-
-
Project Flow Chart
-
Dashboard Screenshot
-
Dashboard Screenshot
-
Dashboard Screenshot
-
Dashboard Screenshot
-
Dashboard Screenshot
-

Dashboard Screenshot
Opioid Action Engine
What Our Project Does and Why It Matters
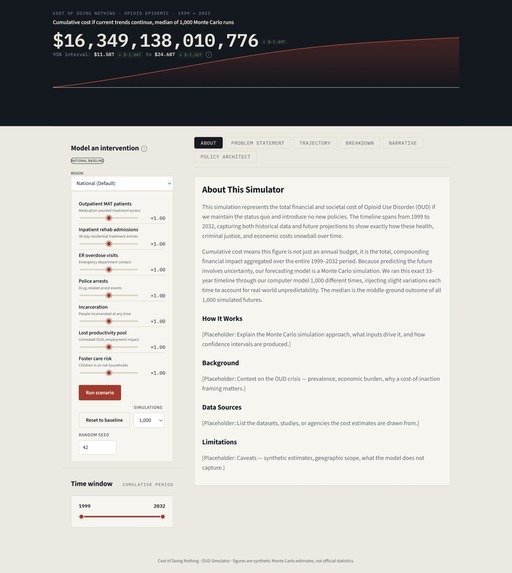
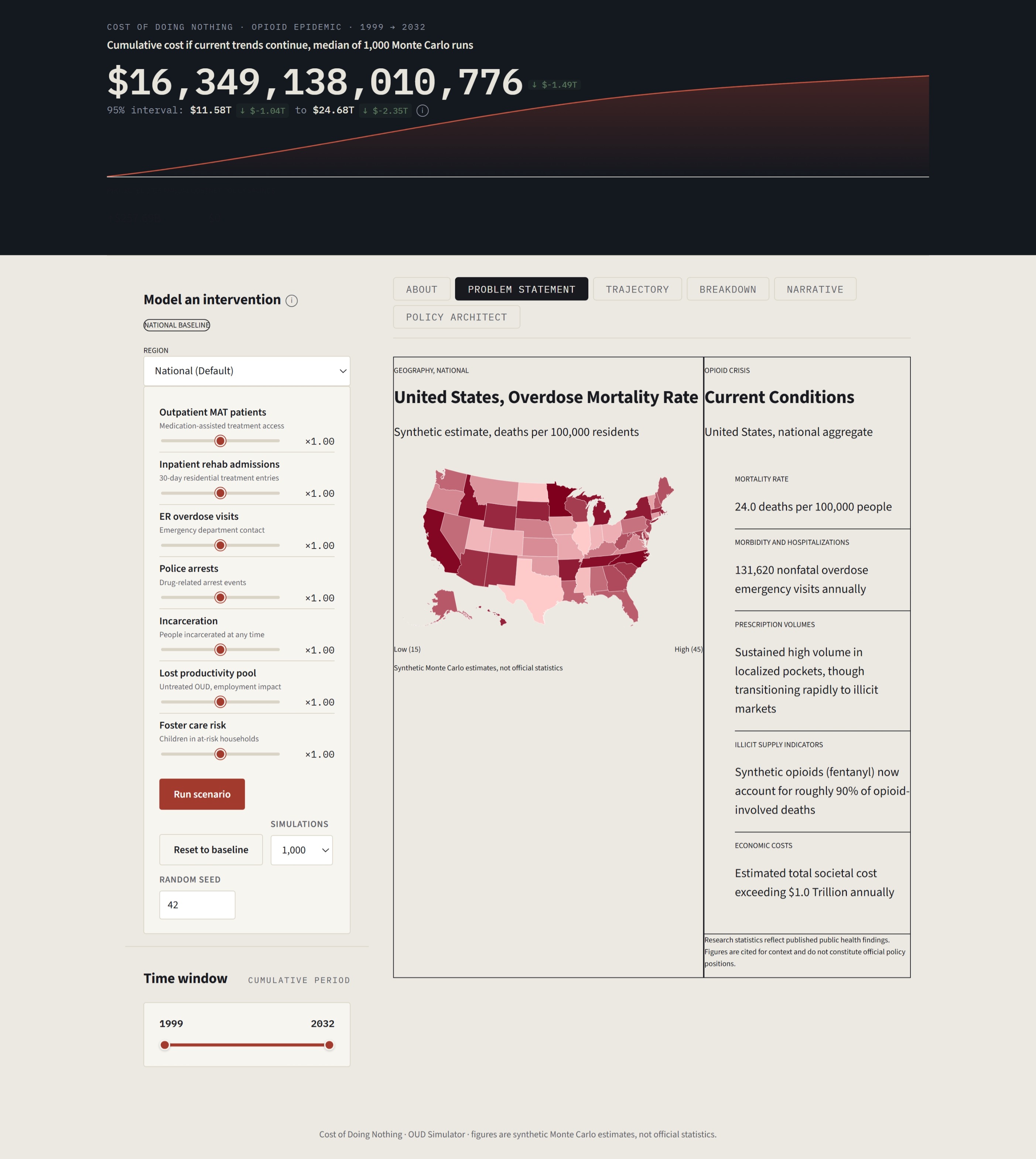
The opioid crisis costs America over $1 trillion every decade. Yet the officials responsible for responding to it, county health directors, state legislators, and public health advocates, have never had a single tool that shows them the full scale of the problem, helps them design a response, and then tells them exactly what that response will cost and save. Until now.
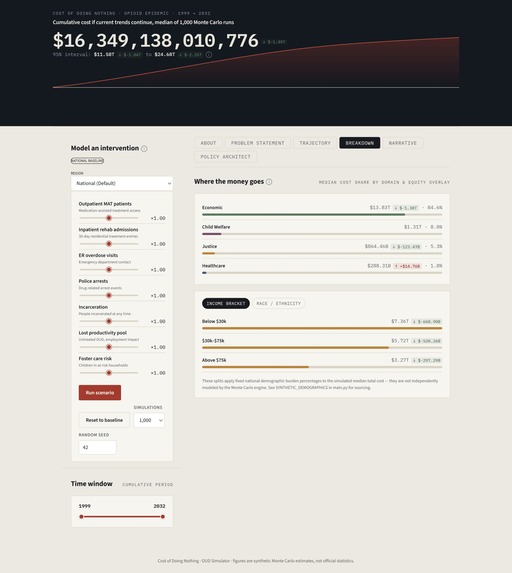
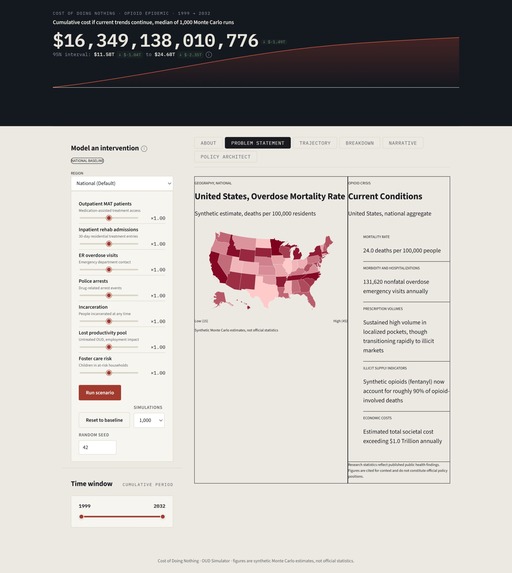
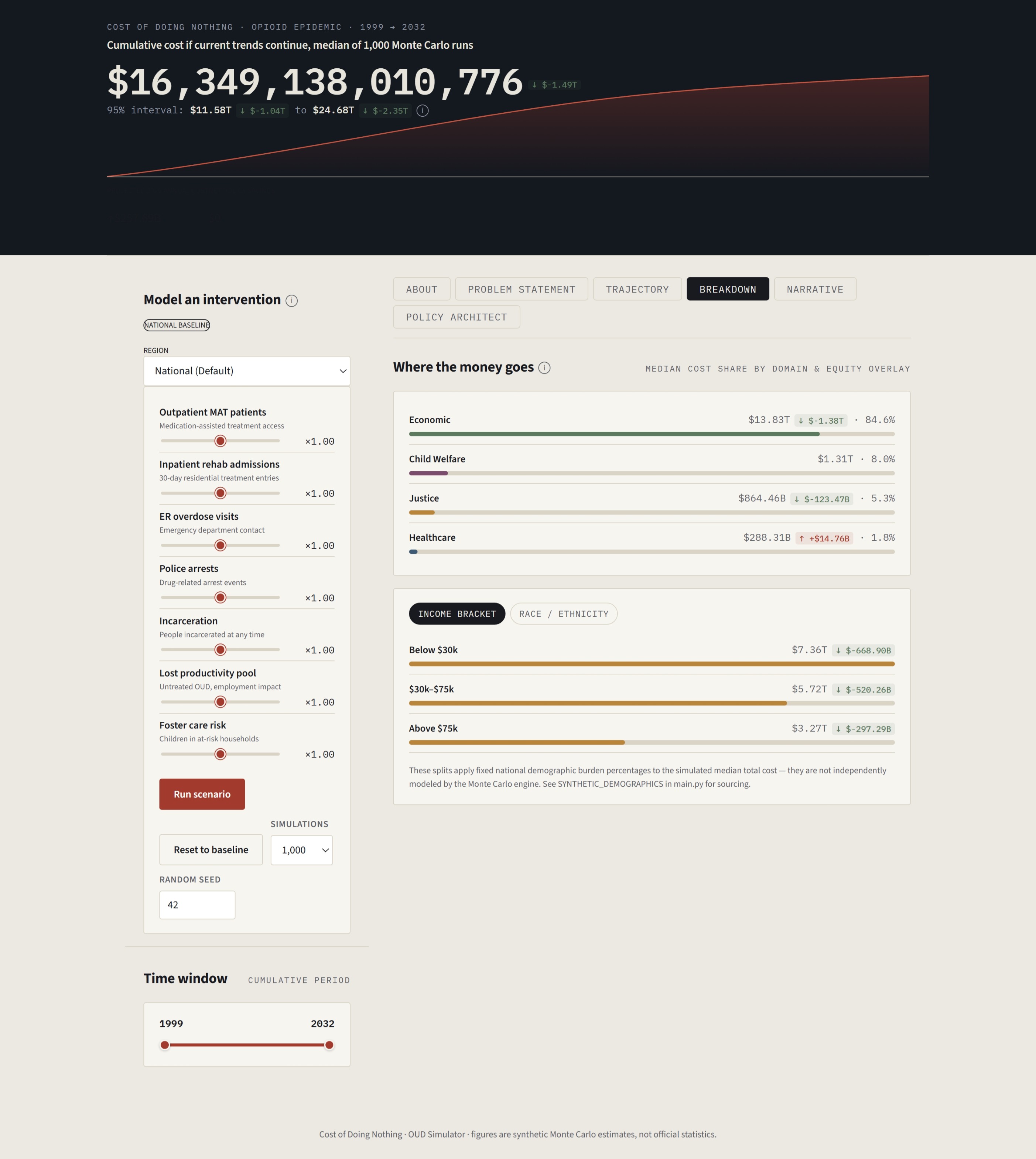
The Opioid Action Engine is not a simulator. It is an end-to-end public health policy intelligence platform built for the people who make real decisions with real consequences. It begins by extracting and synthesizing data from eight government and academic sources, quantifying the opioid epidemic at both the national and state level. It then translates epidemiological data into financial burden across four domains (Healthcare, Justice, Economy, and Child Welfare) to provide a holistic view of current urgencies in the opioid crisis.
From there, the Opioid Action Engine guides decision-makers through the full legislative cycle:
- Research: Search and reference precedent legislation from across the country to understand what other jurisdictions have tried.
- Draft: Work with an AI-assisted policy drafting workflow to tailor interventions for their own community.
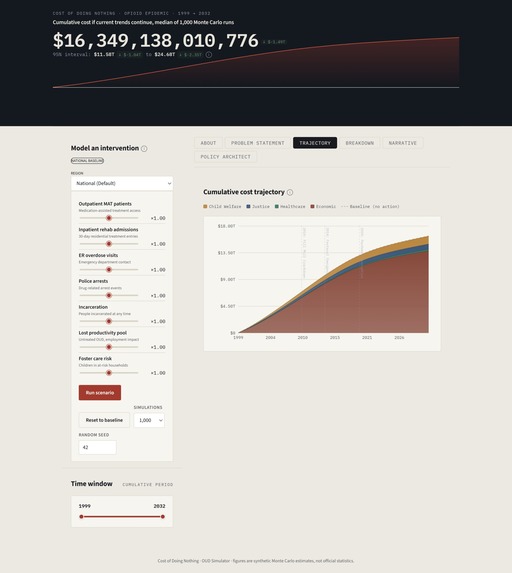
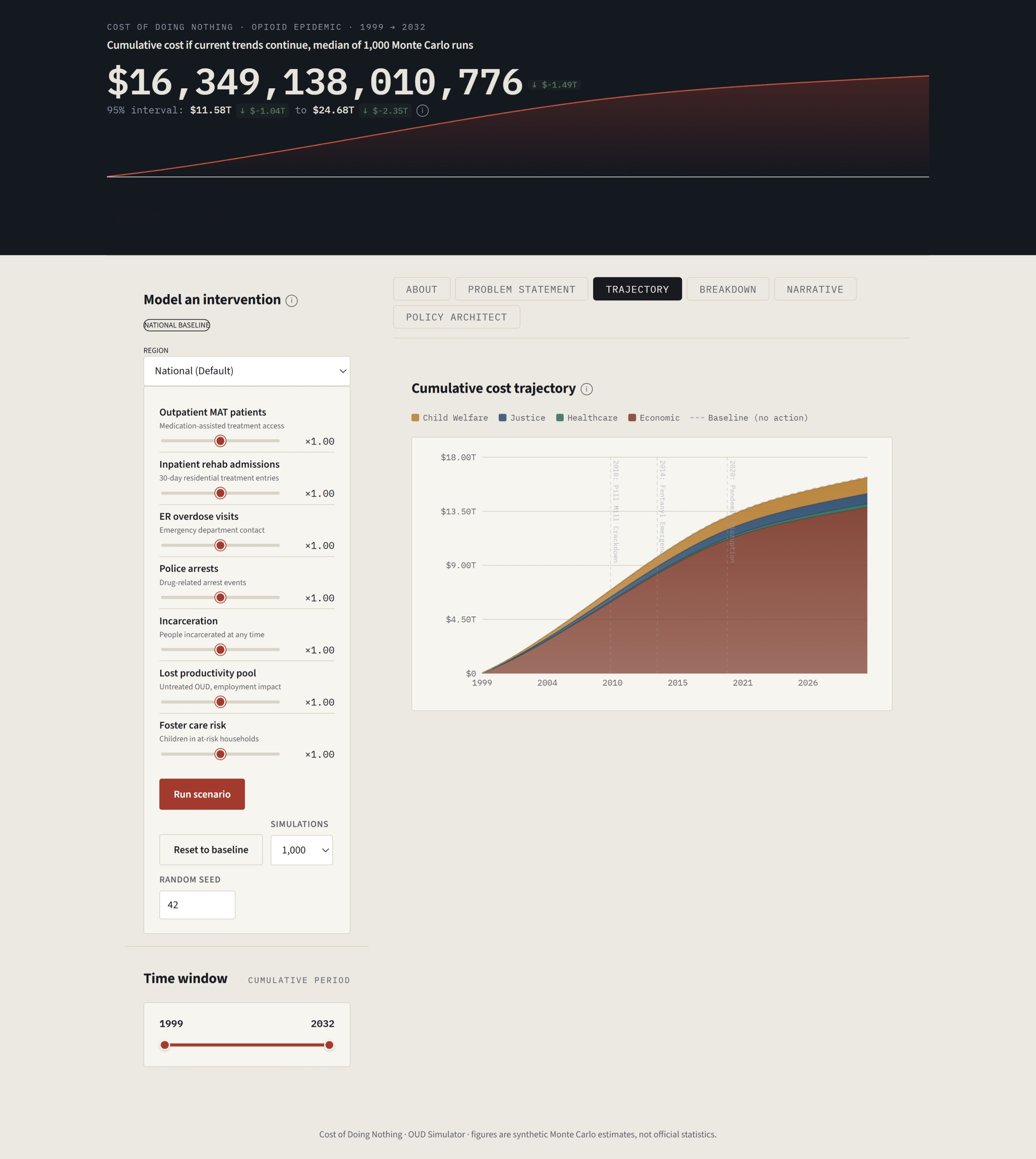
- Project: The engine runs Monte Carlo simulations based on that specific policy to reveal how the compound cost trajectory shifts over the next decade and beyond.
The platform's AI layer also estimates the upfront fiscal cost of introducing a given policy, so policymakers can directly compare the implementation cost against the long-run compounded social costs it is projected to reduce. That comparison (implementation cost versus avoided burden) is the financial argument that moves appropriations.
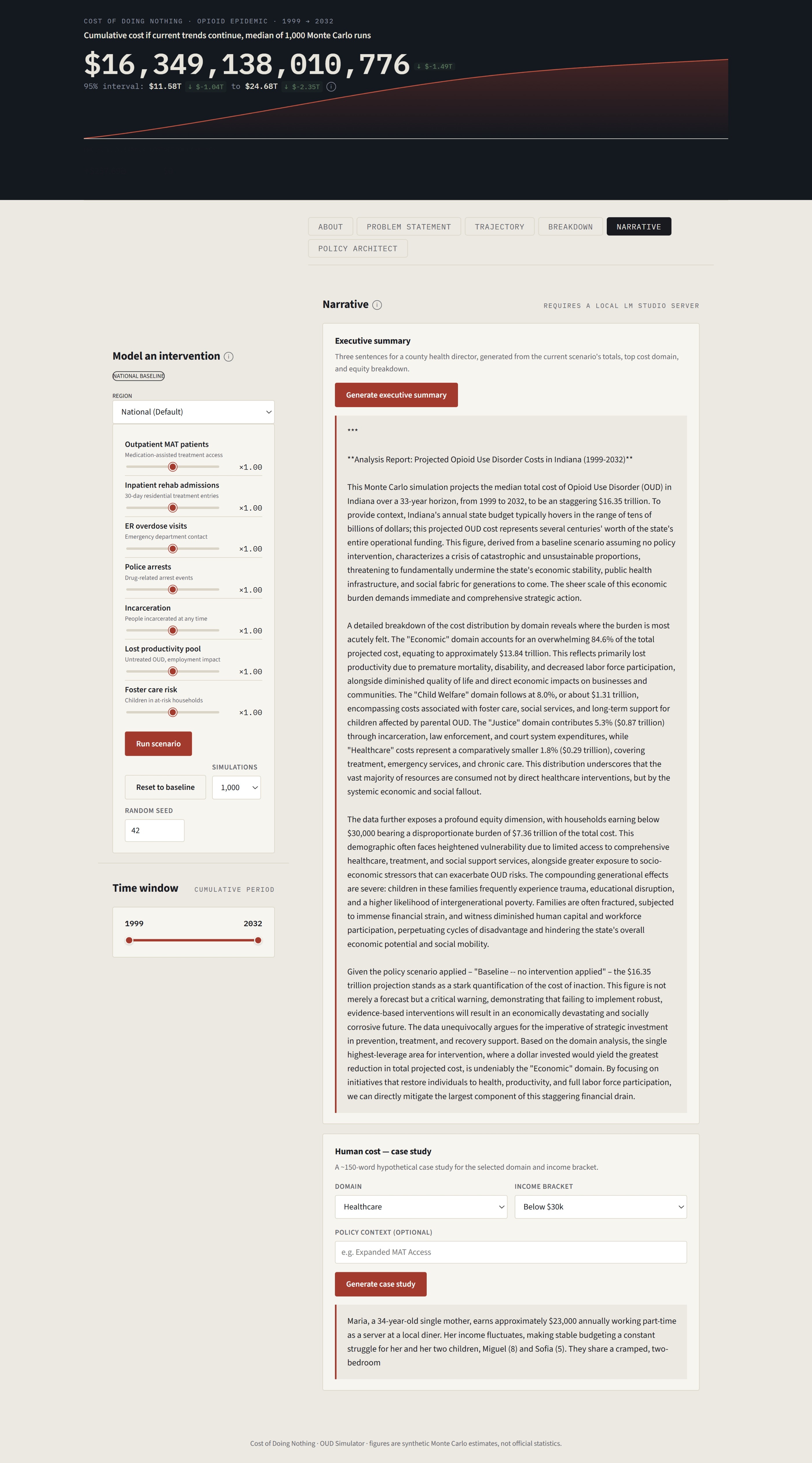
The final piece is the Impact Simulator: a human-centered visualization that translates a policy's projected macroeconomic effects into the lived experience of a family in the targeted community. Because the most rigorous fiscal model in the world still needs to answer one question for the people in the room: what does this actually mean for the people we serve?
The Opioid Action Engine is the first platform to close the full loop from crisis quantification, to legislative research, to AI-assisted policy drafting, to fiscal impact modeling, to community-level human impact, all in one place. It does not just show policymakers the cost of inaction. It gives them everything they need to act.
How We Built It
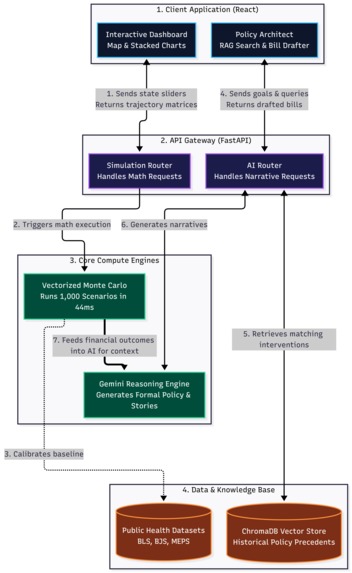
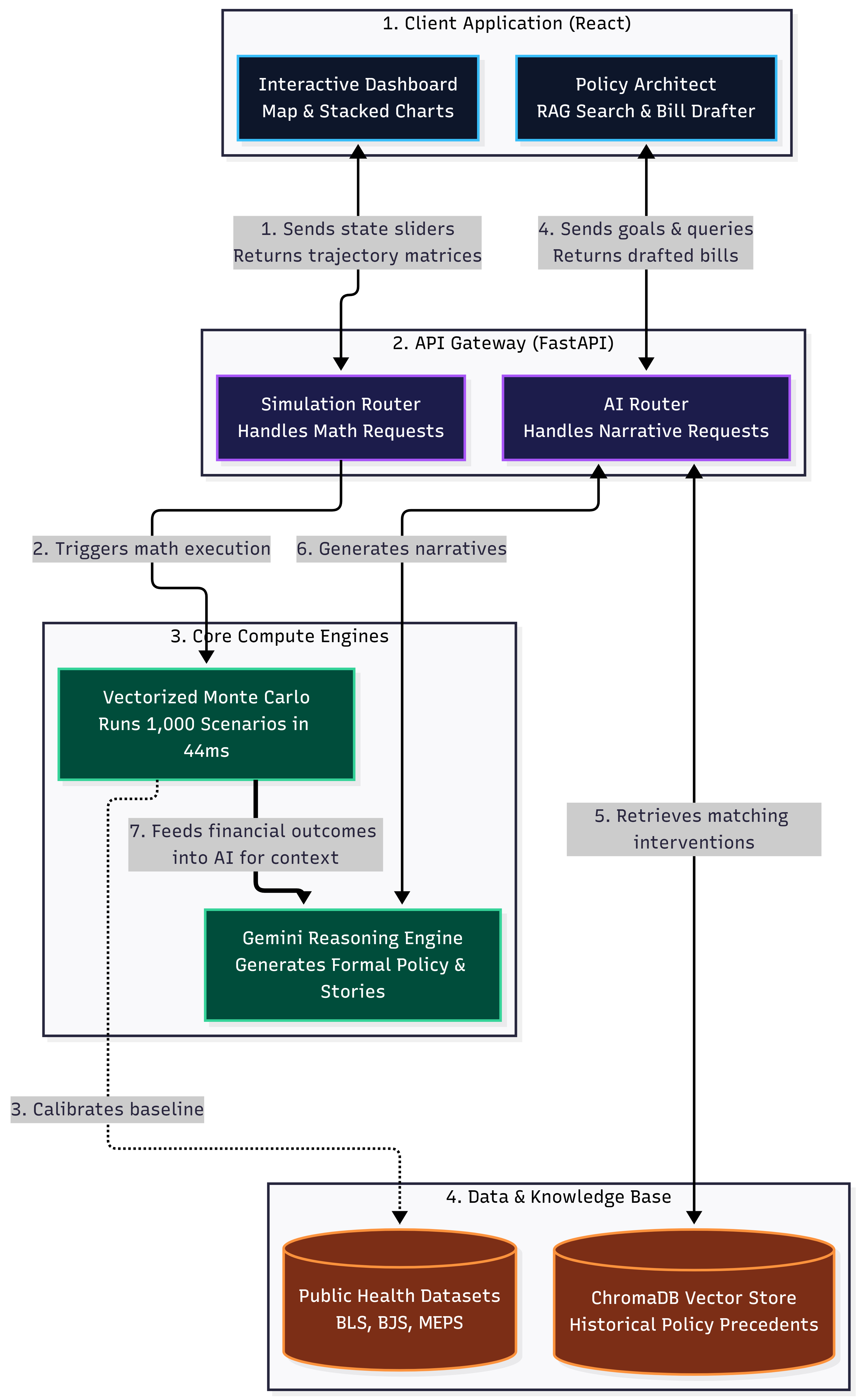
The Opioid Action Engine is constructed in four architectural layers: empirical data foundation, simulation engine, policy design environment, and interactive dashboard.
1. The Empirical Calibration Architecture (Data Foundation)
A two-layer mapping system connecting peer-reviewed epidemiology to research-domain-specific opioid crisis modeling.
Layer 1: Epidemiological Population Engine
Baseline population flows are derived from the FDA/SOURCE system dynamics model, whose analyses are published in Science Advances. These trajectories are calibrated against three nationally validated surveillance datasets:
- NSDUH (National Survey on Drug Use and Health) for disorder prevalence
- NVSS (National Vital Statistics System) for overdose mortality
- SAMHSA/TEDS (Treatment Episode Data Set) for treatment initiation and retention
The result is a 397-month continuous population timeseries spanning January 1999 through January 2032.
Layer 2: Cost Mapping Engine
Each stochastically modeled population cohort is associated with parametric cost distributions calibrated to reflect the known statistical properties of real-world expenditure data:
- Healthcare costs are right-skewed by catastrophic outliers and are modeled with log-normal distributions calibrated against MEPS (Medical Expenditure Panel Survey) for emergency department visits and inpatient rehabilitation.
- Justice costs follow the same log-normal structure, calibrated against BJS (Bureau of Justice Statistics) benchmarks for arrest processing, court disposition, and per-inmate incarceration expenditure.
- Productivity losses use log-normal distributions grounded in BLS (Bureau of Labor Statistics) lower-quartile wage data.
- Child welfare costs, which span wide dispersion between kinship and therapeutic placements, are also log-normal, calibrated against AFCARS (Adoption and Foster Care Analysis and Reporting System) federal cost reports.
- Where cost distributions are approximately symmetric (such as government disability transfer payments), normal distributions are applied to avoid inflating tail risk.
The result is nine cost lines across four domains, each traceable to a named source with a documented distribution type, mean, and standard deviation.
2. The Vectorized Monte Carlo Engine (Backend)
We built a fully vectorized Monte Carlo engine in standard Python, deliberately bypassing distributed frameworks. The entire simulation is expressed as a single tensor operation: a cost sample matrix of shape N \times \times K where N = 1000 simulations, M = 397 months, and K = 9 cost lines) is multiplied element-wise against the population count matrix, then aggregated and percentile-ranked across the simulation axis.
By delegating this entirely to NumPy's BLAS-level matrix routines and eliminating Python-level loops, the engine completes 1,000 scenarios in approximately 44 milliseconds. A baseline simulation ($seed = 42$) is pre-computed at server startup and cached in memory, keeping initial load times minimal for any new policy scenario a user wants to test.
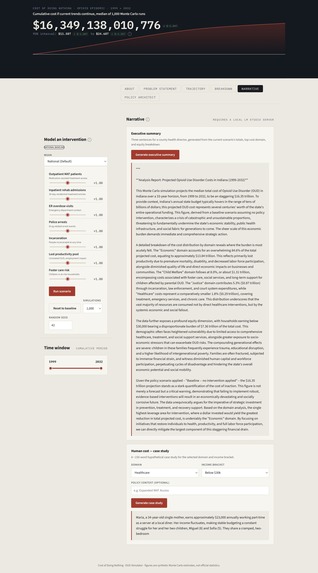
3. The Policy Intelligence Layer
Legislative Research
Policymakers can search a curated vector database of existing opioid-related legislation from across the country. Using a ChromaDB-backed retrieval layer, the system surfaces semantically relevant bills and policy precedents, giving users a research foundation before they begin drafting.
AI-Assisted Policy Drafting
Gemini 2.5 Flash is called with structured research guidance and legislative prompts grounded in the platform's own financial context. Once a policy is drafted, users define its parameters as population scalers (for example, a 25% expansion of MAT access or a 30% reduction in incarceration rates), and the Monte Carlo engine reruns the full 33-year projection under those conditions. The platform's AI layer then estimates the upfront fiscal cost of implementing that policy, expressed in present-day dollars, using a cost estimation framework calibrated to peer-reviewed economic research.
Impact Simulator
Given the designed policy's parameters, the Impact Simulator generates a narrative visualization. The output is grounded in the simulation results and constrained by hallucination and moral guardrails embedded in the system prompt, ensuring the generated story is credible and does not mislead policymakers.
4. The API and Interactive Dashboard
The simulation engine is served through a high-concurrency FastAPI layer built on Python's asyncio runtime. The primary /simulate endpoint accepts full parameter overrides for any cost line and population scalers per intervention cohort, allowing the engine to serve both baseline projections and custom policy scenarios from a single stateless endpoint. The frontend is a reactive Vite/React 18 application styled with Tailwind CSS.
Challenges We Ran Into
The Cross-Domain Data Reconciliation
The hardest problem we faced was not computational. It was conceptual.
Criminal justice systems count bed-nights of incarceration. Healthcare systems count 30-day rehab enrollments. Epidemiological models count transition probabilities between opioid use states. All three are tracking the same people, but through entirely different lenses, in entirely different units, on entirely different timescales.
There is no off-the-shelf crosswalk between them. Where a direct mapping did not exist in the literature, we derived empirically grounded conversion factors from the best available cross-domain research and modeled that uncertainty directly into the simulation's stochastic distributions. Intellectual honesty about the limits of cross-domain mapping was not a weakness to hide. It was a design constraint to honor.
Using AI Responsibly in High-Stakes Policy Drafting
Letting an AI help draft legislation is a genuinely high-stakes design decision. Bad policy language, even well-intentioned language, has real consequences for real communities.
The specific risk we had to solve was overconfidence. A language model will produce authoritative-sounding legislative text whether it is grounded in the platform's data or not. Without deliberate constraints, the AI could draft a bill that sounds rigorous but contradicts the very epidemiological projections sitting in the same dashboard. That gap between confident output and empirical grounding is exactly the kind of failure a public health tool cannot afford.
Our answer was a strict human-led, AI-assisted architecture. The AI drafts only within guardrails defined by the platform's own simulation outputs: the cost projections, the population flows, and the fiscal impact estimates the user has already reviewed. It surfaces options and generates language, but every parameter, every target, and every policy choice belongs to the policymaker. The AI does not recommend a course of action. It helps articulate the one the human has already decided to pursue.
That distinction, between a tool that informs and one that prescribes, is not a fine line. It is the whole point.
Accomplishments We Are Proud Of
Translating Moral Urgency Into Fiscal Imperative
Perhaps our deepest source of pride is something that sits above any individual technical achievement: we built a tool that changes the terms of the debate.
For decades, the argument for investing in OUD treatment, harm reduction, and recovery support has been made primarily as a moral argument. Addiction is a disease. These are human beings. Communities deserve care. Every one of those statements is true, and every one of them has proven insufficient to consistently move appropriations committees, budget offices, and legislative leadership toward the scale of investment the crisis demands. The moral argument, on its own, can be dismissed as advocacy.
What cannot be dismissed is a projection, grounded in peer-reviewed epidemiology and validated cost distributions, showing a county health director precisely how many hundreds of millions of dollars in lost workforce productivity, foster care placements, and criminal justice expenditure will accumulate in her jurisdiction over the next decade if her funding request is denied.
By surfacing the hidden child welfare burden, the diffuse productivity losses, and the compounding cross-sector costs that never appear on any single agency's balance sheet, the Opioid Action Engine gives public health advocates something they have historically lacked: undeniable fiscal data to stand alongside their moral case. We turned a moral imperative into a fiscal one. In the rooms where policy is actually made, that distinction matters enormously.
Achieving Production-Grade Performance in Native Python
The 44-millisecond execution benchmark for 1,000 Monte Carlo scenarios across a 397-month horizon stands as a proof of concept for an underappreciated architectural philosophy: that thoughtful algorithmic design, applied to standard scientific Python libraries, can match the throughput of far more complex distributed systems for the right class of problems.
We did not need PySpark. We did not need a GPU cluster. We did not need a managed cloud computation service. The result is a simulation engine that any public health agency could deploy on a standard government-issue workstation without specialized infrastructure or ongoing cloud expenditure.
What We Learned
The Importance of Scope. All week, we had to keep asking: which parts of this tool are load-bearing for an actual policy decision, and which are just compelling to look at? Our original planning notes sketched an almost open-ended platform — addiction-stage governance, a feature store, multi-substance modeling, image generation. A one-week build forced us to triage that list continuously, not just once at the start.
Localization Is Essential. We had originally scoped localization as a "what's next" item. Partway through the build, we realized that framing was backwards. A simulation calibrated only to national averages is not a decision-making tool for the audience we built this for. Without localization, the Opioid Action Engine was an impressive demonstration of system dynamics and Monte Carlo modeling with no real purchase on anyone's actual decision.
Ruthless Reprioritization. Rather than leave localization on a future roadmap slide, we built it: state and county-level data integration, currently scoped to Indiana, but with the architecture in place to extend nationwide. That came at the direct expense of other planned features, but we are confident it was the right trade. A tool that works precisely for one real place is more valuable, and more honest, than a tool that gestures vaguely at every place.
What's Next
1. Nationwide Scaling
With the localization architecture proven for Indiana, the next clear step is scaling it nationwide. Any county health director, not just one in Indiana, should be able to generate a projection calibrated to their own jurisdiction.
2. Local Data Integration
The second priority is letting individual jurisdictions upload their own local data to calibrate the model directly — an actual population count, a locally observed prevalence rate, or a negotiated treatment cost — rather than relying on state or national proxies.
Because our narrative layer calls an external LLM API rather than a model running on the user's own hardware, raw uploaded jurisdiction data is never included in that call. Our architecture already enforces this boundary: the AI endpoints only ever receive pre-aggregated simulation outputs (median cost figures, domain shares, demographic splits) and never the underlying inputs that produced them. Any upload pathway we build will preserve that separation deliberately, using uploaded data only inside the deterministic simulation engine and never forwarding it in raw form to a third-party API.




Log in or sign up for Devpost to join the conversation.