-
-
Problem
-

Solution
-
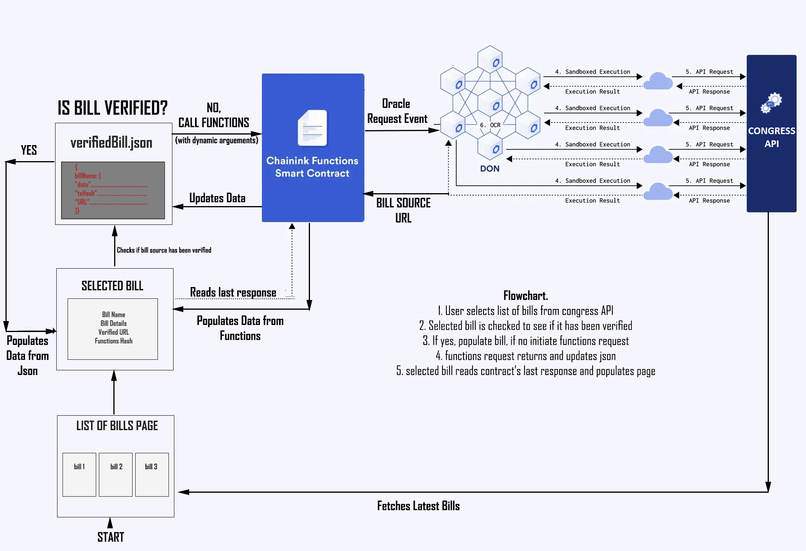
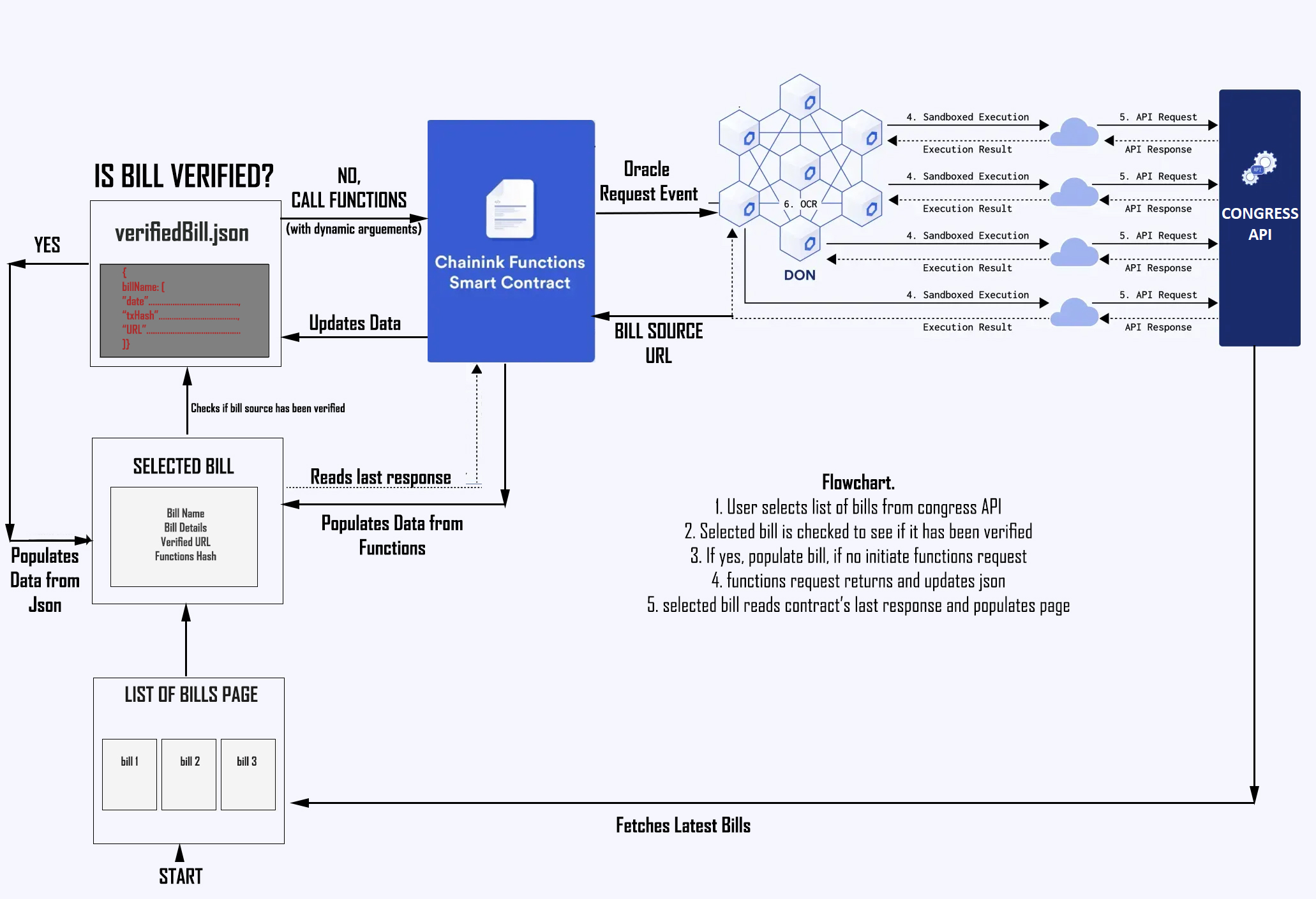
Flowchart
-

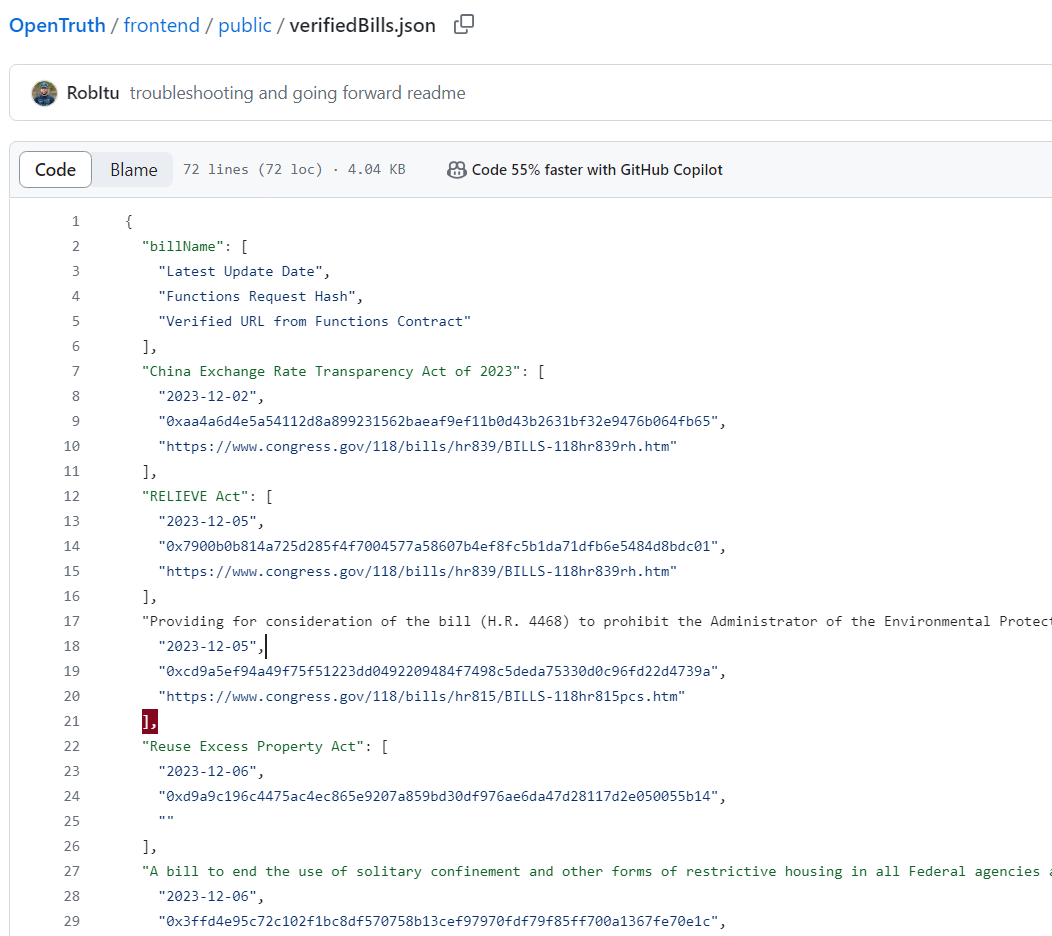
verifiedBills.json
-

Homepage
-

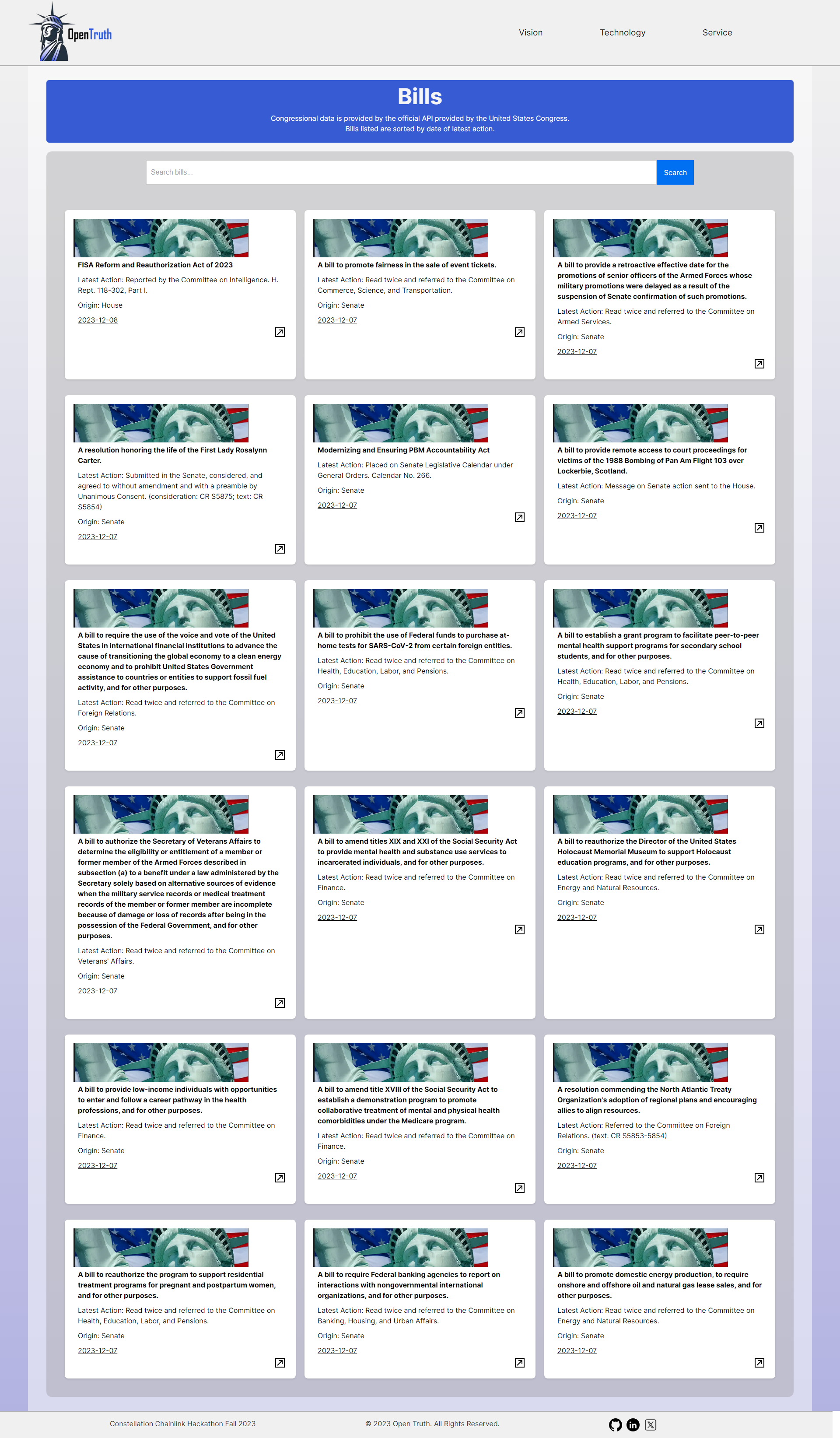
Bills (18/250 shown)
-
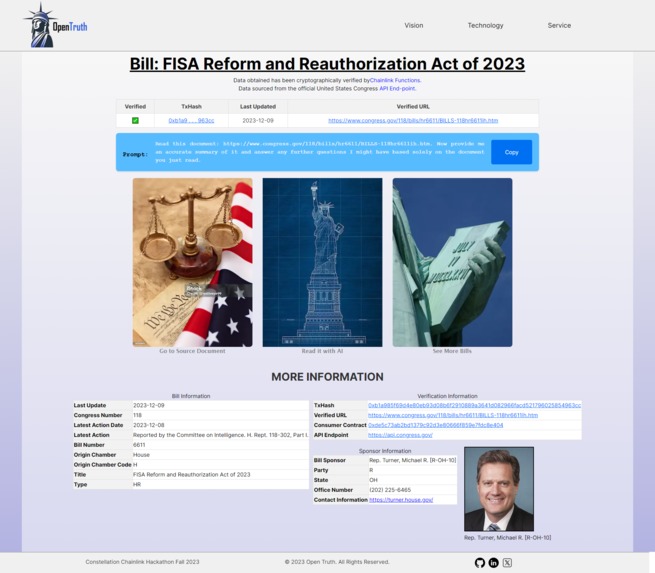
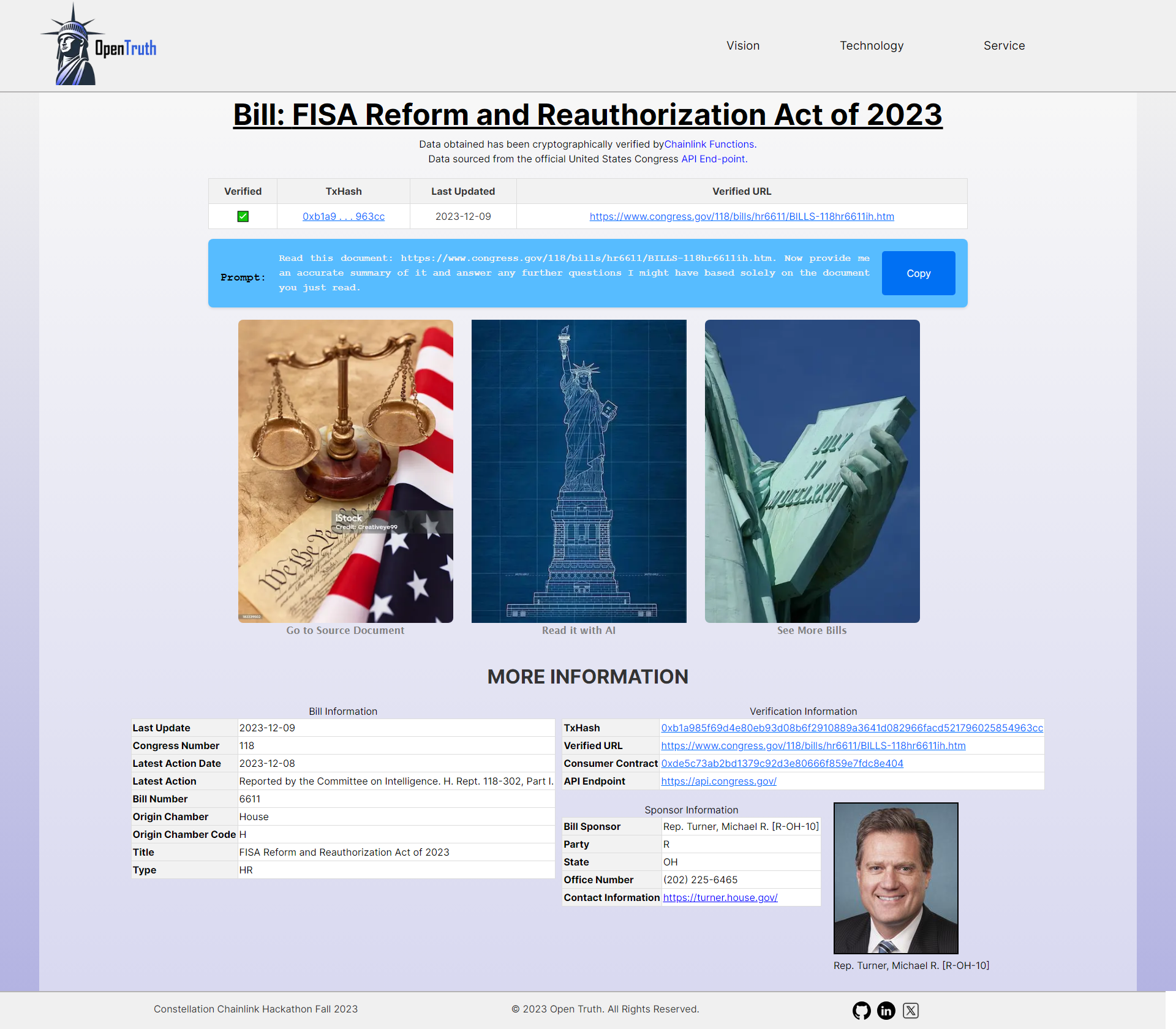
Selected Bill Page (after functions request)
-
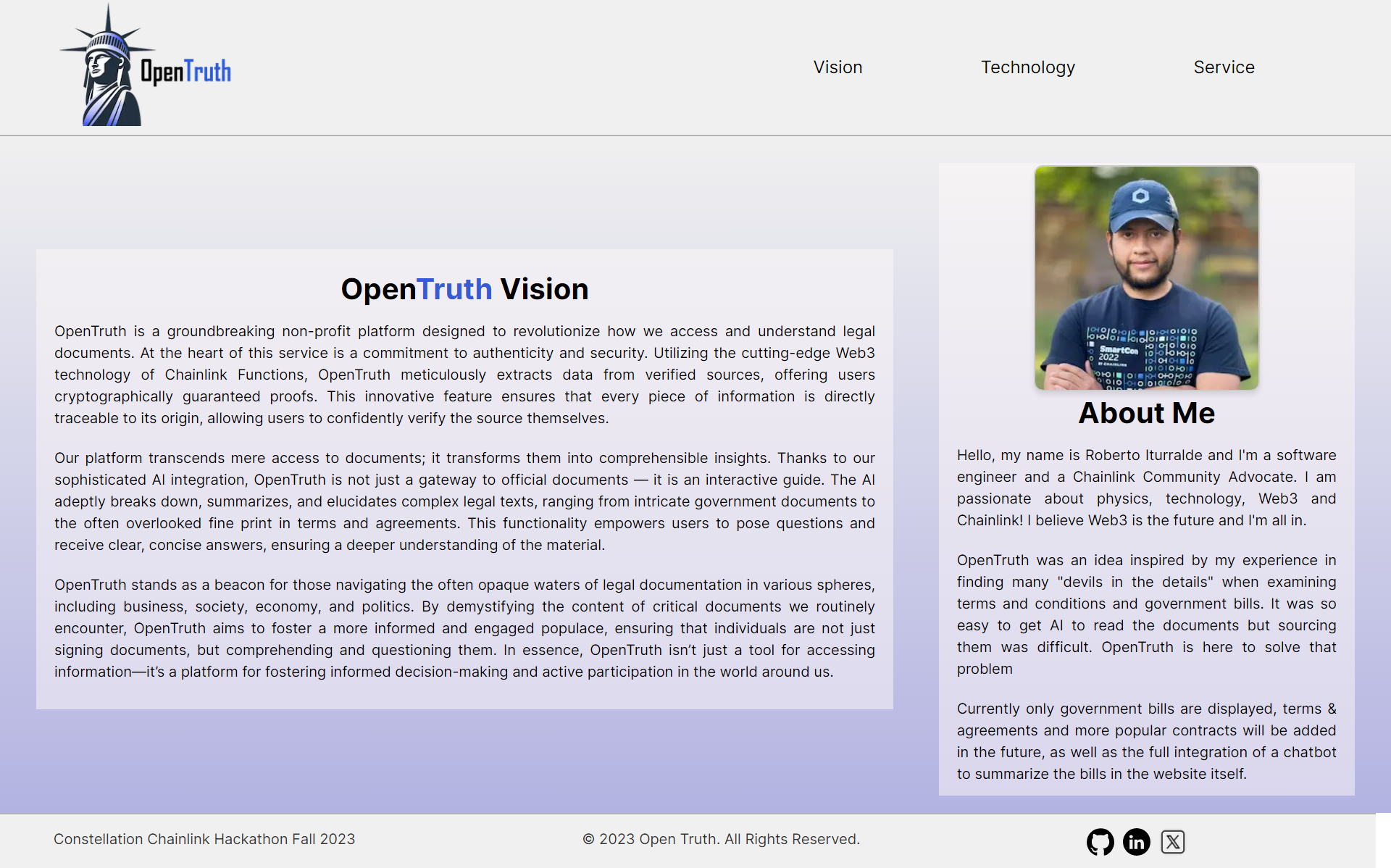
Vision
-

Technology
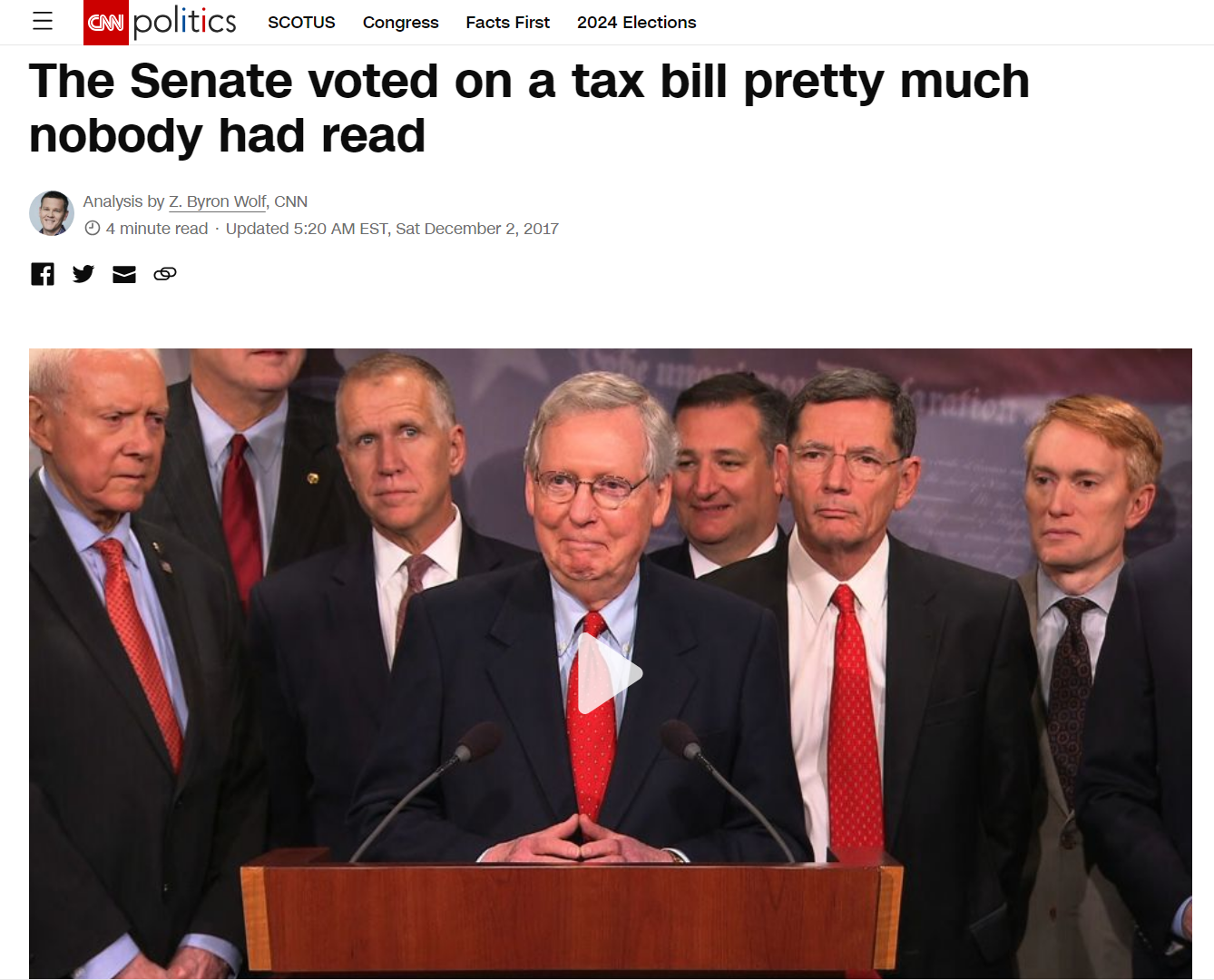


Inspiration
Over the years I have seen the inefficient manners that bills are passed in our political system. They can be too long and complex, for politicians and citizens alike, to read before voting occurs. Furthermore, within these huge volumes of text, there exists many fine details that are usually never mentioned and can have a critical impact on our monetary policy, society, foreign and/or domestic affairs, and much more.
Using AI, I discovered that I could feed it the document's text and finely comb through it, finding vast amounts of details that are usually never spoken of. With this, I got the idea to create a platform for everyone that was interested in digging deep into the legal documents that can impact all of our lives. With Chainlink Functions that cryptographically and verifiably sources the data and the abundance of AI models, a synergistic relationship was formed that is now OpenTruth, to produce unbiased and accurate breakdowns of legal documents.
What it does
OpenTruth accomplishes two things:
- Cryptographically and verifiably sources the legal document's data using Chainlink Functions
- Feeds the verified source to an AI that can break it down comprehensively.
First, it will present a list of the most recently-worked on bills to the user (upwards of 200+ bills). When a user selects a bill, the function's verification process begins if it is needed and will display verified bill data to the users as well as transaction hash, consumer contract and function's response so that they verify themselves where the source of the data came from.
It also automatically produces a prompt with the verified source of the bill's text so that it can be easily fed into any AI model such as ChatGPT or Bing Copilot.
How we built it
Chainlink Functions: The role of Chainlink's function is to fetch the text version of the bill from the official United States Congress API endpoint. This will return a URL for the text version that can be fed into any AI.
Dynamic Chainlink Functions Fetching: The
source.jsfile that hosts the target api-endpoint that functions will fetch has been designed with placeholders to be replaced with dynamic arguments. These dynamic arguments (congress number, bill number, bill type) can find any bill in the congress system, therefore allowing OpenTruth to verify any bill, at any time with no change or effort needed whatsoever from the user.Functions Request Script: The functions request script has been altered to accept dynamic arguments and rewrite the
source.jsfile before officially mounting it in the request transaction that will ping the consumer smart contract to initialize the fetch request.Express API: The express API was crucial for this project as it acted as the connection between the front-end and the back-end. Since NextJS cannot execute server-side commands, it relied on calling the express api endpoints. The endpoints in express serve two functions:
- Initiate Chainlink Functions Request
- Update verifiedBills.json data
verifiedBills.json: In order to not unnecessarily call Chainlink Functions and to save blockchain's resources, the verifiedBills.Json file was created. It will save the data of any bill that has been verified.
NextJS: NextJS was used to power the front-end and make the api calls to the congress website to display the list of bills and also to make calls to the express api server whenever there needed to be an update in the verifiedBill.json file and to initiate the functions request to verify the bill's text source.
ChatGPT/Bing Copilot: AI models that can be used to read through the document's text and summarize/answer any questions users might have on the bill. From my experience, it has been very accurate and you can ask many sorts of questions and the answers will be based solely from the bill.
Prompt: A prompt is automatically created for the user to copy so they can paste it in any AI model they choose. The prompt is populated with instructions for the AI to just read the bill's text. It has also been populated from the verified bill's source coming from Chainlink Functions.
Data tables: There's also data tables holding information about the bill, the bill sponsor (and a way to contact them in case you find something concerning in the bill) and verification links/details so that anyone can verify that the data source is authentic.
Challenges we ran into
Most of the challenges that I faced while making this project were resolved, however some of them still persist. Connecting the frontend to the back was very challenging until I learned how to make an express api endpoint/server. I faced a lot of issues with NextJS caching in responses when an api call was made, meaning that I would get the same response when it should've been different.
I faced challenges with NextJS executing useEffect functions twice, possibly due to client-side and server-side rendering processes. I also faced issues with the official congress website not updating their bills with a text version on time, however there was nothing to do for this but wait.
All in all, most of these issues were resolved and I learned a ton.
Accomplishments that we're proud of
There are so many things I am proud of in this project. This is my first time building an application at this level. This is a list of some but not all accomplishments I'm extremely proud of:
- How to execute node commands using express api endpoints (and how to set an express server)
- Designed Chainlink Function's request script and source file to accept dynamic arguements
- Passing dynamic arguments from the frontend to the back
- Creating a functioning webpage that doesn't look bad
- Using multiple API endpoints
- How efficient and clean some of the code is
What we learned
I learned a ton during this project. On a technical level, I learned that things not always go as planned but there is most likely always a way to achieve the goal that you wanted. I learned about API calls, express servers, Chainlink functions, NextJS development, Web3 contract reading and much more. Personally, I learned that during these high stress periods, exercise and self-care are paramount and the energy that you put into yourself will naturally reflect on the work that you produce.
What's next for OpenTruth
The next steps for OpenTruth are:
- Bug fixing
- Mobile capabilities
- More legal documents (terms and agreements, contracts, etc)
Built With
- chainlink
- express.js
- functions
- nextjs
- node.js


Log in or sign up for Devpost to join the conversation.