-
Postman Public Workspace ft. documentation
Inspiration
The UK Government provides a lot of open data on all aspects of the country, from crime data to financial data.
The majority of this data is usually stored within CSV files on their website and is typically updated daily, monthly or yearly.
We have found ourselves using this data in multiple hackathon projects and each time having to write an API to be able to access and analyse this data - this is why we have decided to spend time making a public API that can help future developers to be able to utilise the data easily.
What it does
It makes the UK Government data more accessible by providing JSON-based RESTful API endpoints for people to get/query data on all aspects of the UK.
How we built it
The the UK Government currently has a public api that can list all the datasets they have and you can also get info for any of the datasets it has. This info includes things like its name, description, format, but most importantly it includes a url for the data.
So firstly we have built an ETL service that can hit this already existing UK government API endpoint and parses the response to get the URL for the data file. With the URL retrieved, we then fetch the data using a HTTP GET request and we load this data into a pandas DataFrame, then we do a few steps to clean up the data a bit - so we drop any rows with empty values and we strip the spaces out of column names. Once the data is clean we then load it into an AWS DynamoDB table. This ETL service has been written in python and is deployed as an AWS Lambda Function triggered by AWS API Gateway. Security is ensured via API Gateway by validating API keys.
Secondly we have built a web API service that has multiple endpoints that can now query this data that has been clean and processed. This consists of a simple Python Flask service that has flexible endpoints representing the data a user can fetch from the relevant databases. It utilises the AWS SDK to pull, scan and filter the data based on the users parameters within the request that they have sent.
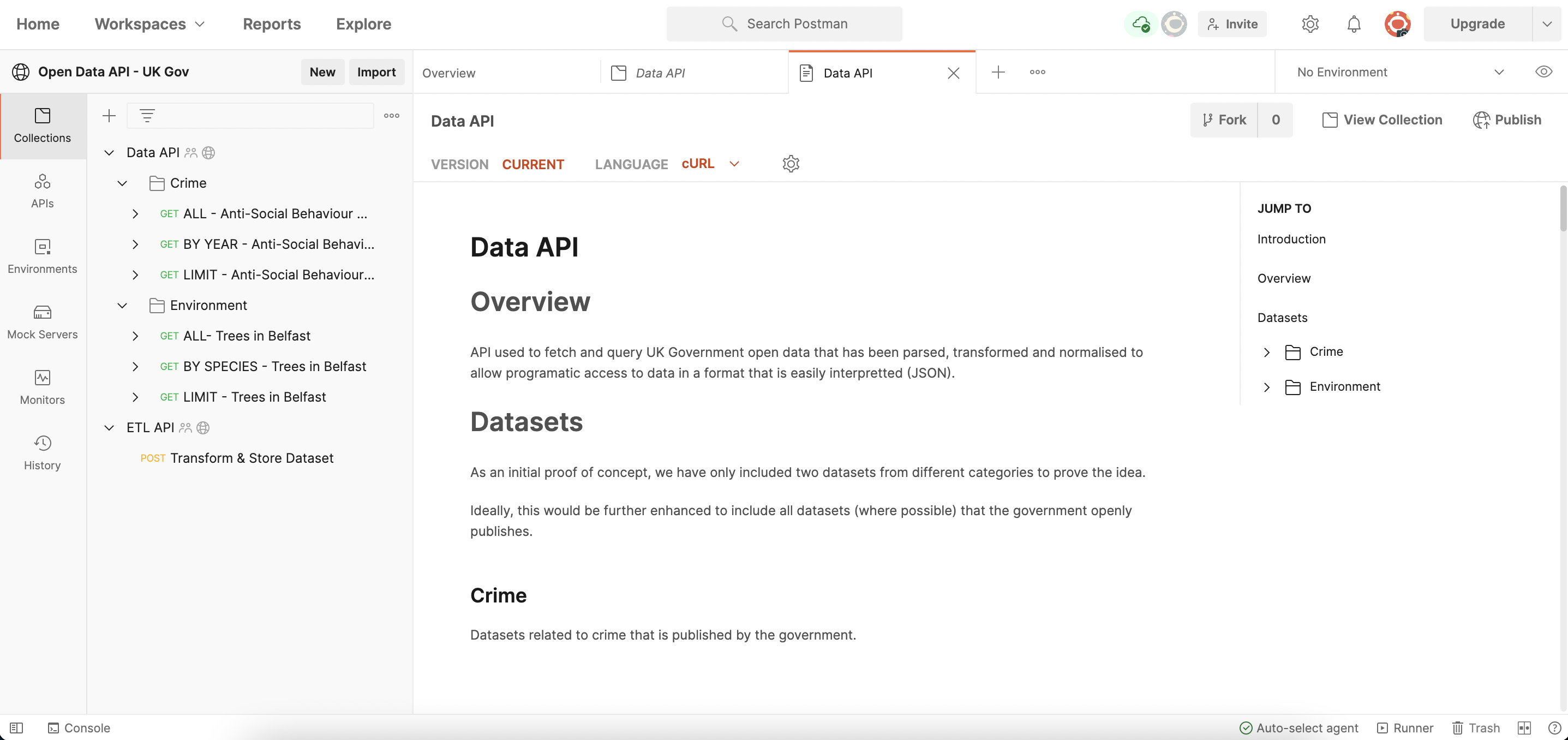
With these services created we where then able to set up a public postman workspace with all the endpoints required to hit our APIs and were able to add detailed descriptions and examples for each endpoint.
Challenges we ran into
One challenge in particular we ran into when writing the ETL services was that the Python library pandas was not included in the standard python lambdas runtime, to overcome this we discovered that we can use Lambda Layers on top of a function to access these additional libraries that we required.
Accomplishments that we're proud of
We are very proud of this whole project, a lot of the technologies we used were new to us, we have never used a Postman public workspace before, which was really existing and fun to do. We also do not have much experience in writing infrastructure as code, so being able to create all the AWS resources we required through the Serverless framework was both challenge and fun!
What we learned
We learned how to set up a public Postman workspace to share our APIs with the world and to provide clear documentation. The web interface for Postman public workspaces is incredibly powerful, allowing us to edit our endpoint documentation in real-time together as well as include examples of endpoint responses. These are powerful tools that can undoubtably ensure developers experience is as best as it can be.
We also learn a lot about creating Serverless architectures, parsing/working with large datasets and also creating restful APIs.
What's next for Opening Up Open Data
Currently, we have only got this set up for two datasets provided by the UK government website, our future goal would be to import more datasets spanning more than just the few categories we have and further down the line, we would like to explore the possibility of setting up a job to run nightly or weekly that could pull in the most recent data depending on how often the datasets get updated.
Built With
- amazon-web-services
- api-gateway
- dynamodb
- lambda
- pandas
- python
- serverless



Log in or sign up for Devpost to join the conversation.