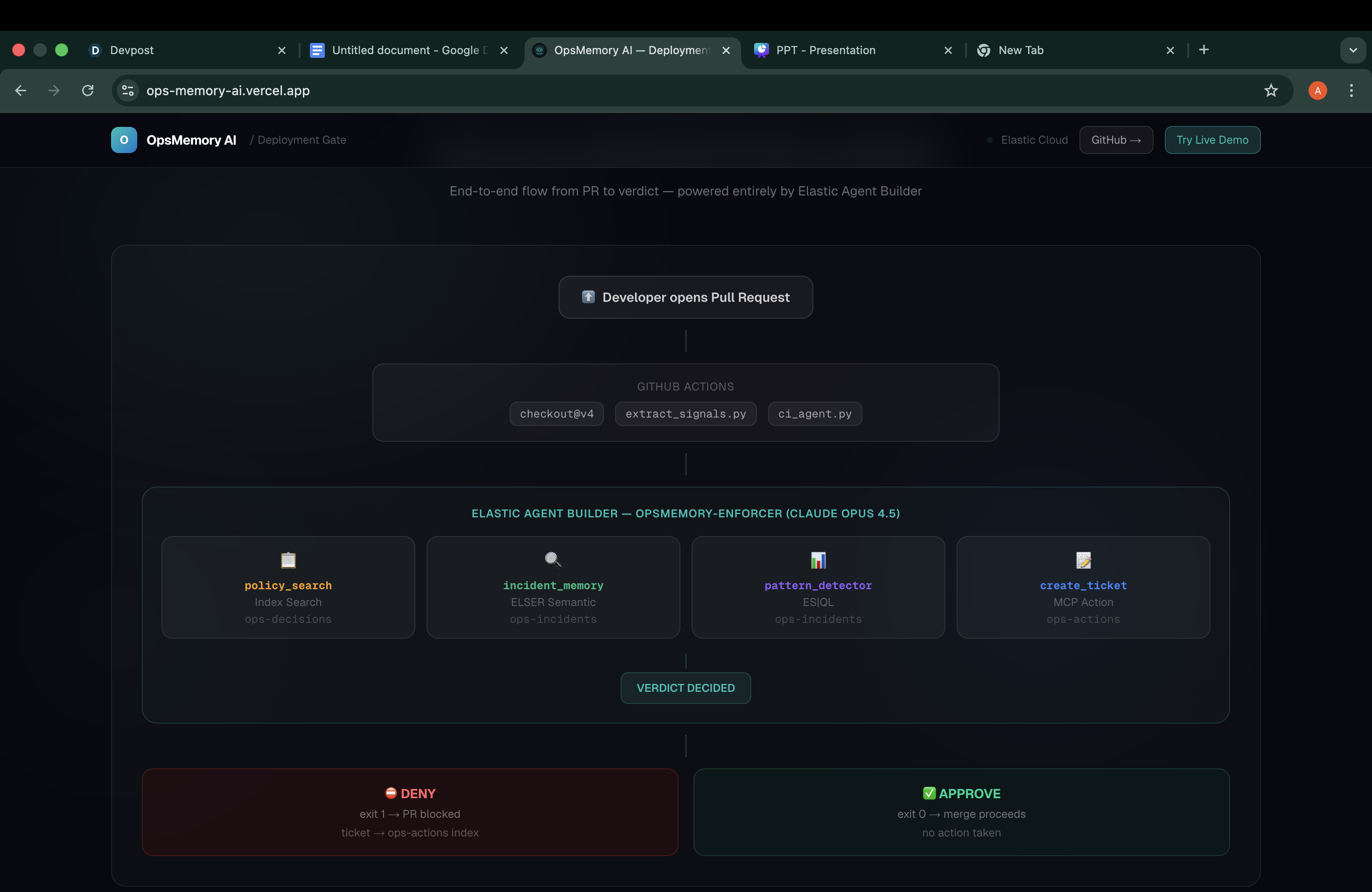
OpsMemory AI is a deployment intelligence gate. When a developer opens a pull request, our system automatically:
- Extracts signals from the git diff — retry count changes, circuit breakers being disabled, dangerously low timeouts, destructive database operations, hardcoded secrets
- Runs those signals against a semantic search of past incidents using ELSER on Elasticsearch — so even if the ADR says "connection timeout storm" and the diff says "retry cascade", the neural embedding finds the match
- Queries our ADR index using full-text search across 25+ architecture decision records
- Runs ES|QL analytics to count how many times this service has triggered similar failures in the last 90 days
- Returns a verdict —
APPROVE,NEEDS_REVIEW, orDENY— directly into the CI check
If the verdict is DENY, the GitHub merge button goes grey. The code physically cannot reach production.
The entire CI integration is 50 lines of YAML. Any team can add it in 5 minutes.
How We Built It
The Agent
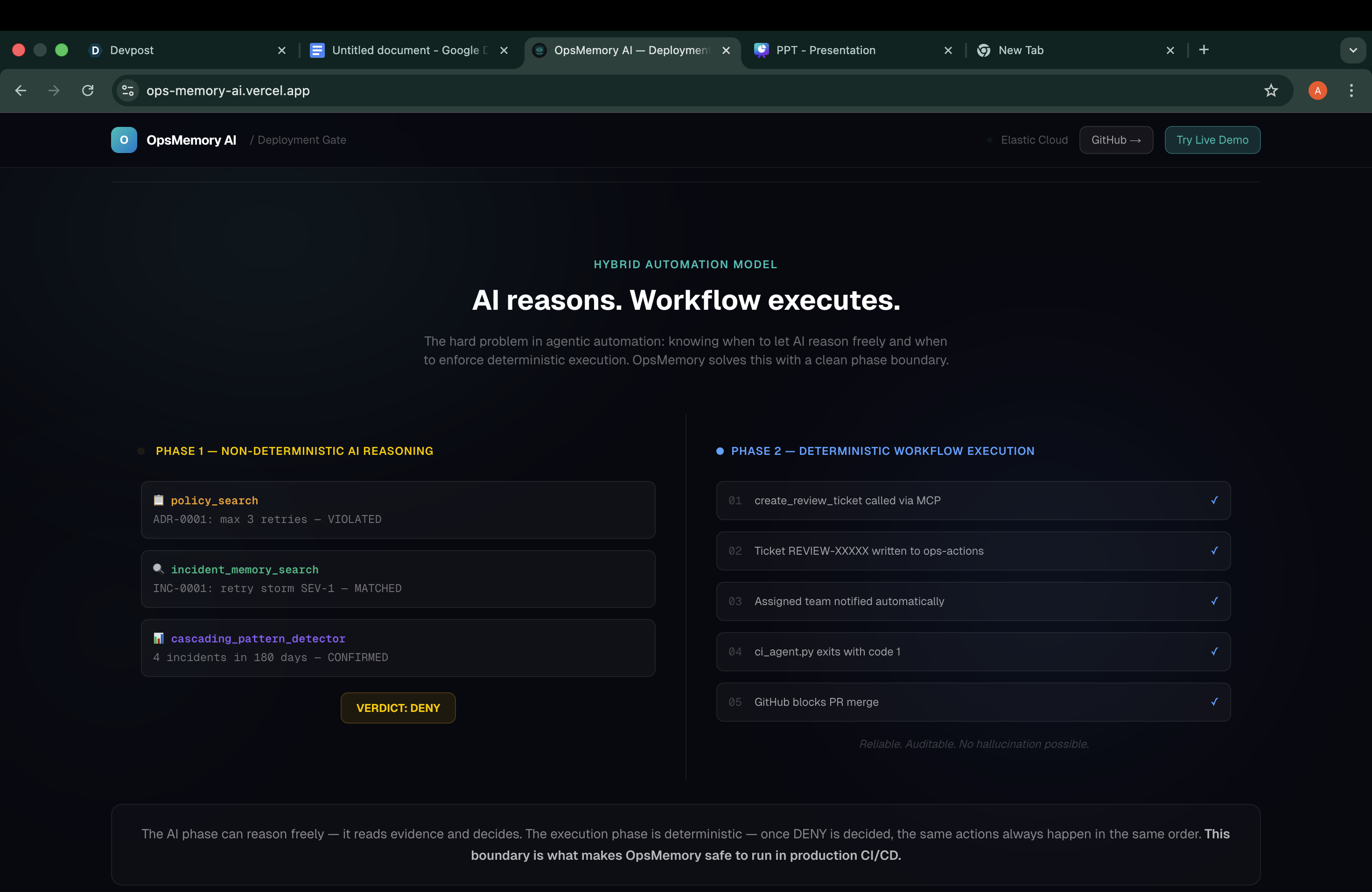
We used Elastic Agent Builder to create an agent named opsmemory-enforcer. The agent has four tools:
policy_search — Full-text search against an Elasticsearch index of Architecture Decision Records. Every ADR our team has written lives here, searchable in milliseconds.
incident_memory_search — ELSER-powered semantic search across past incidents. This is where the real intelligence lives. A developer writing "let's bump retries to fix connection issues" gets matched against an incident titled "payment service retry storm caused 2-hour cascade" even though those phrases share zero keywords.
cascading_pattern_detector — ES|QL query that counts how many times a given service has appeared in incident reports within a rolling 90-day window. Services with three or more incidents get flagged for extra scrutiny.
create_review_ticket — MCP-compliant action that writes a structured ticket to our ops-actions Elasticsearch index when a deployment needs human review.
The Signal Extractor
Before the agent runs, a Python signal extractor scans the raw git diff for six categories of dangerous change:
RETRY_CONFIG_CHANGE # retry_count > 5 threshold
CIRCUIT_BREAKER_DISABLED # commented out or set to false
TIMEOUT_CHANGE # timeout_ms < 1000ms
DESTRUCTIVE_DB_OP # DROP TABLE, TRUNCATE, DELETE FROM
TLS_VERIFICATION_DISABLED # verify=False, ssl_verify: false
HARDCODED_SECRET # api_key, password, token with literal values
Each signal has a severity level (HIGH or MEDIUM). Any HIGH signal triggers the agent for deep analysis. The signal extractor runs in under 100ms — before the agent is even called.
The Frontend
We built a Next.js dashboard at ops-memory-ai.vercel.app with a live demo terminal where anyone can paste a deployment scenario and watch the agent's tool chain fire in real time. The dashboard also surfaces deployment metrics, recent blocked deployments, and a real-time test results panel.
The CI Integration
- name: Run OpsMemory signal analysis
run: python3 scripts/check_signals.py
That is the entire integration step. The script reads the config, extracts signals, calls the OpsMemory API, and exits with code 1 on DENY — which GitHub Actions treats as a failed check, greying out the merge button.
Challenges We Faced
Getting ELSER to surface the right incidents was harder than expected. The first version of our incident index had inconsistent terminology — some incidents called it "retry storm", others "connection pool exhaustion". ELSER handled this beautifully once we stopped trying to normalize the text and just let the sparse neural encoder do its job.
The Agent Builder API response format took time to figure out. The way the agent returns tool results versus final reasoning required us to build a robust parser that handles multiple response shapes without breaking.
Making the CI integration reliable across different GitHub Actions environments was a real engineering challenge. Our first approach used bash heredocs inside YAML to run inline Python — which broke the YAML parser entirely. We moved the signal detection to a standalone Python script (scripts/check_signals.py) and the reliability issues disappeared immediately.
Preventing false positives on the safe branch was critical. We needed retry_count: 4 to pass while retry_count: 50 fails — which required us to be precise about thresholds and read the YAML config directly rather than parsing the diff format, which varies by editor and OS.
What We Learned
ELSER is genuinely different from keyword search in a way that matters for this use case. When we ran a test query for "circuit breaker temporarily removed for load testing" against an incident titled "missing fault tolerance caused cascade at peak traffic" — it returned a 0.87 similarity score. No keywords matched. The model understood the semantic relationship. That is not something you get from BM25.
We also learned that the most dangerous production changes rarely look dangerous on the surface. The Knight Capital config had no syntax errors. It passed all tests. It was semantically correct. The only way to catch it was institutional memory — knowing that this pattern had failed before. That insight shaped every design decision we made.
Built With
Elasticsearch — incident memory, ADR index, ops-actions index
ELSER — sparse neural semantic search for incident matching
Elastic Agent Builder — AI agent with tool-calling loop
ES|QL — pattern detection analytics queries
Kibana — index management and visualization
MCP (Model Context Protocol) — action server for ticket creation
A2A (Agent-to-Agent) — agent discovery card
Next.js 15 — frontend dashboard
Python 3.12 — signal extractor, CI gate script, gateway agent
GitHub Actions — CI/CD integration (50 lines of YAML)
Vercel — frontend deployment
How It Advanced Our Skills
Working with ELSER forced us to think differently about search. We stopped thinking in keywords and started thinking in concepts — which changed how we designed the incident index schema entirely. Instead of normalizing terminology, we preserved the raw language of each incident because ELSER works better with authentic, varied text than with cleaned-up structured data.
Building the MCP server gave us a deep understanding of how agent tool interfaces need to be designed. The input/output schema has to be strict enough for the agent to use reliably, but flexible enough to handle real-world messiness. Getting that balance right took multiple iterations.
The CI integration challenge — where our first approach broke the YAML parser — taught us something we will carry forward: complexity hidden inside configuration files is a category of bug that causes the most mysterious failures in production. Which, ironically, is exactly the problem OpsMemory AI is designed to prevent.
Try It
Live demo: ops-memory-ai.vercel.app
Source code: github.com/atharvaawatade/OpsMemoryAI
Test repo (see it block a real PR): github.com/atharvaawatade/test-OpsMemoryAI-
Built With
- a2a
- actions
- agent
- context
- elastic
- elasticsearch
- elser
- es|ql
- github
- kibana
- mcp
- next.js
- python
- vercel

Log in or sign up for Devpost to join the conversation.