
Inspiration
In Côte d'Ivoire, and across West Africa, thousands of young graduates and students struggle to turn their skills into real opportunities. The tech job market is growing fast, but the gap between what young people actually know and what recruiters are looking for stays vague, hard to measure, and even harder to close alone. We wanted to build something that gives every young African a clear, honest, and actionable answer to the question: "Where do I really stand, and what's my next step?"
What it does
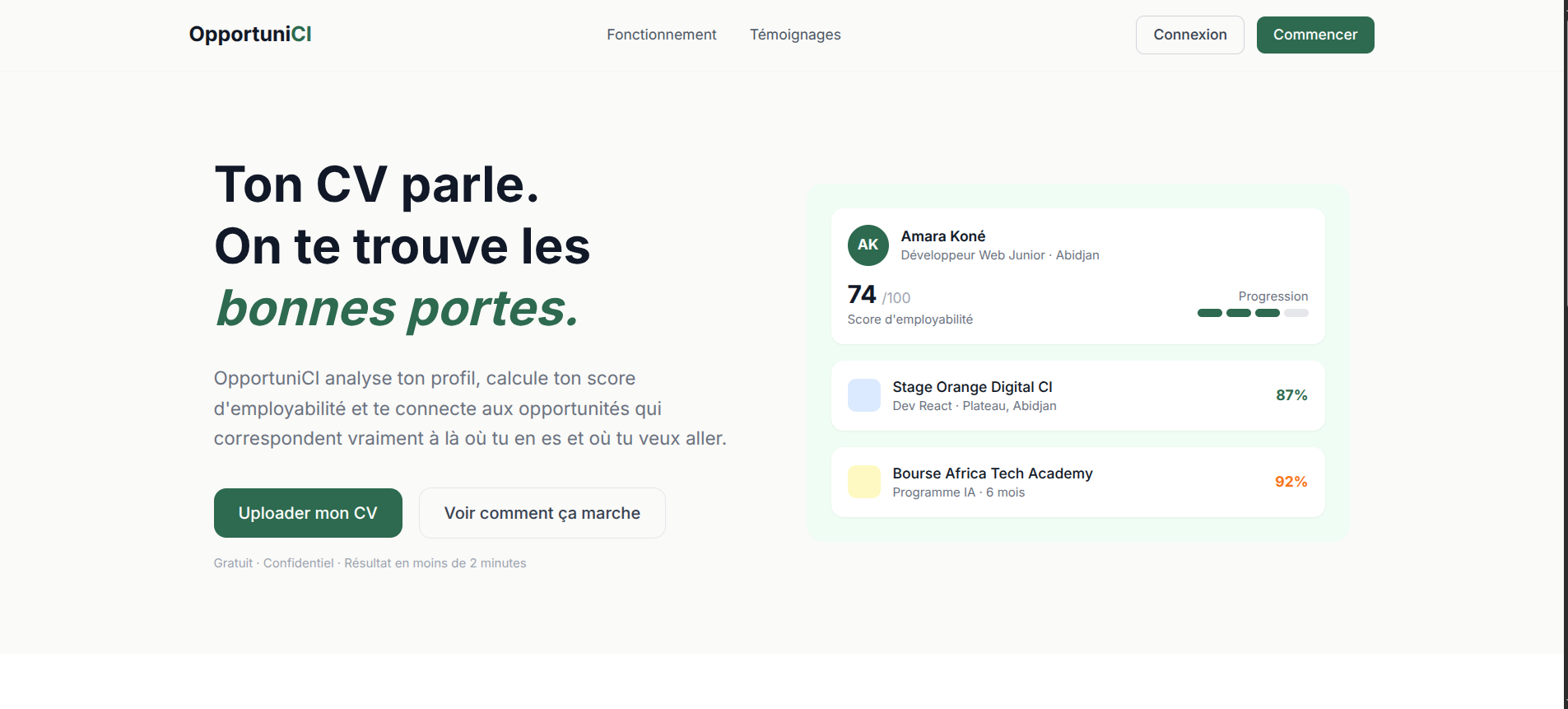
OpportuniCI is an AI-powered career assistant that:
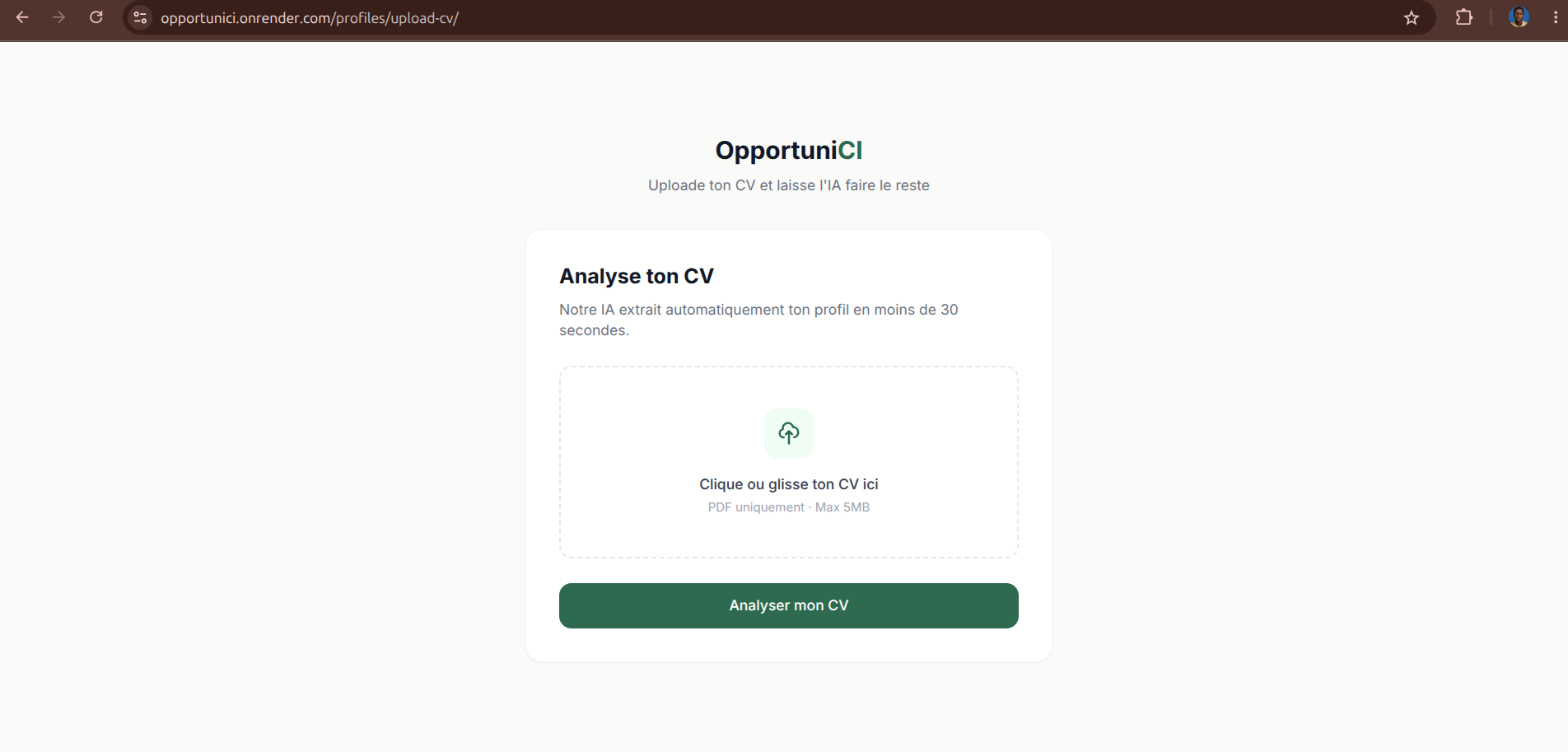
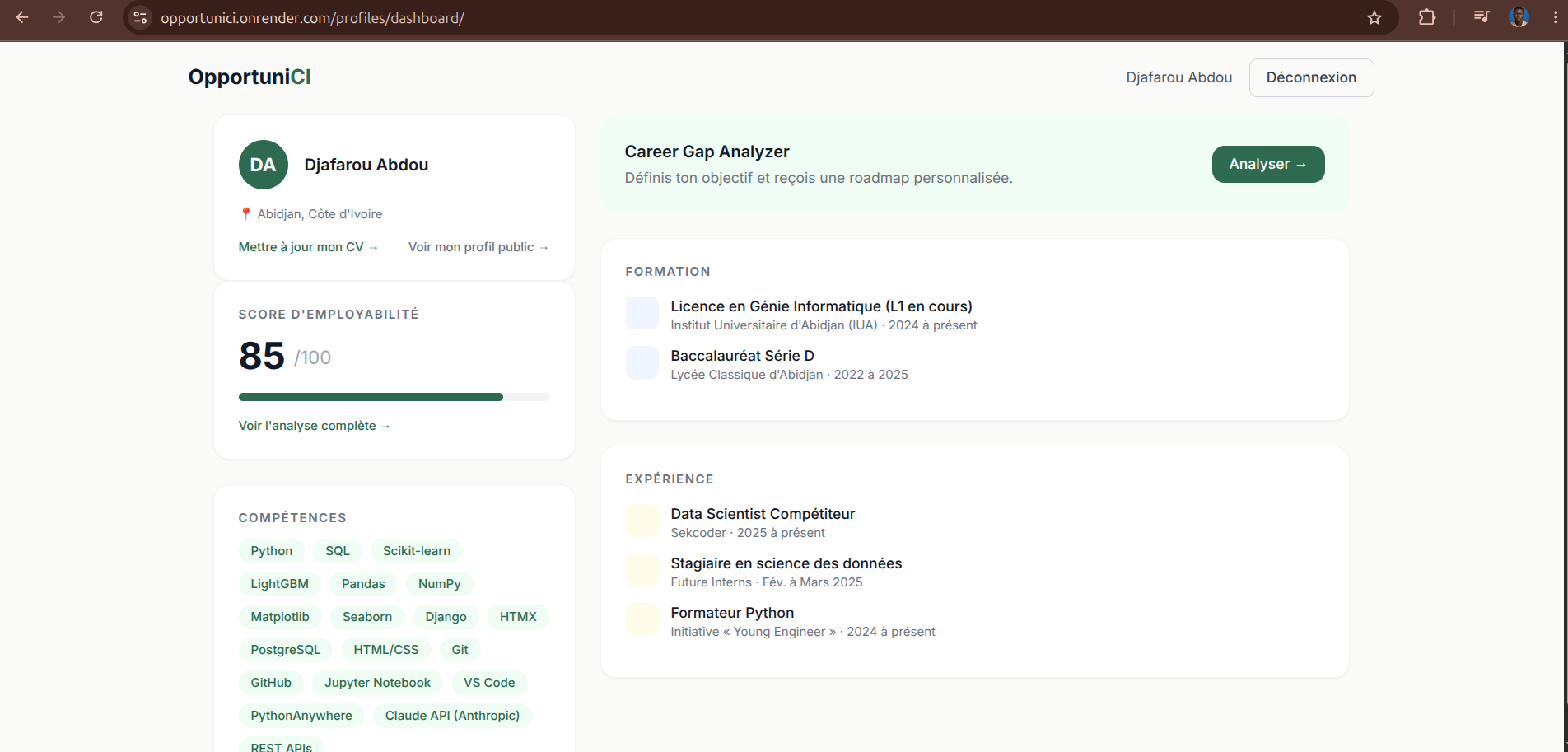
- Analyzes a CV (PDF) and automatically extracts a structured professional profile — skills, education, experience, projects, certifications
- Calculates an employability score out of 100, with a qualitative breakdown: a contextual summary, concrete strengths, honest areas for improvement, and actionable strategic advice
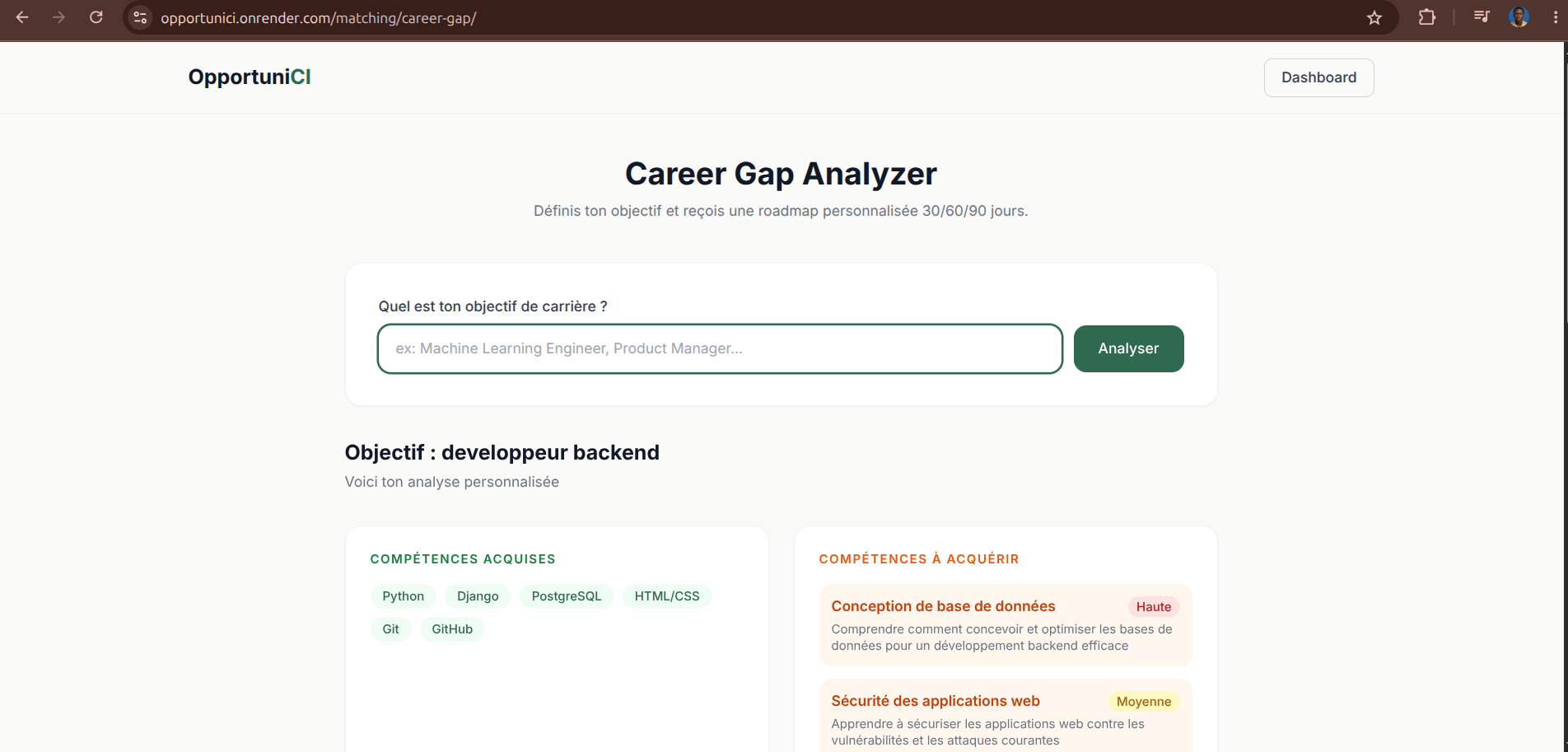
- Identifies the real "Career Gap" — the precise distance between a user's current profile and the career goal they're aiming for, then generates a personalized 30/60/90-day roadmap built on top of skills they already have
- Generates a shareable public profile with a QR code, making networking and spontaneous applications easier
How we built it
The backend runs on Django with PostgreSQL. AI processing (CV parsing, employability scoring, career gap analysis) is powered by Groq's API running Llama 3.3 70B. The frontend uses Tailwind CSS with HTMX for a clean, fast, premium feel inspired by products like Stripe and Linear. The app is deployed on Render, using Whitenoise to serve static files and dj-database-url to connect to PostgreSQL through environment variables.
Every AI call is built around carefully engineered prompts that return strict JSON, which we then validate, repair, and normalize in Python before saving it to the database — because LLM output, however good, can never be fully trusted to be perfectly structured.
Challenges we ran into
Fragile JSON output from the LLM. Llama 3.3 didn't always respect strict JSON syntax — sometimes malformed keys, sometimes null values where we expected empty lists or strings, sometimes even different key names than what we asked for. We built a repair layer (regex-based JSON fixing) and a normalization function in Python that corrects model deviations before they ever touch the database, instead of blindly trusting the LLM's output.
Database constraints clashing with AI-generated nulls. Several NOT NULL fields kept breaking because the AI returned None for optional fields like dates or descriptions. We had to replace every .get('field', '') with .get('field') or '', since Python's .get() default doesn't trigger when the key exists but holds None.
Generic AI output for the Career Gap Analyzer. Early versions listed almost every skill in a domain instead of identifying a real, targeted gap, and suggested vague actions like "take an online course." We rewrote the prompt to force the model into a filtering mindset instead of an enumerating one — prioritizing skills by real impact, and requiring every roadmap action to build on a skill the user already has.
API cost constraints during development. We migrated from Claude, to DeepSeek, to Groq over the course of the project as credits ran out during heavy testing — each migration required adapting the API call format while preserving the same business logic.
A CSS bug from a third-party library. Buttons were invisible at rest and only appeared on hover, caused by a Flowbite CSS transition rule conflicting with our Tailwind classes. We removed the Flowbite dependency, which we barely used anyway.
Production deployment. Configuring Django for production (Whitenoise for static files, dj-database-url for PostgreSQL, dynamic ALLOWED_HOSTS) and debugging a static files mismatch between local and production builds.
Accomplishments that we're proud of
We tested the CV parsing pipeline on more than 7 real CVs in wildly different formats and styles — students, consultants, designers, technical profiles from several West African countries — and consistently got coherent, differentiated employability scores (70 to 90/100) that genuinely reflected the depth of each profile. We're especially proud of the Career Gap Analyzer: after several prompt iterations, it now produces roadmaps that build progressively on a user's existing skills instead of generic advice anyone could Google.
What we learned
We learned that working with LLMs in production means never trusting raw output — validation, repair, and normalization layers aren't optional, they're core infrastructure. We also learned that prompt engineering is real engineering: the difference between a generic, unhelpful AI feature and a genuinely useful one often comes down to how precisely you constrain the model's reasoning, not just what you ask it to do.
What's next for OpportuniCI
- Populate a real database of opportunities (internships, scholarships, jobs) relevant to West African students
- Add a matching engine connecting user profiles directly to these opportunities
- Expand the Career Gap Analyzer with skill-tracking over time, so users can see their progress as they complete roadmap actions
- Partner with local organizations (universities, Orange Digital Center, hackathon communities) to onboard real users at scale
Built With
- dj-database-url
- django
- git/github
- groq-api-(llama-3.3-70b)
- html
- htmx
- javascript
- postgresql
- pydf
- python
- qrcode
- render
- tailwind-css
- whitenoise

Log in or sign up for Devpost to join the conversation.