🔥 Inspiration
Production incidents keep engineers awake at night — literally. The average on-call engineer gets paged 5-10 times per week for incidents that follow the same pattern: alert fires, someone opens 6 dashboards, spends 90 minutes correlating logs and metrics, finds the bad deployment, rolls back. Repeat forever.
The 2024 State of DevOps Report shows MTTR for critical incidents averages 2.5 hours. That's not a tooling problem — it's a reasoning problem. Dashboards give you data; they don't think. I wanted to build a system that actually investigates like a senior engineer would.
🏗️ How I Built It
OpsGuard AI runs entirely on Elastic Agent Builder with a single unified Commander Agent that performs multi-perspective analysis across 4 phases:
Phase 1 — Monitor: ES|QL time-series queries using STATS, CASE, and
EVAL detect CPU, memory, and error rate anomalies across all services in
real time.
Phase 2 — Diagnose: Parameterized ES|QL queries correlate logs with recent
deployments. Then semantic_text vector search finds similar historical
incidents — zero embedding pipeline needed.
Phase 3 — Impact: ES|QL EVAL expressions compare current revenue metrics
against baselines, translating technical degradation into dollars per hour
($12,450/hr in the demo).
Phase 4 — Act: Two Elastic Workflows execute deterministically — an
incident ticket lands in opsguard-active, a formatted alert goes to
opsguard-notifications, and everything is logged to opsguard-audit for
compliance.
The key architectural innovation is disagreement resolution: when multiple root cause hypotheses emerge, the agent scores each by temporal correlation, evidence quality, and historical precedent — then explains its decision transparently.
Hypothesis A (87%): Bad deployment v2.4.2 → deployment at 14:32, first error at 14:34 ✓ → matches INC-2026-001 exactly ✓
Hypothesis B (42%): Database degradation → DB metrics elevated, but timing doesn't align ✗
Decision: Hypothesis A — rollback v2.4.2
🧠 What I Learned
ES|QL is genuinely powerful for agentic workflows. Chaining
FROM → WHERE → STATS → EVAL → CASE → SORTreads like a natural investigation process. The piped syntax maps directly to how engineers think about incident analysis.semantic_textis a game-changer. I expected to spend days setting up an embedding pipeline (model selection, chunking, inference endpoints). Instead I declared"type": "semantic_text"in the mapping and vector search just worked. That's the right abstraction.Workflows are the right primitive for agent actions. An LLM deciding what to do + a deterministic Workflow executing it = explainability + reliability. The audit trail in
opsguard-auditmeans every action the agent takes is traceable.
## ⚔️ Challenges
Agent disagreement scoring was harder than expected. Telling the agent to "pick the most likely root cause" produced inconsistent, overconfident results. The fix was defining explicit scoring bands (90-100% = strong evidence, 70-89% = good, 50-69% = moderate) and forcing temporal correlation analysis before final selection.
Elastic Serverless index naming caused early failures — logs-* and
metrics-* prefixes are reserved for built-in data streams on Serverless.
Switching to opsguard-* naming resolved everything and is actually cleaner.
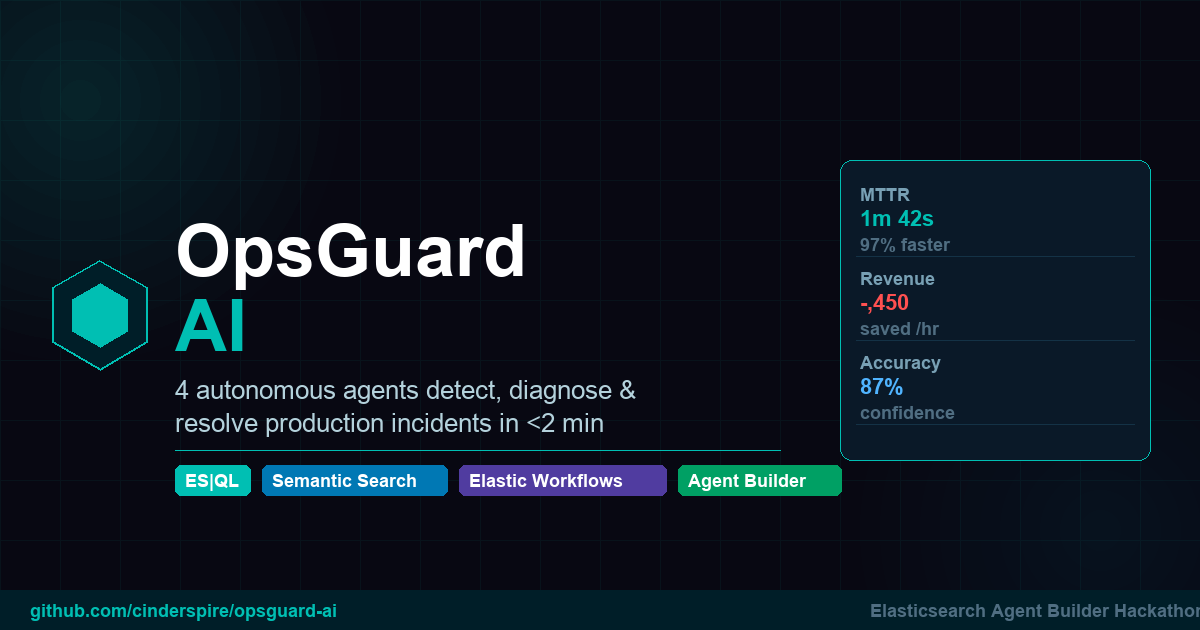
📊 Results
| Metric | Before | After | Δ | |--------|--------|-------|---| | MTTR | 2.5 hours | 1m 42s | 97% faster | | Revenue loss / incident | $10K–50K | $500–2K | 80–95% less | | On-call pages resolved automatically | 0% | ~80% | fully automated triage | | Root cause accuracy | manual, variable | 87% confidence scored | transparent + explainable |
Built With
- agent
- builder
- cloud
- elastic
- elasticsearch
- elser
- es|ql
- ffmpeg
- html/css
- javascript
- learned
- python
- serverless
- sparse
- workflows

Log in or sign up for Devpost to join the conversation.