


Inspiration
Building a recommendation engine for opportunities. Given today there are many opportunities in the world to go for but finding the ones that best match your needs is very difficult. A lot of people don't even get to know about such opportunities because of lack of knowledge, or having a network to find those. Therefore we want to help everyone to find opportunities for them based on their need and interest without them searching. We will do the work to scrape through multiple sites and find opportunities and also then recommend the opportunities to be used by users according to their needs. Opportunities like conferences, competitions, scholarships etc. can be difficult to find. So we want to create a one stop solution for getting all world opportunities in one platform and then also provide the best suited recommendations based on the user's profiles, needs and interests. Location is also a major factor, to be able to find an opportunity near the user and according to their interest is equally important.
What it does
Our system helps those who are confused, don't know about any opportunities which are available and good for them either due to lack of knowledge or lack of exposure. We provide recommendation based on different opportunities like webinars, competitions, hackathons, conferences, admission for college, scholarships, seminars to people based on their preferences, interests, likes and needs, location.
We have built a recommendation model for opportunities. Using Machine Learning techniques like Natural Language Processing, Content based Filtering, Web Scraping like Selenium, Beautiful Soup 4. There are two major parts of it :
- Clustering Part : Scraping opportunities through various sites and creating a database from them then clustering them based on relevant semantic meanings. Example: If there is an opportunity for computer science students and another opportunity related to Machine Learning, they should be clustered closer together, when compared with a Social Sciences opportunity.
2.Recommendation engine : Given a dataset of user preferences, recommend opportunities from the opportunity dataset.
We have also created a web application where we can add opportunities, and users can sign up for them. To get data for data analysis on number of users per opportunity, the user preferences.

How we built it :
Clustering Part : Part 1
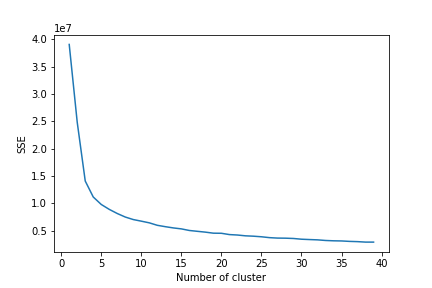
First Iteration: Tried to make Feature based Engineering part where i tried to make all features, through the features , also made sub features like splitting the labels to su labels. All the labeled features , are being transvered into learning model of KMEANS with an optimised K - means++ algo , with k=10.
Second Model: Used Transfer learning and knowledge bases for having sentiment analysis of each and every word in the dataset. Employed Glove.6B.50d text data knowledge for getting 50 dimensional vector for every word. We have Included cosine similarity system to draw similarity between words meaning and sentiment.
Recommendation engine : Problem Statement 2
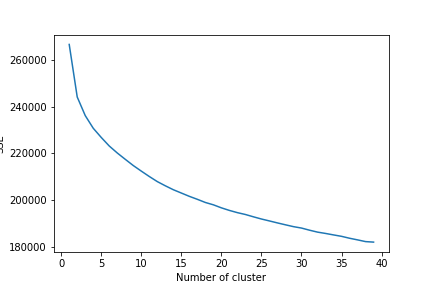
Using TF-IDF (Term Frequency-Inverse Document Frequency) For recommendation Engine we employed TF-IDF vectorisation based system that are used in information retrieval for feature extraction purposes.
Now comes a more general content based recommendation part.
Firstly, for a new profile we will be matching the opportunity and person profile on the basis of, Discipline, Minimum qualification and country in which the candidate is located.
From this, we can recommend the new user by using the matching score,
For our user once he or she have selected an opportunity we will be fetching the selected results and monitor for other factors into account like funding, subtags, location of opportunity and fine-tune my results on base of these and also first and second matching will go hand in hand.
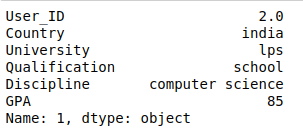
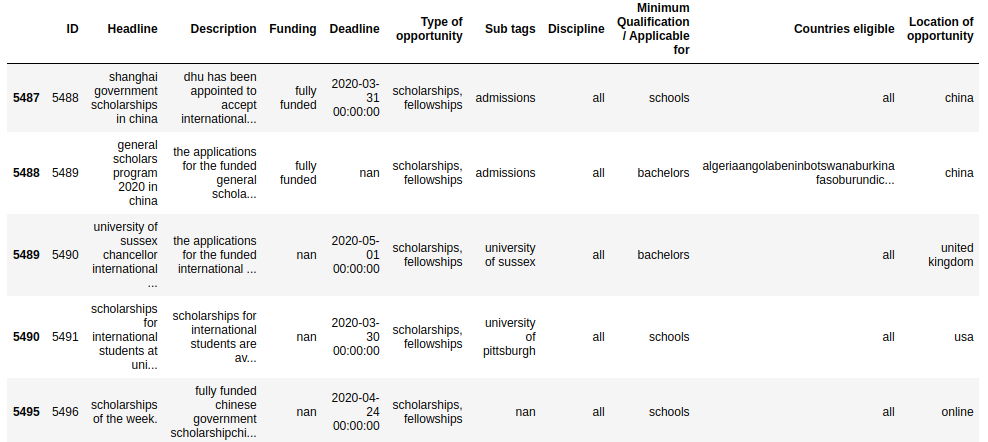
USER PROFILES:
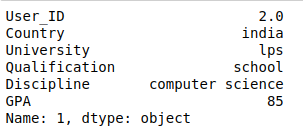
TOP 5 RECOMMENDATIONs: AS we can see user_id 2 has been recommended with opportunity IDs as shown in image below
Challenges we ran into
Collection of the data was a headache. Deciding which parameters to choose was also an issue. Data cleaning and using only those parameters to provide recommendation was also a problem.
Accomplishments that we're proud of
We have been able to get very high accuracy results for the clustering. And the small amount of test users that we showed the recommendations to and input their needs and interests as test data in our recommendation model gave satisfactory results according to their preferences for the opportunities. Giving us a heads up that our model is good.
What we learned
We learned much more into web scraping. We got a first hand experience on working on recommendation systems. Worked on Figma to create designs. Worked on a basic application using PHP to get started with a web app.
What's next for Opportunity-Recommendation-System
We will have one common place for a user where they upload their needs , interests and we provide them recommendations for opportunities based on the needs, interests, location, subject without much user interaction. This saves user's time.






Log in or sign up for Devpost to join the conversation.