Operon AI – Autonomous UI Navigator
Note: Check out our Medium Blog Post for a deeper dive into the architecture!
Inspiration
Modern software is powerful, but interacting with it still requires humans to manually navigate interfaces, click buttons, and perform repetitive tasks. While automation exists through APIs and scripts, most real-world workflows still happen through graphical user interfaces.
We were inspired by the idea of AI agents that can operate computers like humans, similar to emerging research in autonomous computer operators and browser agents.
The vision behind Operon AI was to create an intelligent system that can see a screen, understand UI elements, reason about the task, and execute actions automatically.
Instead of writing scripts or automation rules, users simply give a goal, and the AI agent navigates the interface visually to accomplish it. This transforms software interaction from manual control → intelligent delegation.
What it does
Operon AI is a multimodal UI Navigator Agent powered by Gemini that can visually understand interfaces and perform actions on behalf of the user. The system observes a screen, identifies UI elements, plans the next steps, and executes actions like a human operator.
Key Capabilities:
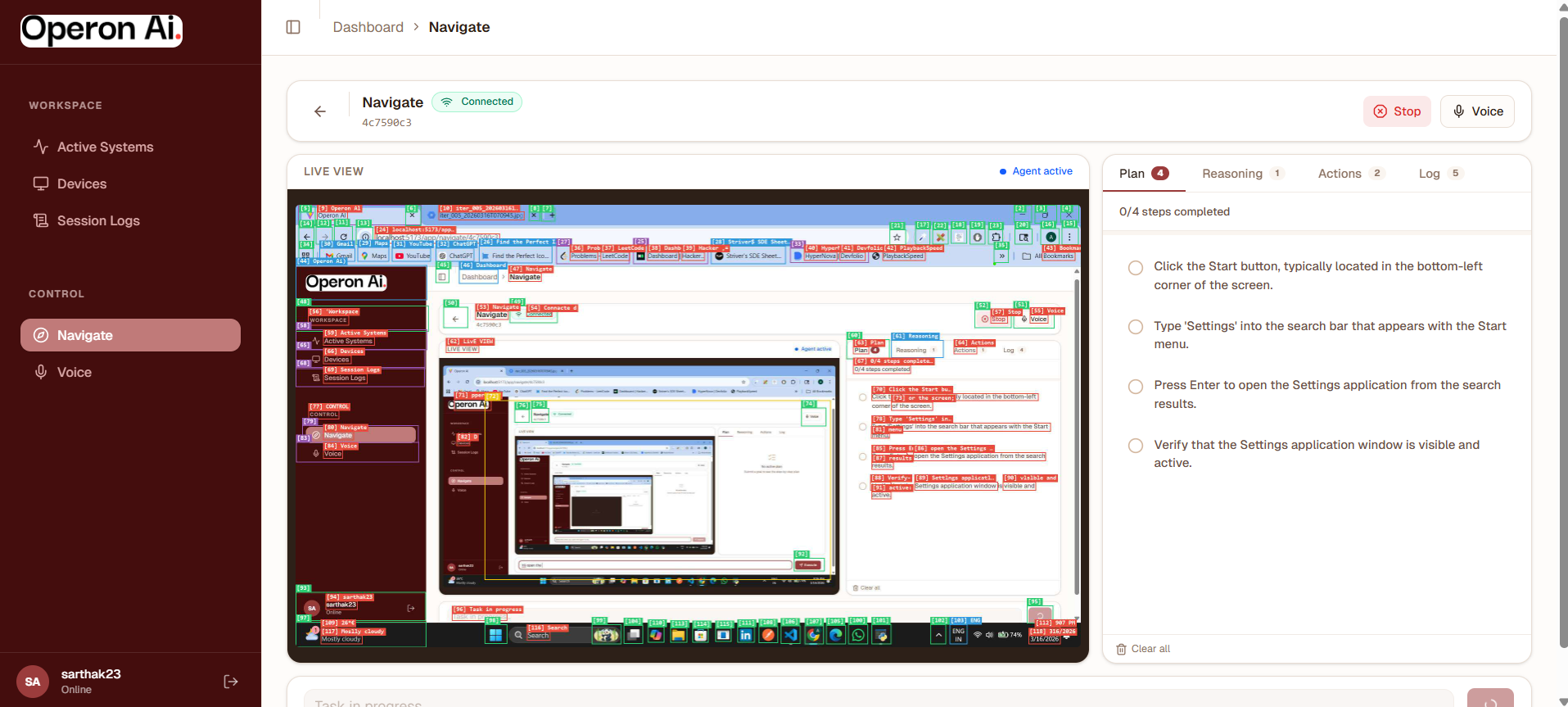
- Visual UI understanding: The agent analyzes screenshots and identifies interactive elements such as buttons, menus, and inputs.
- Goal-driven planning: The AI interprets user intent and generates a sequence of actions to complete tasks.
- Autonomous execution: The system performs clicks, navigation, and interactions automatically.
- Voice interaction: Users can control the agent using natural speech.
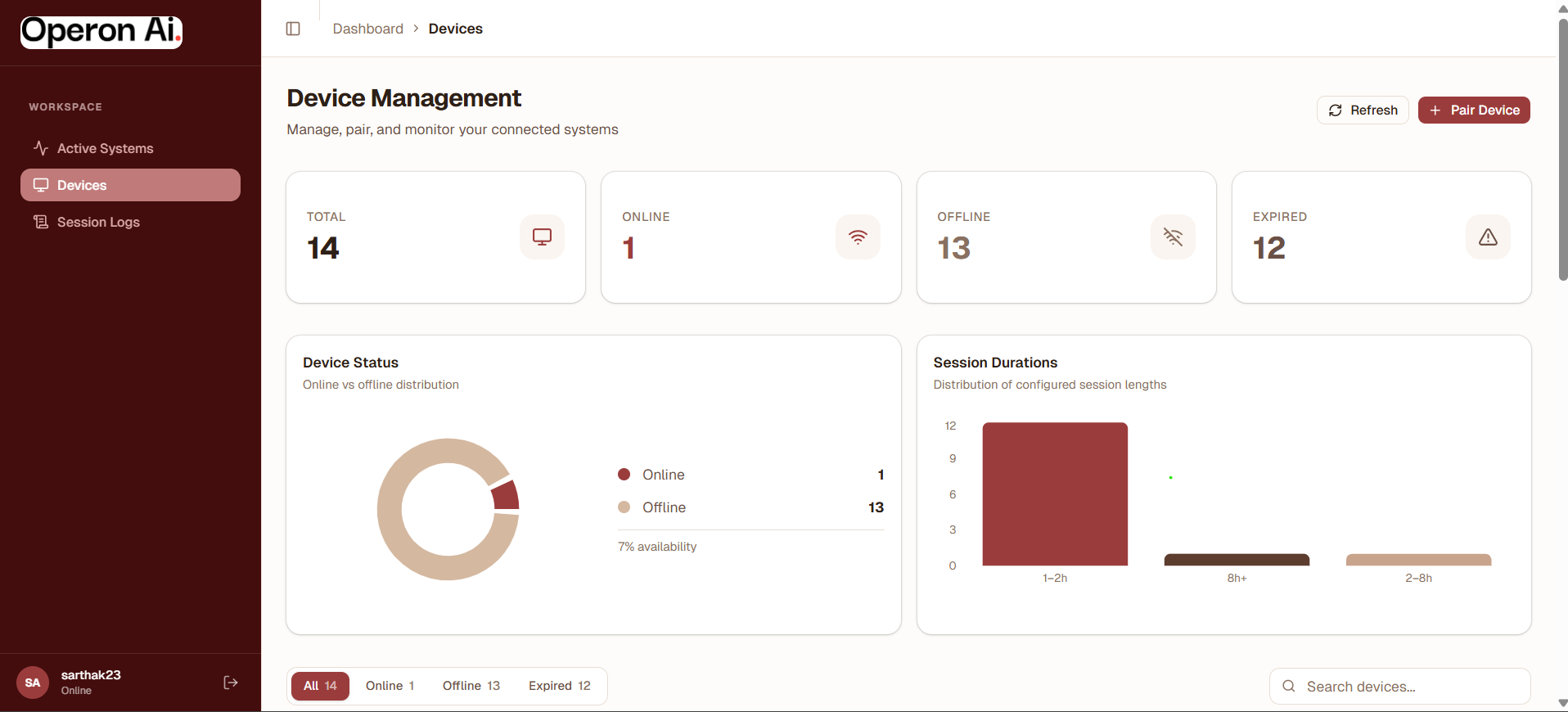
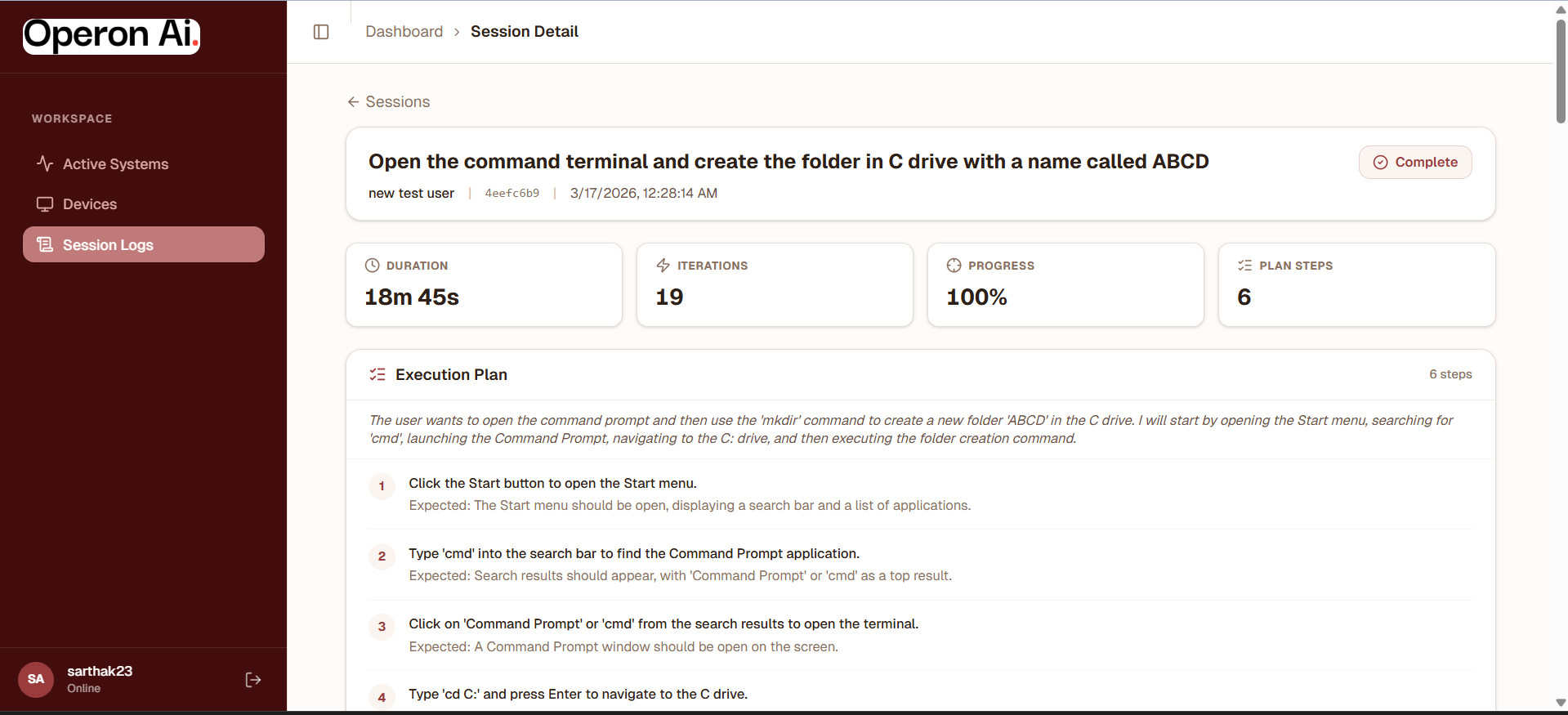
- Session logging and monitoring: All agent actions are recorded for transparency and debugging.
Operon AI enables automation across any interface, even when APIs or DOM access are unavailable.
Potential Applications:
UI automation · Software testing · Accessibility tools · Productivity assistants · Cross-application workflow automation
How we built it
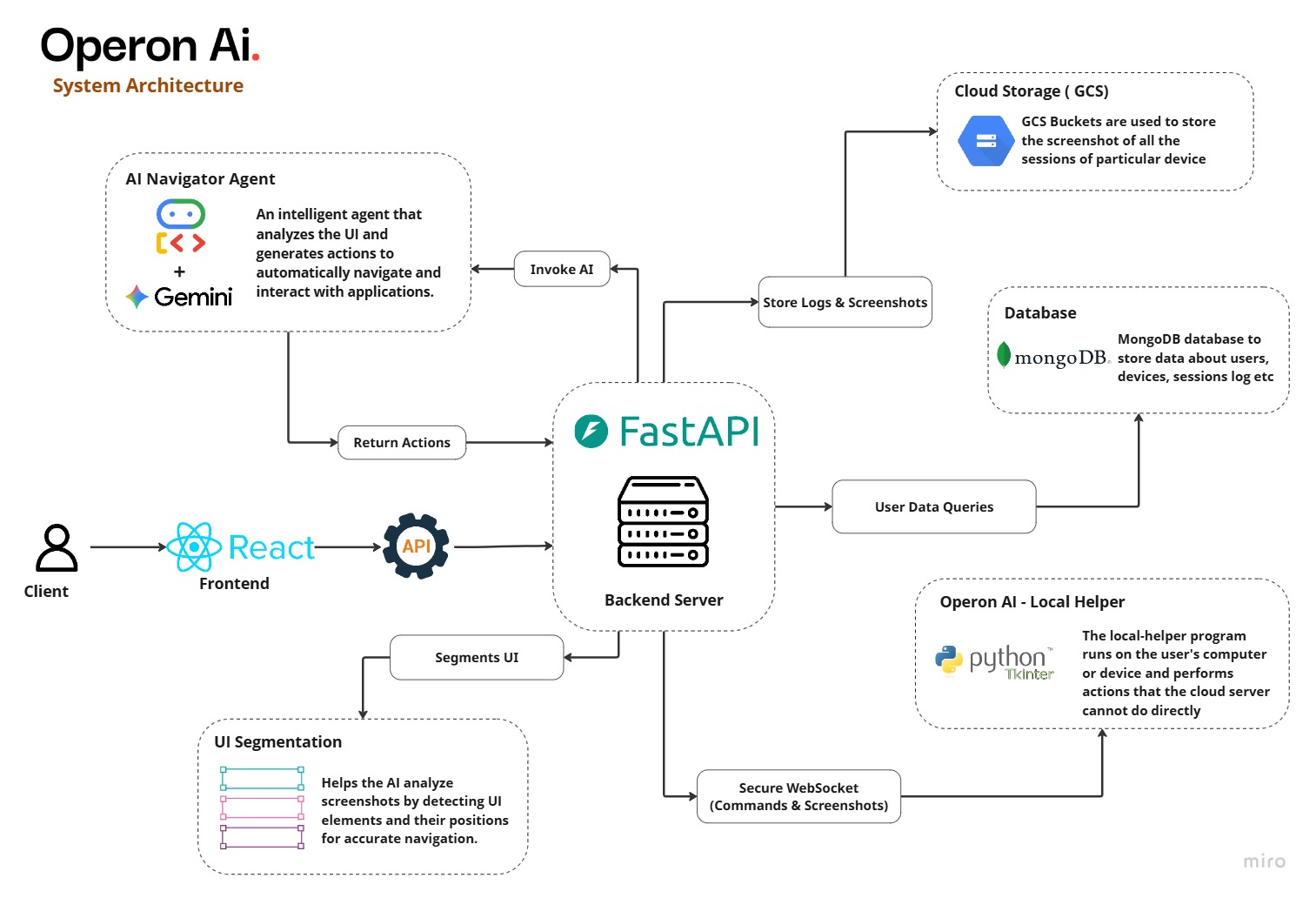
Operon AI was designed as a modular AI agent system with a full perception-planning-execution loop.
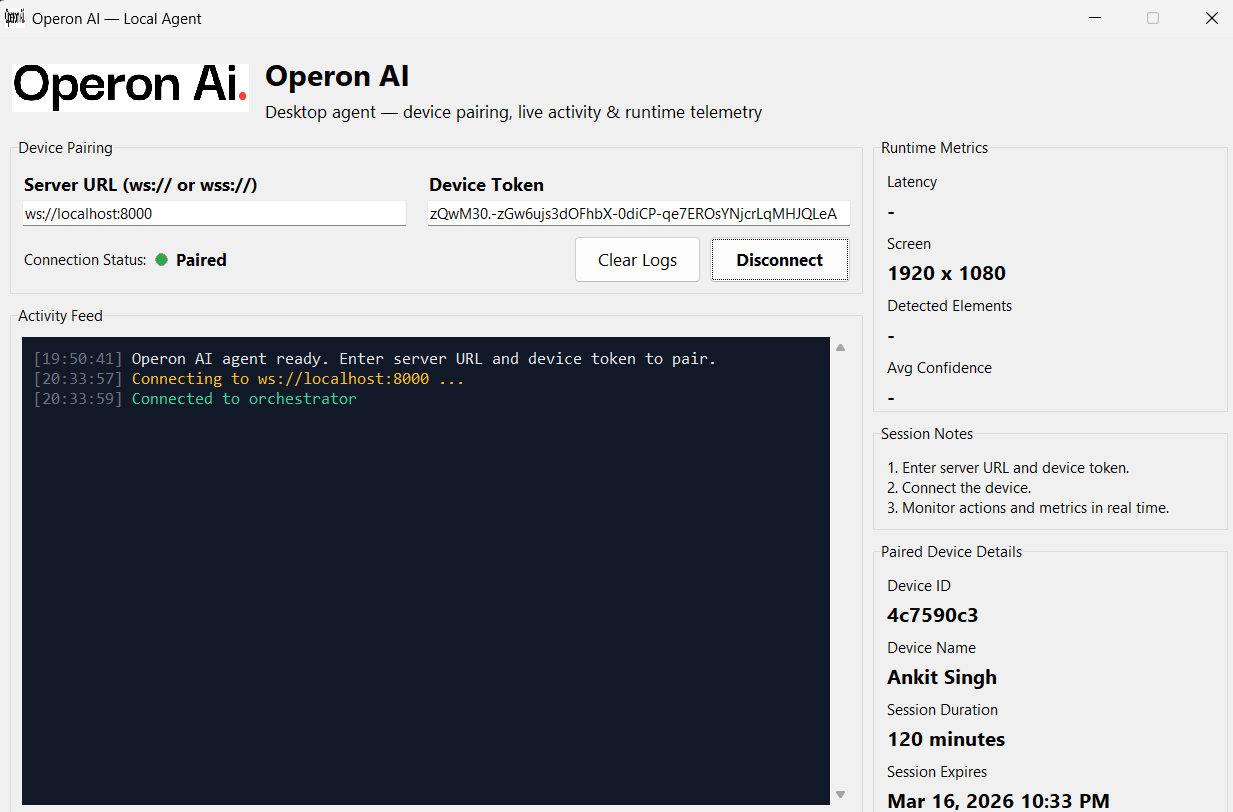
Frontend Dashboard
The user interface provides a centralized control hub built with modern web technologies.
- Features: Manage connected devices, start sessions, control the agent via voice, and monitor activity/logs in real-time.
Backend Agent Architecture
The core AI system is implemented in Python and follows a rigorous autonomous reasoning loop. The agent pipeline consists of four major stages:
1. Perception
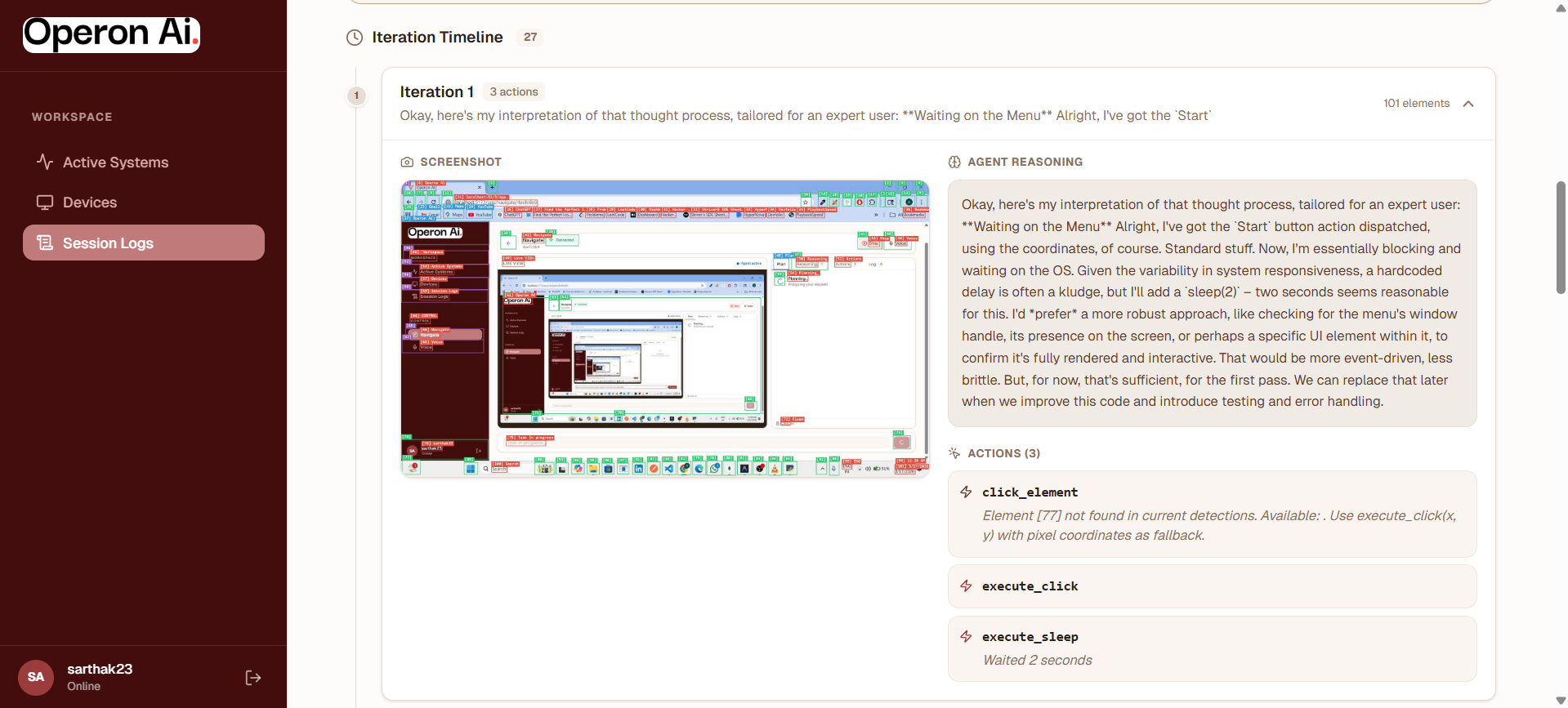
The system captures screenshots of the interface and performs UI segmentation to detect interactive elements (buttons, menus, input fields). This converts the flat UI into structured data for the agent.
Note: To evaluate the accuracy of bounding box overlaps during segmentation merging, we rely on Intersection over Union (IoU), calculated seamlessly in the pipeline: $$ IoU = \frac{\text{Area of Overlap}}{\text{Area of Union}} $$
2. Planning
Gemini analyzes the screenshot and the user's goal to generate a step-by-step action plan. The plan is converted into a structured action schema for execution.
3. Action Execution
The agent executes actions using a lightweight Local Helper service deployed on the target machine that securely performs OS-level:
- Mouse clicks
- Keyboard inputs
- Navigation
4. Verification
After each action, the agent verifies whether the expected interface state has been achieved. If the goal is not completed, the system continues the reasoning loop until the task is finished.
Tech Stack
| Domain | Technologies | Purpose |
|---|---|---|
| Frontend | React, TypeScript, Vite, TailwindCSS, shadcn/ui | Dashboard UI, Real-time monitoring, Voice capture |
| Backend & AI | Python, FastAPI, Gemini API, YOLO, EasyOCR | Core reasoning, API Orchestration, Vision Pipeline |
| Execution Layer | Python, WebSockets, Tkinter | Remote device control and OS-level automation |
| Infrastructure | GCP (Cloud Run, GCS), Docker, Terraform | Scalable cloud hosting, IaC, and Session Storage |
Cloud Infrastructure
The backend infrastructure is robustly deployed on Google Cloud Platform (GCP) using Terraform for Infrastructure as Code (IaC).
Key Components:
- Google Cloud Run: Serverless hosting for the agent backend, scaling instantly.
- Artifact Registry: Secure storage for our optimized Docker container images.
- Cloud Build: CI/CD pipeline building and deploying new versions automatically on Git push.
- Google Cloud Storage: Durable persistence for session data, screenshots, and logs.
- Terraform: Automated, reproducible provisioning of all cloud resources.
Challenges we ran into
Building an autonomous UI agent pushed us to the cutting edge, presenting several unique hurdles:
- Visual ambiguity: Unlike structured APIs, interfaces vary widely across applications. Detecting interactive elements reliably required extensive experimenting with segmentation and visual reasoning approaches.
- Planning reliability: Ensuring the AI generates correct and safe action sequences required implementing rigorous verification mechanisms and strict structured action schemas.
- Real-time responsiveness: Handling screenshots, AI reasoning, and action execution natively requires extremely low latency. We had to optimize WebSocket streams and parallelize vision inference.
- Cross-device interaction: Creating a system that can control interfaces across different operating systems required building an isolated local helper service that captures screens and executes actions securely.
Accomplishments that we're proud of
We are immensely proud to have built a fully working, real-time autonomous UI navigation system.
- Executed a complete perception → planning → execution → verification agent loop.
- Delivered real-time voice-controlled UI navigation natively.
- Built a gorgeous device management dashboard with session logging and replay for debugging agent behavior.
- Successfully integrated Gemini's multimodal reasoning loop with real-world OS-level interface control.
This project demonstrates how AI agents can move beyond simple chat interfaces and begin directly operating our software environments.
What we learned
Through building Operon AI, we learned incredibly valuable lessons about designing autonomous agents:
- Multimodal AI integration and crafting prompts that mix spatial and semantic data.
- Agent architecture design focused on robust fail-states and continuous execution.
- Cloud deployment and scaling using Google Cloud and Terraform.
Most importantly, we learned how to design systems where AI does not just generate text, but actively interacts with and manipulates digital environments.
What's next for Operon AI
We see Operon AI as the very first step toward ubiquitous autonomous digital assistants.
Future Roadmap:
- More granular and accurate UI element detection logic.
- Cross-application automation workflows spanning multiple completely different softwares.
- Memory-based agents that actually learn and adapt to user preferences over time.
- Expanded support for diverse mobile and desktop operating systems.
- Collaborative multi-agent systems sharing context.
Our long-term goal is to build AI agents capable of fully operating computers and digital environments autonomously, entirely delegating the busywork of modern computing to AI.
Built With
- artifact-registry
- easyocr
- fastapi
- gcp
- gemini
- google-adk
- google-cloud-run
- google-cloud-storage-(gcs)
- mongodb
- native-os-libraries
- python
- react
- shadcn/ui
- terraform
- typescript
- ultralytics-yolo
- websockets



Log in or sign up for Devpost to join the conversation.