-
-

Main screen
-
Sign-In/Sign-Up
-
Welcome Page
-
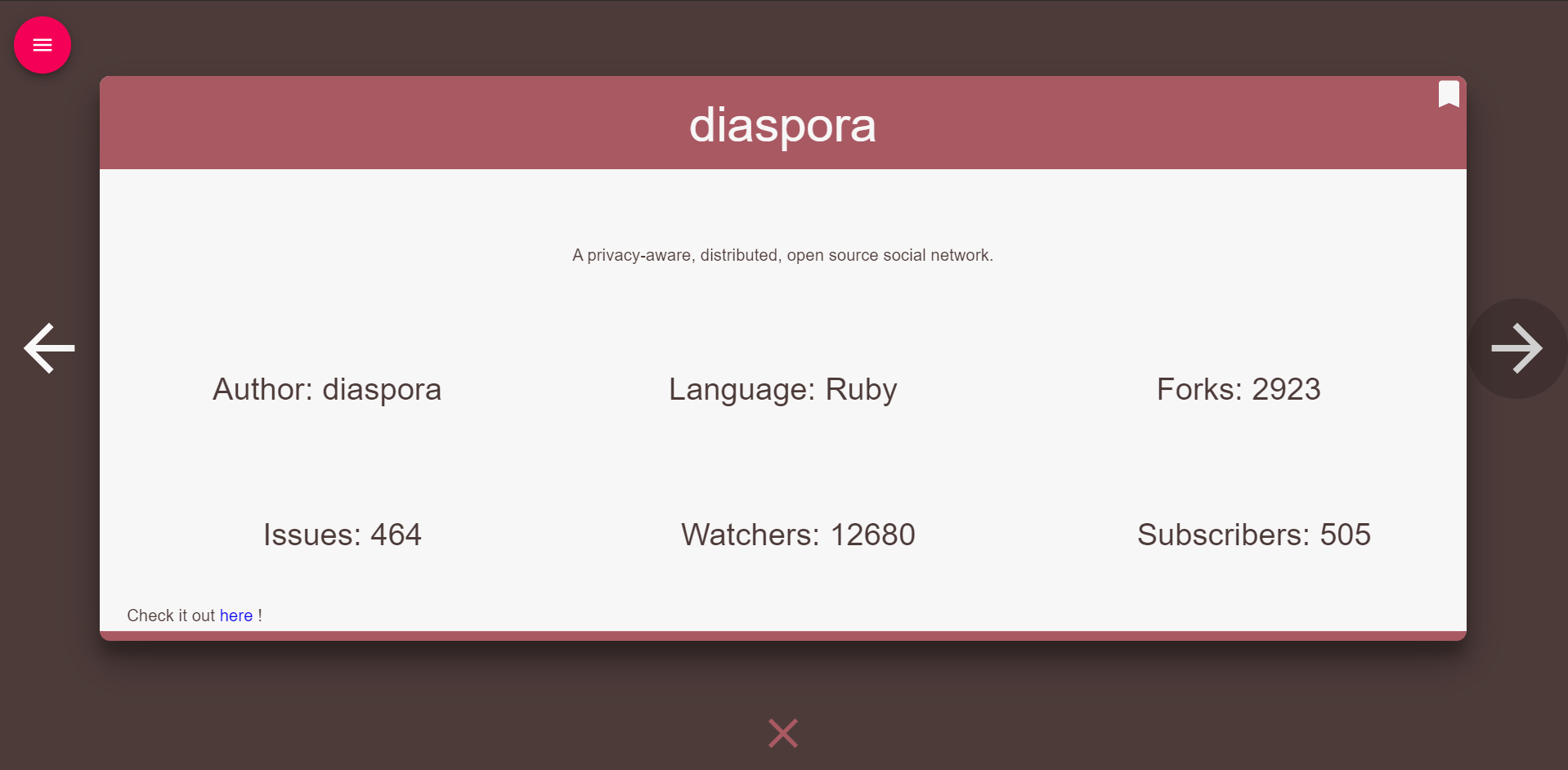
Repository Page (changes based on repo)
-
Side Navbar

Inspiration
It's no big surprise that there's a significant disparity between learning and applying concepts, yet this disparity is arguably the widest in the computer science industry. As future computer-science majors, we have heard about the importance of knowing data structures and algorithms, but not that of debugging code. While taking computer science classes, we learned about avoiding errors, but not about diving into large codebases to pinpoint the source of an error. We've created our own standalone apps (200-500 lines each), but when we undertook summer internships, we were going through thousands of lines - a scary experience, to say the least!
And this, to some extent, is the reason that many recent college graduates deal with imposter syndrome and burnout - their jobs often ask them to exhibit skills that aren't tested on in the interview, and thus these skills often are neglected. However, there's a caveat: creating code at an industrial level isn't easy. Even developing a similar app consumes a lot of time and energy - precious resources that most college-students already lack.
What it does
To solve this problem, we decided to match developers to open-source projects: while they lack the financial benefits of a job, open-source projects are equally impressive on a resume and, more importantly, develop the skills that companies require employees to possess. By compiling a list of open-source projects in an interactive format, users can use our website to find a project they are interested in and connect with it.
How we built it
We built the frontend with ReactJS and styled it with the Material UI Framework to make the navigation experience a whole lot smoother. We used Firebase as our backend to quickly authenticate users and Cloud Firestore as our database.
Challenges we ran into
Initially, our database schema would consume multiple reads at once, reaching the daily read limit within a matter of minutes. Since the database is an imperative aspect of our app (after all, you can't show users repos if you yourself don't have the repos), we spent a huge portion of time discussing potential alternatives. Eventually, we found a way to restrict reads, and we selected this method for its simplicity and effectiveness.
We also started with the initial user experience: this meant that we had an unfeasibly-long list of tasks to accomplish within 36 hours. Since we both are new to the hackathon stage, we misprioritized and started on extra (unimplemented) features instead of the minimal viable project, which meant that we had less time to create the actual project.
Accomplishments that we're proud of
Despite having a rough start, we recovered and got a minimum viable product running in under 36 hours. More importantly, we managed our time wisely and kept our commits organized by consistently branching and merging. Our UI designs were surprisingly smoother than expected, and we are particularly proud of the animations showcased on every screen.
What we learned
As beginners, one of the most important things we learned was time management: we thought that 36 hours was a lot of time, but didn't realize how fast time passes when coding! Additionally, we learned a valuable skill in GitHub: although we had some working knowledge, we learned about branching, merging, and pull requests in detail, which will undoubtedly come in useful.
In terms of learning technologies, one of the more significant things we learned was using web-scraping to populate the database: by using a backend Python script, we procured GitHub repository data and pushed it to our database.
What's next for OpenInder
Although DVhacks will end soon, OpenInder definitely won't! We would like to implement a dashboard and allow the user to save and bookmark certain repos that they would like to work on. They would be able to open these bookmarks in a dashboard with a highly detailed model giving the details of the repository and drag and drop individual bookmarks to change their order of preference.
Built With
- firebase
- firestore
- github
- javascript
- python
- react


Log in or sign up for Devpost to join the conversation.