-
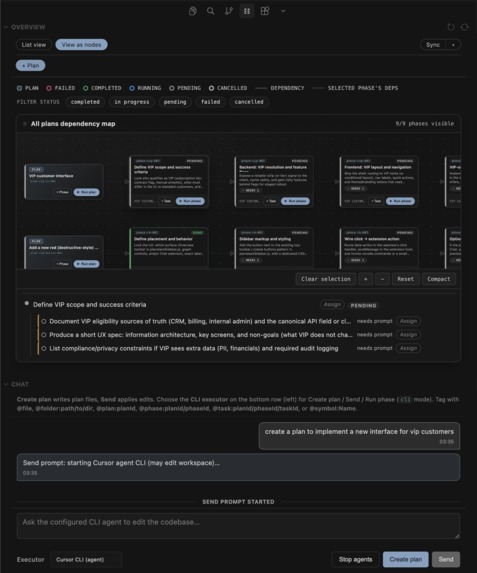
Nodes and graph view
-
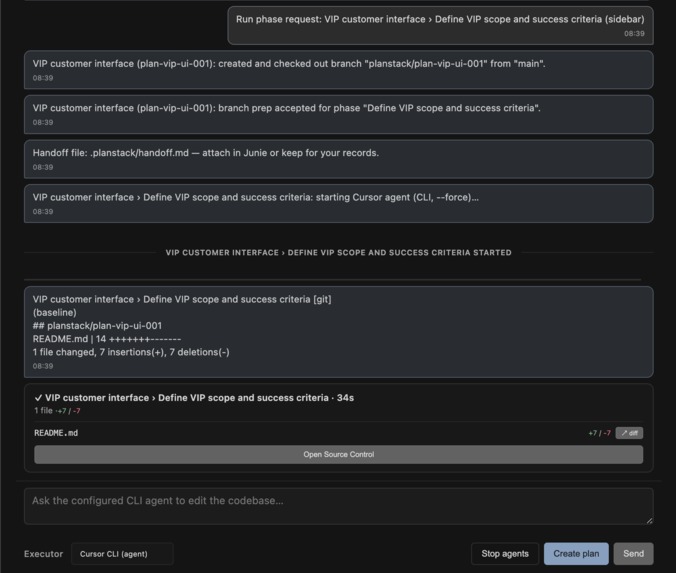
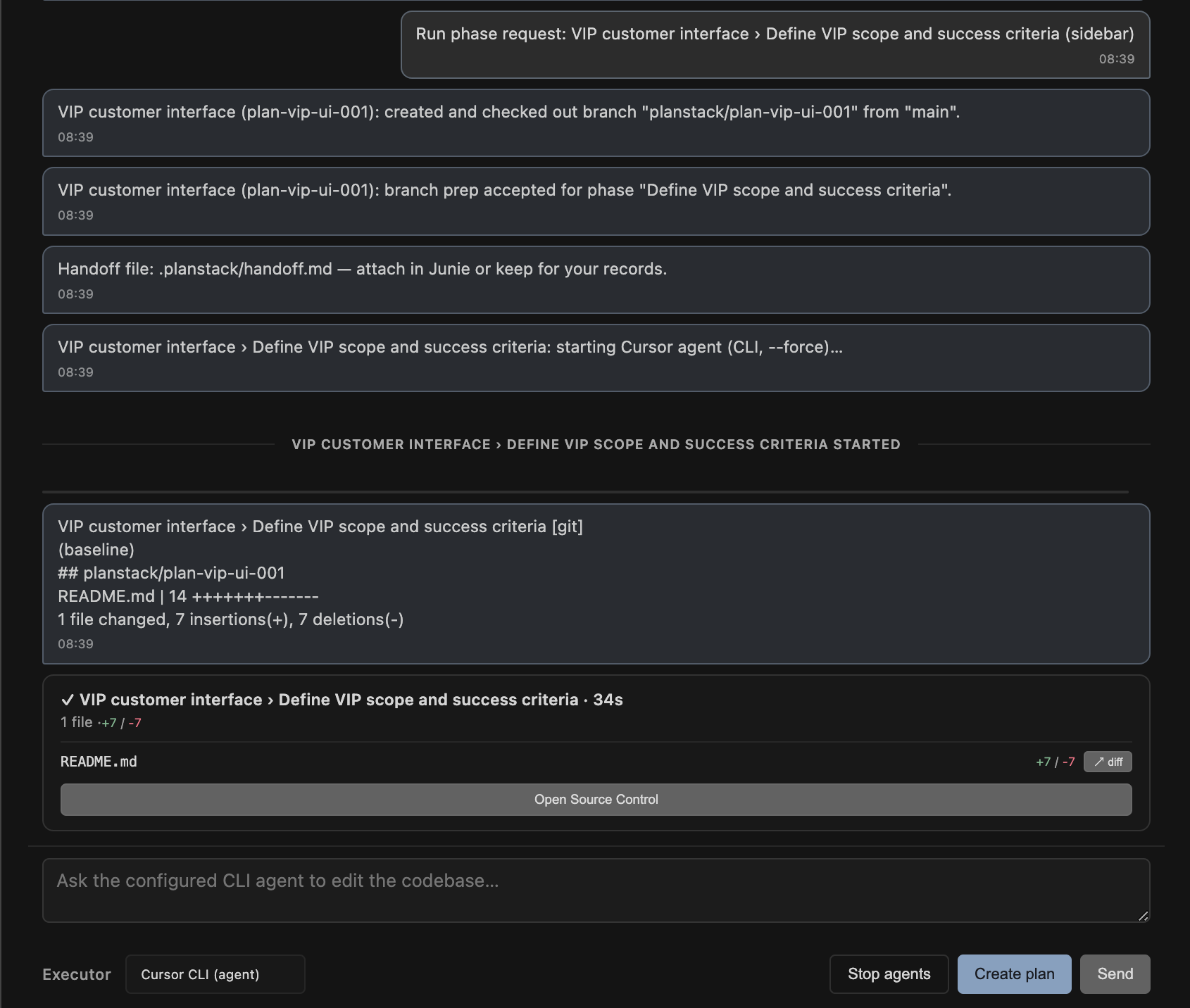
Chat phase execution with final git diff
-
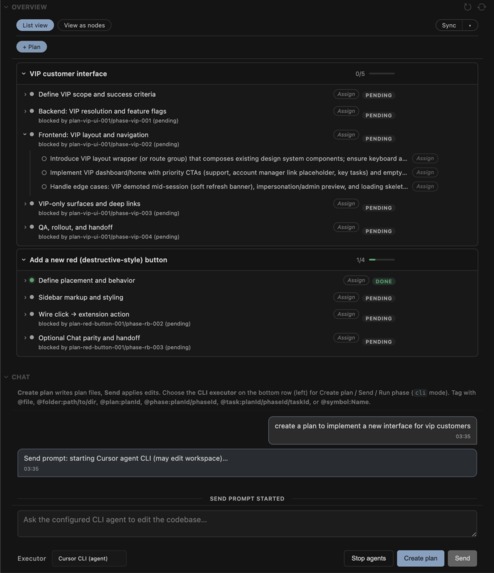
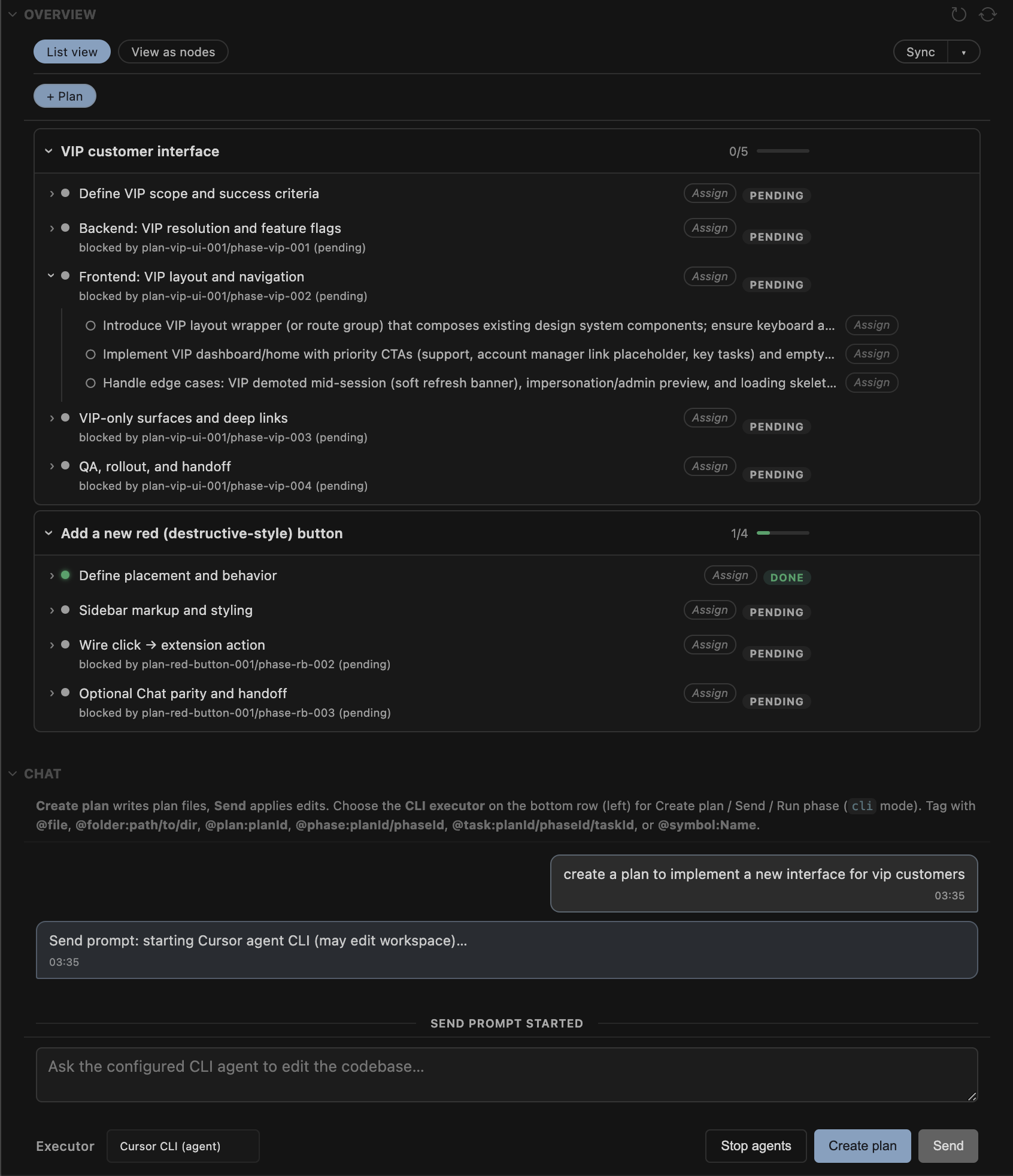
Plans, phases and tasks tree view
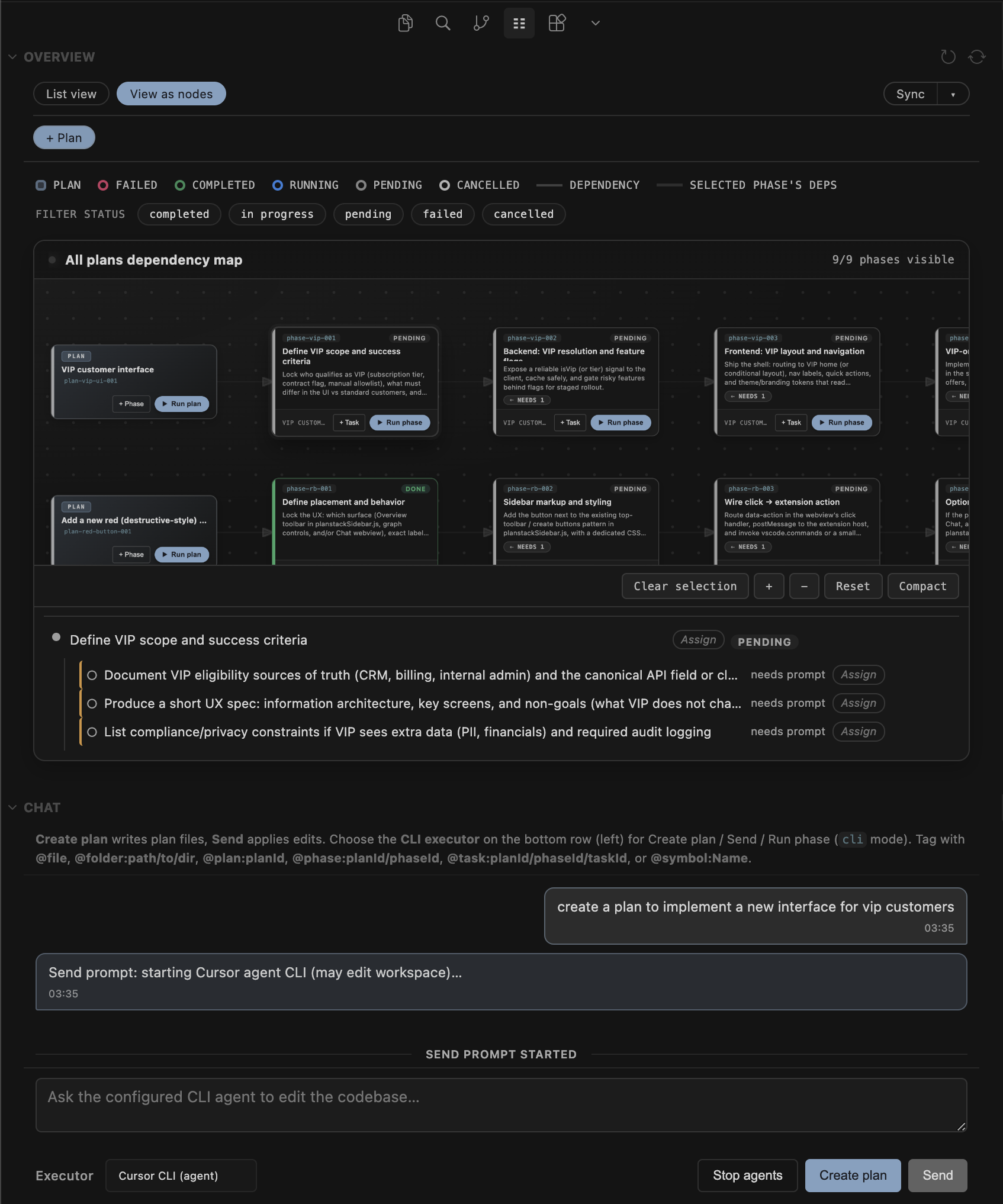
Inspiration
The starting point wasn't a product thesis on a whiteboard. It was the grind of actually using AI agents inside IDEs day after day.
You bounce between chat, terminal, files, and whatever the agent touched last. The "plan" lives in fragments: a few messages up-thread, a comment you almost wrote, a mental checklist that made sense at 11pm and doesn't survive the morning. When you pick the work back up, you spend the first twenty minutes re-establishing context instead of moving the thing forward.
We built OpenPlanner because that friction kept showing up in our own workflows. Not as a one-off hackathon annoyance, but as the recurring cost of collaborating with a fast, forgetful pair programmer inside an editor that wasn't really designed to hold intent between runs.
What it does
It's a Cursor / VS Code sidebar extension that turns "we should do this" into a small structured tree.
Plans, phases, and tasks are plain JSON under .planstack/plans/. Everything uses the same handful of states (pending, in_progress, completed, failed, cancelled), and parent nodes reflect what's happening underneath so you're not staring at a green checkmark while a child task is still stuck.
The sidebar shows the tree, badges for state, quick assignee edits, and buttons on each node. The chat panel does two jobs: help you draft a plan from a rough goal, and show execution as it happens (stdout/stderr from whatever runner you pointed at). Mentions (@file, @phase, @task, @symbol) pull in context with a fixed token budget so the prompt doesn't quietly balloon.
Running a phase builds a prompt and hands it off. Default path is the Cursor CLI agent; there's also a clipboard path if you'd rather paste straight into Composer, plus hooks for other runners later. Phase dependencies get checked when the file loads: no cycles, no pointing at ids that don't exist, no "depends on myself" nonsense.
MongoDB Atlas sync is optional and intentionally dumb (last-write-wins, bump a revision counter). Disk stays canonical. After a run we drop a short git diff summary into chat so you get a sense of what moved without pretending we're a diff tool.
Scope line in one sentence: we care about intent and handoff up to execution. The agent still does the editing; we're not rebuilding review UI.
How we built it
Single VS Code extension, TypeScript end to end, nothing fancy in the toolchain. Dispatch goes through one small router: CLI by default, clipboard handoff for native-first people, placeholders where a tighter SDK integration would slot in later.
Plans are files. A watcher reloads when something else touches the directory (another machine, a script, you in vim), which keeps AI-written JSON and hand-edited JSON on the same footing. Writes go through a temp file + rename so you don't end up with a torn-in-half JSON if the process dies mid-save.
Chat and tree are webviews; they message the extension host like everyone else. Agent output doesn't go straight into the UI chunk by chunk. There's a thin buffer in the middle: coalesce bursts, keep a short replay for people who open the panel late, cap memory and say so when you truncate, and buffer until the webview has actually mounted so you don't lose the first half second of every run.
Challenges we ran into
Streaming was the rabbit hole. Firehose the webview and the renderer falls over; under-send and it looks frozen. We ended up coalescing on a timer, keeping a small ring of recent runs for replay, surfacing truncation explicitly, and fixing an annoying race where bytes arrived before the webview said it was ready (classic "works in the demo until you open chat a beat late").
Smaller paper cuts that still cost afternoons: the extension host doesn't see the same PATH as your interactive shell, so finding the agent binary wasn't trivial; we added a reservation lock so two "run" clicks can't spawn two processes in the same gap; and a heartbeat so a hung silent child doesn't masquerade as success forever.
Accomplishments that we're proud of
JSON on disk sounds unsexy until you try the alternatives. You can grep plans, commit them, diff them in PRs, or DM someone a single file and have them running your stack minutes later. External generators and our own chat produce the same artifact; the loader doesn't care who wrote it.
We deliberately avoided a shadow copy in extension global state. One source of truth removed a pile of "why doesn't the tree match the file?" bugs.
What we learned
Webviews punish naive streaming. Coalescing, replay, caps, and init ordering aren't polish; they're the difference between "this feels broken" and "this feels alive."
File-backed plans beat clever in-memory mirrors. The moment we treated RAM as authoritative, drift showed up. Disk won.
Even a solo dev tool has concurrency edges: overlapping runs, half-open races, dependency graphs that need validating up front. Boring fixes, but skipping them shows up as spooky behavior under demo load.
Integration beats reimplementation. We didn't try to replace Cursor's diff or accept flow; we hand off and get out of the way.
What's next for OpenPlanner
Collaboration beyond last-write-wins: who's editing what, maybe a lock per phase so two people don't kick off the same run, and a conflict story that isn't just "newest timestamp wins."
More backends behind the same plan file. Same JSON, different agent or CLI, so teams aren't married to one vendor's loop.
Longer term: better auto-planning from a single messy goal, optional background runs for slow plans, and summaries that actually read the diff instead of only counting lines changed.
Built With
- css
- cursor-cli
- html
- javascript
- json
- junie
- mongodb
- mongodb-atlas
- node.js
- typescript
- vscode


Log in or sign up for Devpost to join the conversation.