-
-
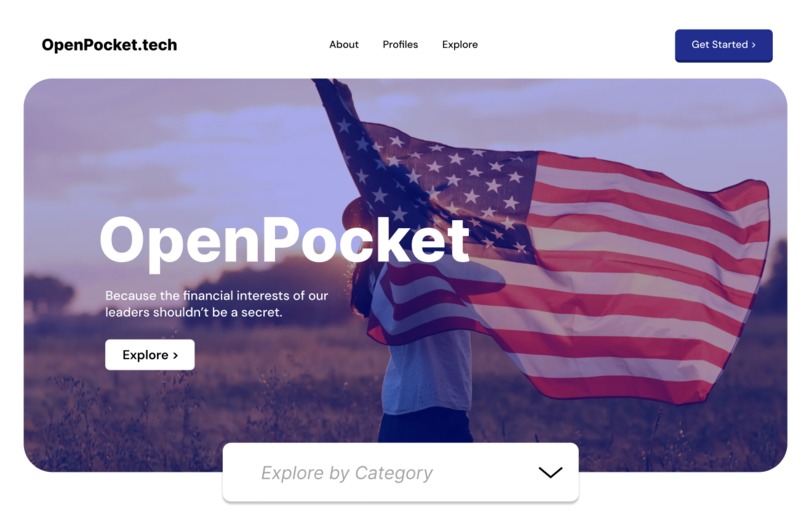
Landing Page
-
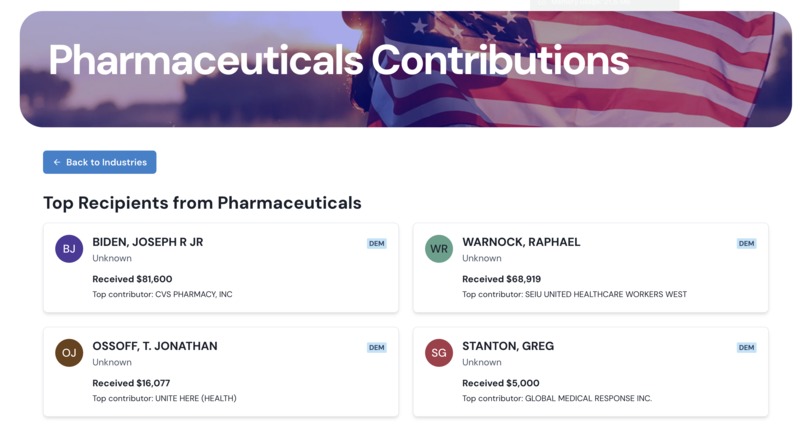
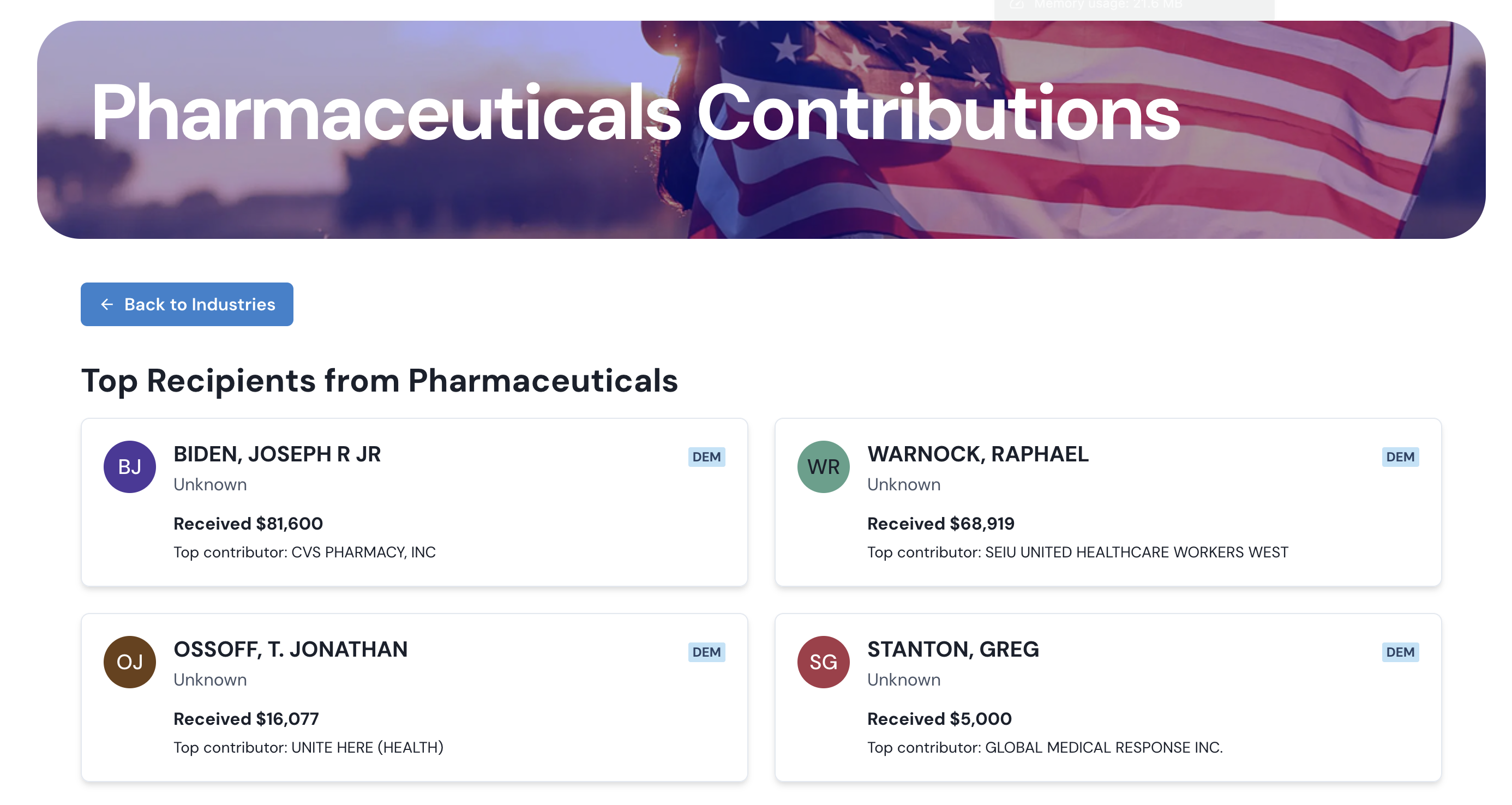
The politicians with the biggest donations from pharmaceutical committees
-
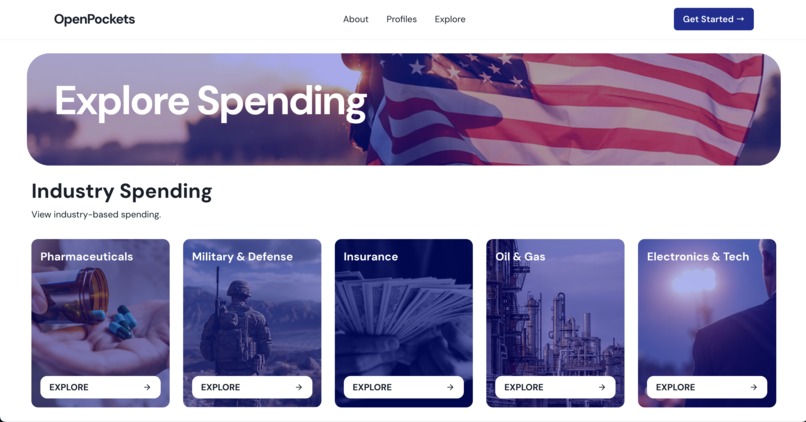
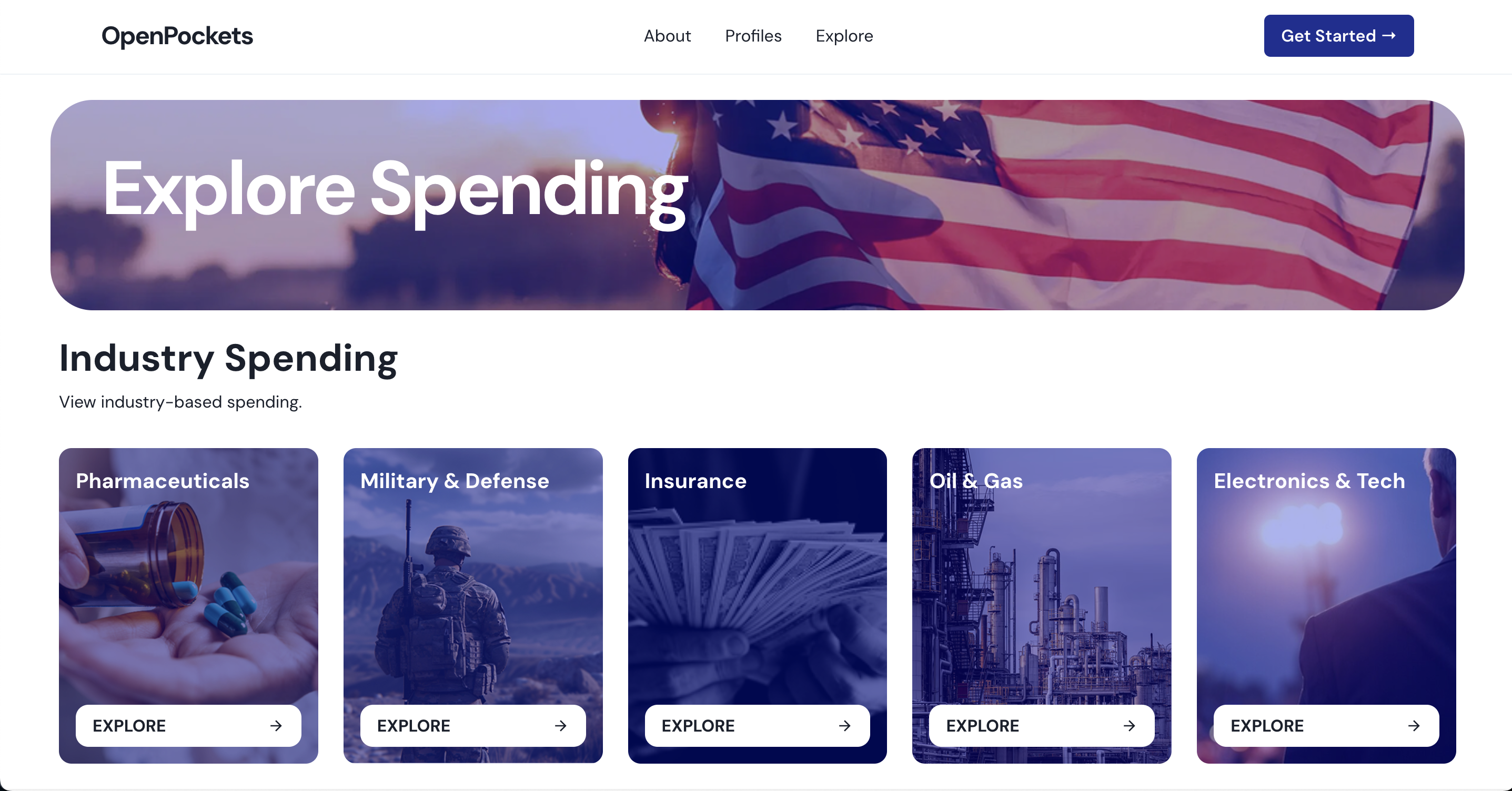
Spending by Industry
-
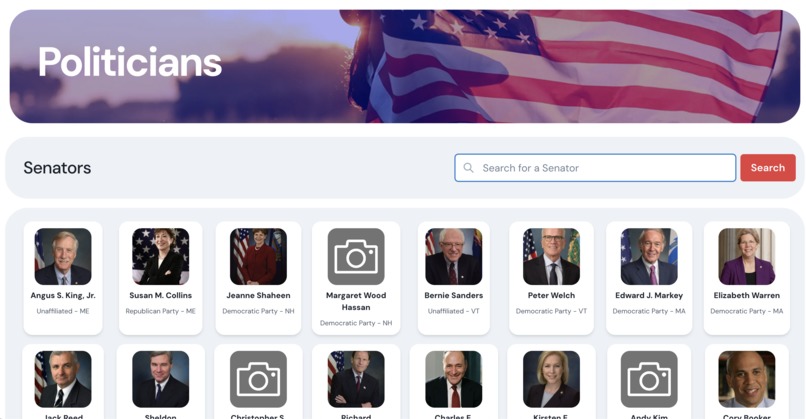
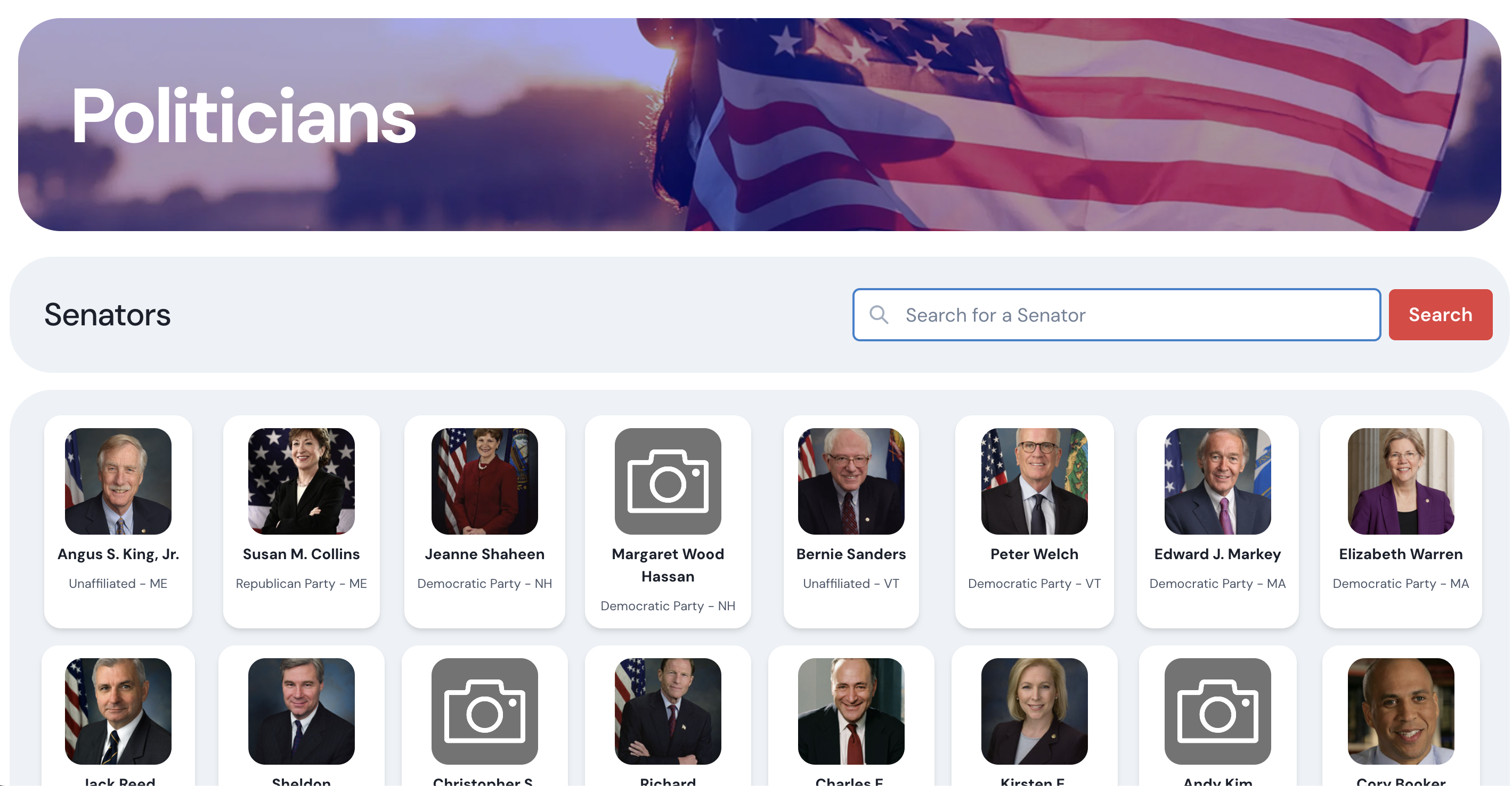
A politician profile page where you can filter by senators and click to learn more
OpenPockets
Inspiration
Both of us recognized that the United States is currently in a politically complex and pivotal moment. We saw an opportunity to make a meaningful impact by helping people better understand the flow of money in politics. In the U.S., Super PACs and PACs wield significant influence over the political landscape, often shaping outcomes behind the scenes.
What it does
Our website OpenPockets sifts through massive bulk data downloaded from the Federal Election Committee (FEC) to track, analyze, and visualize political campaign contributions. Our platform allows users to:
- Explore contributions by industry sectors like Pharmaceuticals, Military & Defense, Oil & Gas
- View detailed profiles of politicians with their funding sources
- Track industry influence across different senators and representatives
- Visualize financial relationships between corporations and politicians
How we built it
Lots and lots of struggling and revision.
Back-end
- Developed a Node.js/Express server to handle API requests efficiently
- Used a SQLite database for fast querying
- Implemented data processing pipelines to transform raw FEC data into insights
- Created specialized endpoints for industry-specific and candidate-specific queries
### Front-end We used Figma to prototype and React, ChakraUI, and TypeScript for rapid development.
Challenges we ran into
- The text files we dealt with were massive (as in gigabytes). Unfortunately, MongoDB ran out of storage after attempting to add our first table. After talking to teammates around us, we learned that SQLite is great for parsing relatively large data and decided to switch. This entailed MUCH faster queries.
- As of April, every government related API was shutting down or was already shut down perhaps due to recent government cuts. The OpenSecrets API was unavailable, OpenFEC had a limit of 40 calls/hour, congress.gov’s API was broken, Google Civic API was very limited and extremely slow and ProPublica's Congress API is no longer available. So we decided to just store and parse all the data ourselves with SQLite. The queries were extremely fast and understanding the syntax grew easier by the end
- We had never queried data so big before, or really queried in general. Our computer would crash if we even tried to open one of the .txt files
- We also are not political science majors so the jargon was tricky to understand.
Accomplishments that we're proud of
We accomplished this much as a team of 2. Of the 4 APIs we planned to use, only one somewhat worked, and even then, we decided to scrap it and do it ourselves by downloading a bunch of campaign data and essentially making our own personalized api. We messed with a ton of technologies that we had no idea about: Model Context Protocol, SQLite databases
What we learned
Extreme improvisation: having all the API’s fail on us, and then deciding to just build it ourselves was a cool experience
What's next for OpenPocket
One of our biggest limiting factors was the deactivation of the OpenSecrets API, which is one of the biggest tools in tracking political finances. This API will come back new and improved soon, and it is a very potent tool for us to leverage to gain insight on political transactions. One of the biggest features we wanted to implement was a Gemini agent that worked off of a Model Context Protocol server connected to our database to answer any questions about a politician's financial integrity. We were successful in creating it, but not so much in integrating it into our front-end. We also created methods to see a politician's active industries and a list of their highest donating political action committees, but we weren’t to integrate it into our ui at the end.
Built With
- axios
- chakraui
- express.js
- gemini
- googlecivicapi
- node.js
- openfec
- react
- sqlite


Log in or sign up for Devpost to join the conversation.